 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGigaChat Family: Efficient Russian Language Modeling Through Mixture of Experts Architecture
Jun 11, 2025Generative large language models (LLMs) have become crucial for modern NLP research and applications across various languages. However, the development of foundational models specifically tailored to the Russian language has been limited, primarily due to the significant computational resources required. This paper introduces the GigaChat family of Russian LLMs, available in various sizes, including base models and instruction-tuned versions. We provide a detailed report on the model architecture, pre-training process, and experiments to guide design choices. In addition, we evaluate their performance on Russian and English benchmarks and compare GigaChat with multilingual analogs. The paper presents a system demonstration of the top-performing models accessible via an API, a Telegram bot, and a Web interface. Furthermore, we have released three open GigaChat models in open-source (https://huggingface.co/ai-sage), aiming to expand NLP research opportunities and support the development of industrial solutions for the Russian language.
Weight Averaging Improves Knowledge Distillation under Domain Shift
Sep 20, 2023Knowledge distillation (KD) is a powerful model compression technique broadly used in practical deep learning applications. It is focused on training a small student network to mimic a larger teacher network. While it is widely known that KD can offer an improvement to student generalization in i.i.d setting, its performance under domain shift, i.e. the performance of student networks on data from domains unseen during training, has received little attention in the literature. In this paper we make a step towards bridging the research fields of knowledge distillation and domain generalization. We show that weight averaging techniques proposed in domain generalization literature, such as SWAD and SMA, also improve the performance of knowledge distillation under domain shift. In addition, we propose a simplistic weight averaging strategy that does not require evaluation on validation data during training and show that it performs on par with SWAD and SMA when applied to KD. We name our final distillation approach Weight-Averaged Knowledge Distillation (WAKD).
Image quality prediction using synthetic and natural codebooks: comparative results
Dec 21, 2022
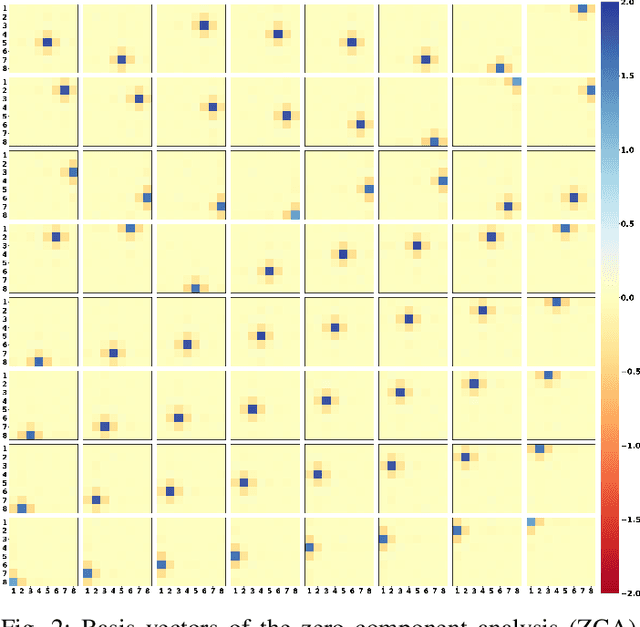
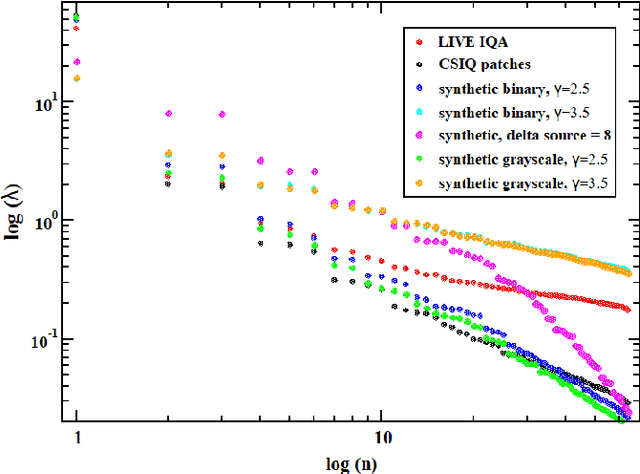
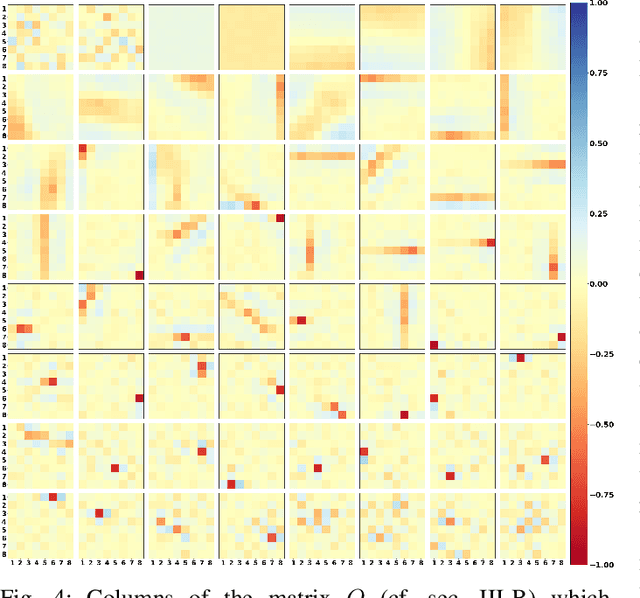
We investigate a model for image/video quality assessment based on building a set of codevectors representing in a sense some basic properties of images, similar to well-known CORNIA model. We analyze the codebook building method and propose some modifications for it. Also the algorithm is investigated from the point of inference time reduction. Both natural and synthetic images are used for building codebooks and some analysis of synthetic images used for codebooks is provided. It is demonstrated the results on quality assessment may be improves with the use if synthetic images for codebook construction. We also demonstrate regimes of the algorithm in which real time execution on CPU is possible for sufficiently high correlations with mean opinion score (MOS). Various pooling strategies are considered as well as the problem of metric sensitivity to bitrate.