 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmall Vocabularies, Big Gains: Pretraining and Tokenization in Time Series Models
Nov 06, 2025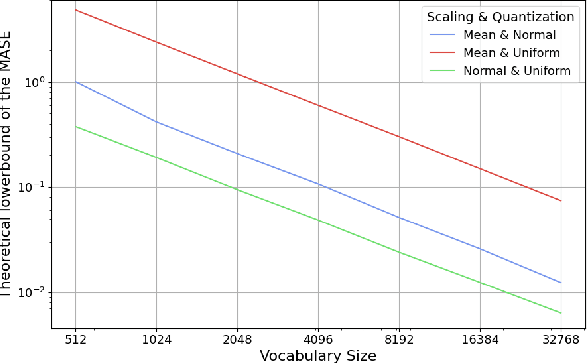
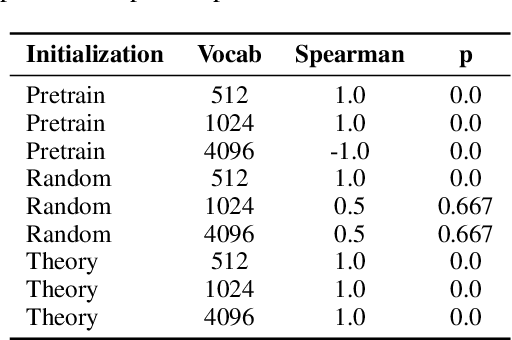
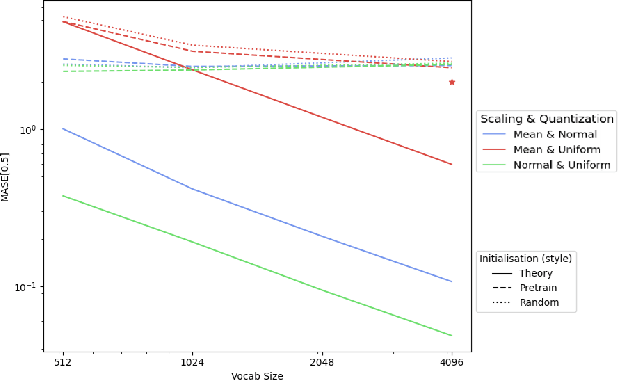
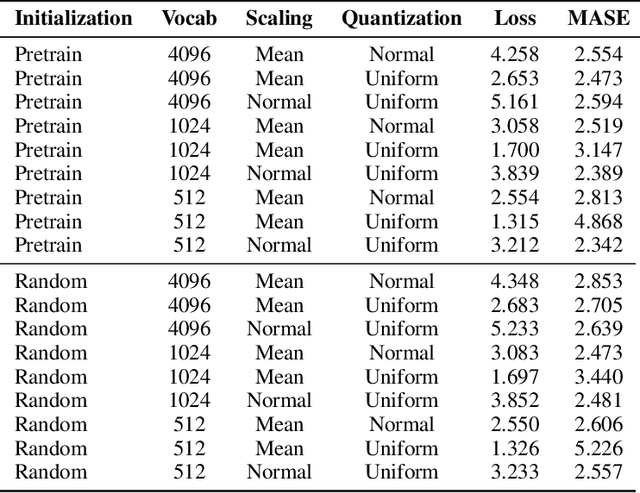
Tokenization and transfer learning are two critical components in building state of the art time series foundation models for forecasting. In this work, we systematically study the effect of tokenizer design, specifically scaling and quantization strategies, on model performance, alongside the impact of pretraining versus random initialization. We show that tokenizer configuration primarily governs the representational capacity and stability of the model, while transfer learning influences optimization efficiency and alignment. Using a combination of empirical training experiments and theoretical analyses, we demonstrate that pretrained models consistently leverage well-designed tokenizers more effectively, particularly at smaller vocabulary sizes. Conversely, misaligned tokenization can diminish or even invert the benefits of pretraining. These findings highlight the importance of careful tokenization in time series modeling and suggest that combining small, efficient vocabularies with pretrained weights is especially advantageous in multi-modal forecasting settings, where the overall vocabulary must be shared across modalities. Our results provide concrete guidance for designing tokenizers and leveraging transfer learning in discrete representation learning for continuous signals.
Accelerating Nash Learning from Human Feedback via Mirror Prox
May 26, 2025Traditional Reinforcement Learning from Human Feedback (RLHF) often relies on reward models, frequently assuming preference structures like the Bradley-Terry model, which may not accurately capture the complexities of real human preferences (e.g., intransitivity). Nash Learning from Human Feedback (NLHF) offers a more direct alternative by framing the problem as finding a Nash equilibrium of a game defined by these preferences. In this work, we introduce Nash Mirror Prox ($\mathtt{Nash-MP}$), an online NLHF algorithm that leverages the Mirror Prox optimization scheme to achieve fast and stable convergence to the Nash equilibrium. Our theoretical analysis establishes that Nash-MP exhibits last-iterate linear convergence towards the $\beta$-regularized Nash equilibrium. Specifically, we prove that the KL-divergence to the optimal policy decreases at a rate of order $(1+2\beta)^{-N/2}$, where $N$ is a number of preference queries. We further demonstrate last-iterate linear convergence for the exploitability gap and uniformly for the span semi-norm of log-probabilities, with all these rates being independent of the size of the action space. Furthermore, we propose and analyze an approximate version of Nash-MP where proximal steps are estimated using stochastic policy gradients, making the algorithm closer to applications. Finally, we detail a practical implementation strategy for fine-tuning large language models and present experiments that demonstrate its competitive performance and compatibility with existing methods.
Riemannian Manifold Learning for Stackelberg Games with Neural Flow Representations
Feb 08, 2025



We present a novel framework for online learning in Stackelberg general-sum games, where two agents, the leader and follower, engage in sequential turn-based interactions. At the core of this approach is a learned diffeomorphism that maps the joint action space to a smooth Riemannian manifold, referred to as the Stackelberg manifold. This mapping, facilitated by neural normalizing flows, ensures the formation of tractable isoplanar subspaces, enabling efficient techniques for online learning. By assuming linearity between the agents' reward functions on the Stackelberg manifold, our construct allows the application of standard bandit algorithms. We then provide a rigorous theoretical basis for regret minimization on convex manifolds and establish finite-time bounds on simple regret for learning Stackelberg equilibria. This integration of manifold learning into game theory uncovers a previously unrecognized potential for neural normalizing flows as an effective tool for multi-agent learning. We present empirical results demonstrating the effectiveness of our approach compared to standard baselines, with applications spanning domains such as cybersecurity and economic supply chain optimization.
Recurrent Interpolants for Probabilistic Time Series Prediction
Sep 18, 2024



Sequential models such as recurrent neural networks or transformer-based models became \textit{de facto} tools for multivariate time series forecasting in a probabilistic fashion, with applications to a wide range of datasets, such as finance, biology, medicine, etc. Despite their adeptness in capturing dependencies, assessing prediction uncertainty, and efficiency in training, challenges emerge in modeling high-dimensional complex distributions and cross-feature dependencies. To tackle these issues, recent works delve into generative modeling by employing diffusion or flow-based models. Notably, the integration of stochastic differential equations or probability flow successfully extends these methods to probabilistic time series imputation and forecasting. However, scalability issues necessitate a computational-friendly framework for large-scale generative model-based predictions. This work proposes a novel approach by blending the computational efficiency of recurrent neural networks with the high-quality probabilistic modeling of the diffusion model, which addresses challenges and advances generative models' application in time series forecasting. Our method relies on the foundation of stochastic interpolants and the extension to a broader conditional generation framework with additional control features, offering insights for future developments in this dynamic field.
Margin-aware Preference Optimization for Aligning Diffusion Models without Reference
Jun 10, 2024Modern alignment techniques based on human preferences, such as RLHF and DPO, typically employ divergence regularization relative to the reference model to ensure training stability. However, this often limits the flexibility of models during alignment, especially when there is a clear distributional discrepancy between the preference data and the reference model. In this paper, we focus on the alignment of recent text-to-image diffusion models, such as Stable Diffusion XL (SDXL), and find that this "reference mismatch" is indeed a significant problem in aligning these models due to the unstructured nature of visual modalities: e.g., a preference for a particular stylistic aspect can easily induce such a discrepancy. Motivated by this observation, we propose a novel and memory-friendly preference alignment method for diffusion models that does not depend on any reference model, coined margin-aware preference optimization (MaPO). MaPO jointly maximizes the likelihood margin between the preferred and dispreferred image sets and the likelihood of the preferred sets, simultaneously learning general stylistic features and preferences. For evaluation, we introduce two new pairwise preference datasets, which comprise self-generated image pairs from SDXL, Pick-Style and Pick-Safety, simulating diverse scenarios of reference mismatch. Our experiments validate that MaPO can significantly improve alignment on Pick-Style and Pick-Safety and general preference alignment when used with Pick-a-Pic v2, surpassing the base SDXL and other existing methods. Our code, models, and datasets are publicly available via https://mapo-t2i.github.io
Forecasting with Hyper-Trees
May 17, 2024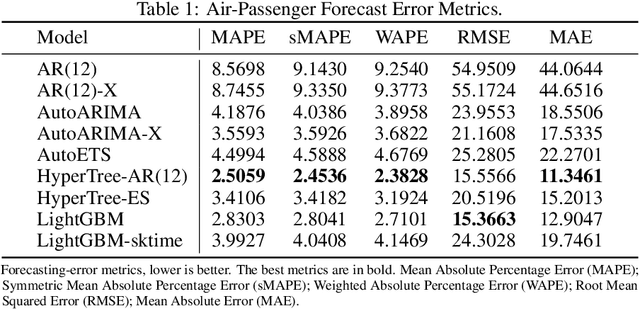
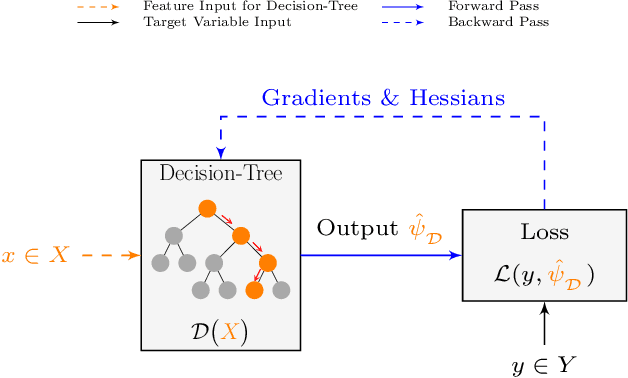


This paper introduces the concept of Hyper-Trees and offers a new direction in applying tree-based models to time series data. Unlike conventional applications of decision trees that forecast time series directly, Hyper-Trees are designed to learn the parameters of a target time series model. Our framework leverages the gradient-based nature of boosted trees, which allows us to extend the concept of Hyper-Networks to Hyper-Trees and to induce a time-series inductive bias to tree models. By relating the parameters of a target time series model to features, Hyper-Trees address the issue of parameter non-stationarity and enable tree-based forecasts to extend beyond their training range. With our research, we aim to explore the effectiveness of Hyper-Trees across various forecasting scenarios and to extend the application of gradient boosted decision trees outside their conventional use in time series modeling.
Deep Generative Sampling in the Dual Divergence Space: A Data-efficient & Interpretative Approach for Generative AI
Apr 10, 2024



Building on the remarkable achievements in generative sampling of natural images, we propose an innovative challenge, potentially overly ambitious, which involves generating samples of entire multivariate time series that resemble images. However, the statistical challenge lies in the small sample size, sometimes consisting of a few hundred subjects. This issue is especially problematic for deep generative models that follow the conventional approach of generating samples from a canonical distribution and then decoding or denoising them to match the true data distribution. In contrast, our method is grounded in information theory and aims to implicitly characterize the distribution of images, particularly the (global and local) dependency structure between pixels. We achieve this by empirically estimating its KL-divergence in the dual form with respect to the respective marginal distribution. This enables us to perform generative sampling directly in the optimized 1-D dual divergence space. Specifically, in the dual space, training samples representing the data distribution are embedded in the form of various clusters between two end points. In theory, any sample embedded between those two end points is in-distribution w.r.t. the data distribution. Our key idea for generating novel samples of images is to interpolate between the clusters via a walk as per gradients of the dual function w.r.t. the data dimensions. In addition to the data efficiency gained from direct sampling, we propose an algorithm that offers a significant reduction in sample complexity for estimating the divergence of the data distribution with respect to the marginal distribution. We provide strong theoretical guarantees along with an extensive empirical evaluation using many real-world datasets from diverse domains, establishing the superiority of our approach w.r.t. state-of-the-art deep learning methods.
The N+ Implementation Details of RLHF with PPO: A Case Study on TL;DR Summarization
Mar 24, 2024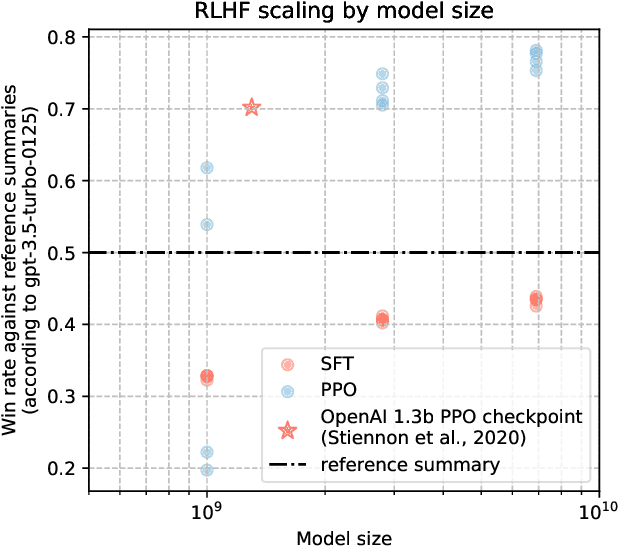
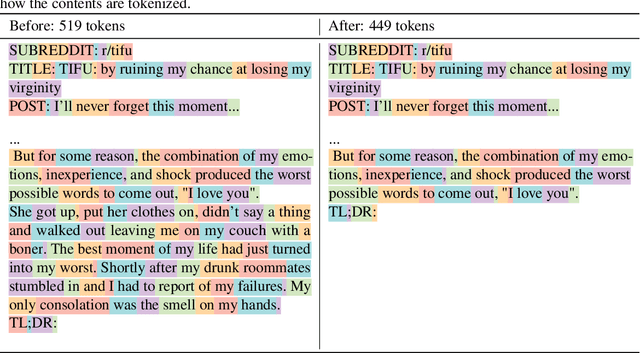
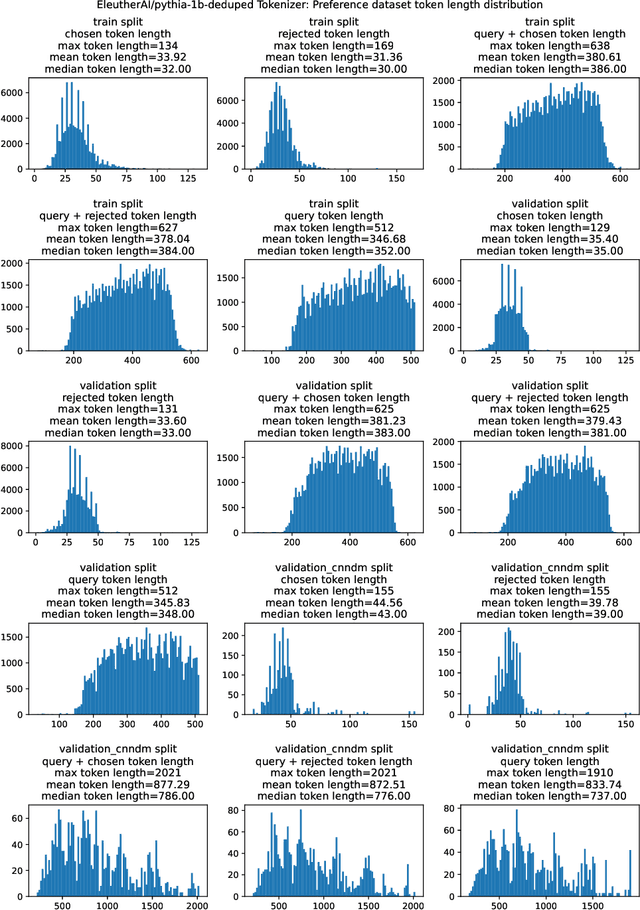

This work is the first to openly reproduce the Reinforcement Learning from Human Feedback (RLHF) scaling behaviors reported in OpenAI's seminal TL;DR summarization work. We create an RLHF pipeline from scratch, enumerate over 20 key implementation details, and share key insights during the reproduction. Our RLHF-trained Pythia models demonstrate significant gains in response quality that scale with model size, with our 2.8B, 6.9B models outperforming OpenAI's released 1.3B checkpoint. We publicly release the trained model checkpoints and code to facilitate further research and accelerate progress in the field (\url{https://github.com/vwxyzjn/summarize_from_feedback_details}).
Structural Knowledge Informed Continual Multivariate Time Series Forecasting
Feb 20, 2024



Recent studies in multivariate time series (MTS) forecasting reveal that explicitly modeling the hidden dependencies among different time series can yield promising forecasting performance and reliable explanations. However, modeling variable dependencies remains underexplored when MTS is continuously accumulated under different regimes (stages). Due to the potential distribution and dependency disparities, the underlying model may encounter the catastrophic forgetting problem, i.e., it is challenging to memorize and infer different types of variable dependencies across different regimes while maintaining forecasting performance. To address this issue, we propose a novel Structural Knowledge Informed Continual Learning (SKI-CL) framework to perform MTS forecasting within a continual learning paradigm, which leverages structural knowledge to steer the forecasting model toward identifying and adapting to different regimes, and selects representative MTS samples from each regime for memory replay. Specifically, we develop a forecasting model based on graph structure learning, where a consistency regularization scheme is imposed between the learned variable dependencies and the structural knowledge while optimizing the forecasting objective over the MTS data. As such, MTS representations learned in each regime are associated with distinct structural knowledge, which helps the model memorize a variety of conceivable scenarios and results in accurate forecasts in the continual learning context. Meanwhile, we develop a representation-matching memory replay scheme that maximizes the temporal coverage of MTS data to efficiently preserve the underlying temporal dynamics and dependency structures of each regime. Thorough empirical studies on synthetic and real-world benchmarks validate SKI-CL's efficacy and advantages over the state-of-the-art for continual MTS forecasting tasks.
Zephyr: Direct Distillation of LM Alignment
Oct 25, 2023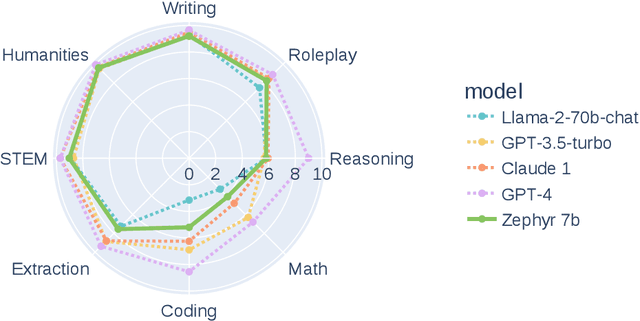
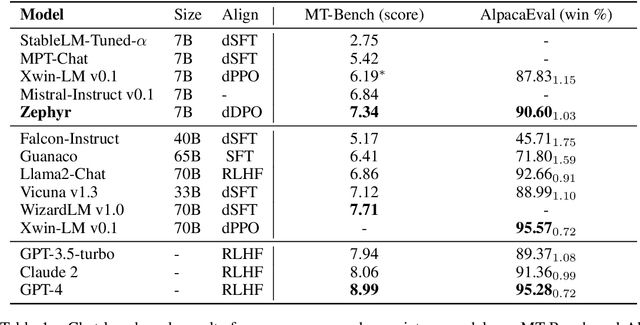
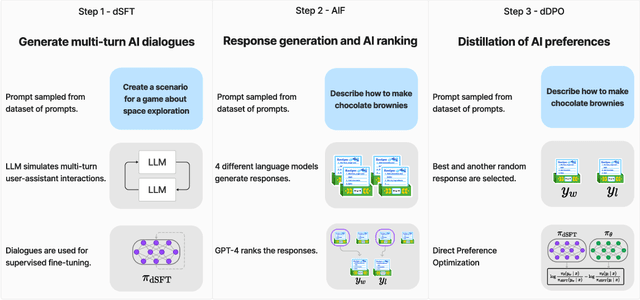
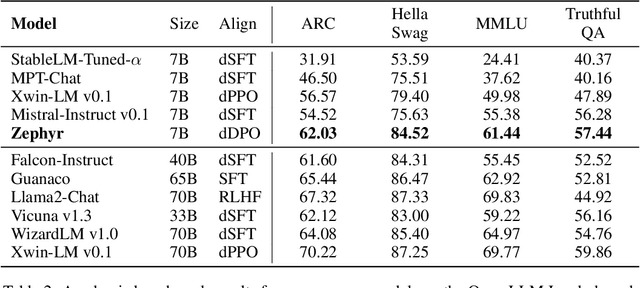
We aim to produce a smaller language model that is aligned to user intent. Previous research has shown that applying distilled supervised fine-tuning (dSFT) on larger models significantly improves task accuracy; however, these models are unaligned, i.e. they do not respond well to natural prompts. To distill this property, we experiment with the use of preference data from AI Feedback (AIF). Starting from a dataset of outputs ranked by a teacher model, we apply distilled direct preference optimization (dDPO) to learn a chat model with significantly improved intent alignment. The approach requires only a few hours of training without any additional sampling during fine-tuning. The final result, Zephyr-7B, sets the state-of-the-art on chat benchmarks for 7B parameter models, and requires no human annotation. In particular, results on MT-Bench show that Zephyr-7B surpasses Llama2-Chat-70B, the best open-access RLHF-based model. Code, models, data, and tutorials for the system are available at https://github.com/huggingface/alignment-handbook.