 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEarly GVHD Prediction in Liver Transplantation via Multi-Modal Deep Learning on Imbalanced EHR Data
Nov 06, 2025Graft-versus-host disease (GVHD) is a rare but often fatal complication in liver transplantation, with a very high mortality rate. By harnessing multi-modal deep learning methods to integrate heterogeneous and imbalanced electronic health records (EHR), we aim to advance early prediction of GVHD, paving the way for timely intervention and improved patient outcomes. In this study, we analyzed pre-transplant electronic health records (EHR) spanning the period before surgery for 2,100 liver transplantation patients, including 42 cases of graft-versus-host disease (GVHD), from a cohort treated at Mayo Clinic between 1992 and 2025. The dataset comprised four major modalities: patient demographics, laboratory tests, diagnoses, and medications. We developed a multi-modal deep learning framework that dynamically fuses these modalities, handles irregular records with missing values, and addresses extreme class imbalance through AUC-based optimization. The developed framework outperforms all single-modal and multi-modal machine learning baselines, achieving an AUC of 0.836, an AUPRC of 0.157, a recall of 0.768, and a specificity of 0.803. It also demonstrates the effectiveness of our approach in capturing complementary information from different modalities, leading to improved performance. Our multi-modal deep learning framework substantially improves existing approaches for early GVHD prediction. By effectively addressing the challenges of heterogeneity and extreme class imbalance in real-world EHR, it achieves accurate early prediction. Our proposed multi-modal deep learning method demonstrates promising results for early prediction of a GVHD in liver transplantation, despite the challenge of extremely imbalanced EHR data.
Multi-modal Time Series Analysis: A Tutorial and Survey
Mar 17, 2025Multi-modal time series analysis has recently emerged as a prominent research area in data mining, driven by the increasing availability of diverse data modalities, such as text, images, and structured tabular data from real-world sources. However, effective analysis of multi-modal time series is hindered by data heterogeneity, modality gap, misalignment, and inherent noise. Recent advancements in multi-modal time series methods have exploited the multi-modal context via cross-modal interactions based on deep learning methods, significantly enhancing various downstream tasks. In this tutorial and survey, we present a systematic and up-to-date overview of multi-modal time series datasets and methods. We first state the existing challenges of multi-modal time series analysis and our motivations, with a brief introduction of preliminaries. Then, we summarize the general pipeline and categorize existing methods through a unified cross-modal interaction framework encompassing fusion, alignment, and transference at different levels (\textit{i.e.}, input, intermediate, output), where key concepts and ideas are highlighted. We also discuss the real-world applications of multi-modal analysis for both standard and spatial time series, tailored to general and specific domains. Finally, we discuss future research directions to help practitioners explore and exploit multi-modal time series. The up-to-date resources are provided in the GitHub repository: https://github.com/UConn-DSIS/Multi-modal-Time-Series-Analysis
Explainable Multi-modal Time Series Prediction with LLM-in-the-Loop
Mar 02, 2025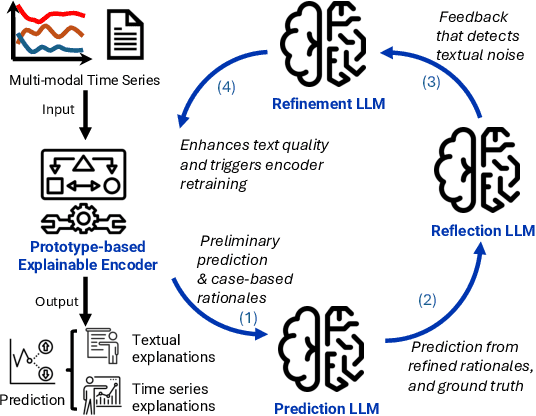

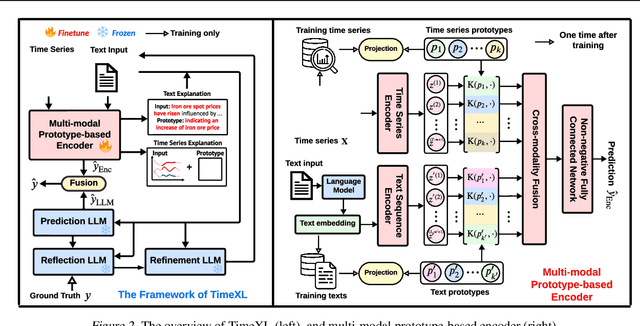
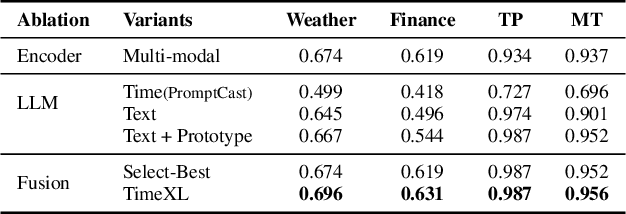
Time series analysis provides essential insights for real-world system dynamics and informs downstream decision-making, yet most existing methods often overlook the rich contextual signals present in auxiliary modalities. To bridge this gap, we introduce TimeXL, a multi-modal prediction framework that integrates a prototype-based time series encoder with three collaborating Large Language Models (LLMs) to deliver more accurate predictions and interpretable explanations. First, a multi-modal prototype-based encoder processes both time series and textual inputs to generate preliminary forecasts alongside case-based rationales. These outputs then feed into a prediction LLM, which refines the forecasts by reasoning over the encoder's predictions and explanations. Next, a reflection LLM compares the predicted values against the ground truth, identifying textual inconsistencies or noise. Guided by this feedback, a refinement LLM iteratively enhances text quality and triggers encoder retraining. This closed-loop workflow -- prediction, critique (reflect), and refinement -- continuously boosts the framework's performance and interpretability. Empirical evaluations on four real-world datasets demonstrate that TimeXL achieves up to 8.9\% improvement in AUC and produces human-centric, multi-modal explanations, highlighting the power of LLM-driven reasoning for time series prediction.
Learning System Dynamics without Forgetting
Jun 30, 2024



Predicting the trajectories of systems with unknown dynamics (\textit{i.e.} the governing rules) is crucial in various research fields, including physics and biology. This challenge has gathered significant attention from diverse communities. Most existing works focus on learning fixed system dynamics within one single system. However, real-world applications often involve multiple systems with different types of dynamics or evolving systems with non-stationary dynamics (dynamics shifts). When data from those systems are continuously collected and sequentially fed to machine learning models for training, these models tend to be biased toward the most recently learned dynamics, leading to catastrophic forgetting of previously observed/learned system dynamics. To this end, we aim to learn system dynamics via continual learning. Specifically, we present a novel framework of Mode-switching Graph ODE (MS-GODE), which can continually learn varying dynamics and encode the system-specific dynamics into binary masks over the model parameters. During the inference stage, the model can select the most confident mask based on the observational data to identify the system and predict future trajectories accordingly. Empirically, we systematically investigate the task configurations and compare the proposed MS-GODE with state-of-the-art techniques. More importantly, we construct a novel benchmark of biological dynamic systems, featuring diverse systems with disparate dynamics and significantly enriching the research field of machine learning for dynamic systems.
Foundation Models for Time Series Analysis: A Tutorial and Survey
Mar 21, 2024Time series analysis stands as a focal point within the data mining community, serving as a cornerstone for extracting valuable insights crucial to a myriad of real-world applications. Recent advancements in Foundation Models (FMs) have fundamentally reshaped the paradigm of model design for time series analysis, boosting various downstream tasks in practice. These innovative approaches often leverage pre-trained or fine-tuned FMs to harness generalized knowledge tailored specifically for time series analysis. In this survey, we aim to furnish a comprehensive and up-to-date overview of FMs for time series analysis. While prior surveys have predominantly focused on either the application or the pipeline aspects of FMs in time series analysis, they have often lacked an in-depth understanding of the underlying mechanisms that elucidate why and how FMs benefit time series analysis. To address this gap, our survey adopts a model-centric classification, delineating various pivotal elements of time-series FMs, including model architectures, pre-training techniques, adaptation methods, and data modalities. Overall, this survey serves to consolidate the latest advancements in FMs pertinent to time series analysis, accentuating their theoretical underpinnings, recent strides in development, and avenues for future research exploration.
$\textbf{S}^2$IP-LLM: Semantic Space Informed Prompt Learning with LLM for Time Series Forecasting
Mar 09, 2024



Recently, there has been a growing interest in leveraging pre-trained large language models (LLMs) for various time series applications. However, the semantic space of LLMs, established through the pre-training, is still underexplored and may help yield more distinctive and informative representations to facilitate time series forecasting. To this end, we propose Semantic Space Informed Prompt learning with LLM ($S^2$IP-LLM) to align the pre-trained semantic space with time series embeddings space and perform time series forecasting based on learned prompts from the joint space. We first design a tokenization module tailored for cross-modality alignment, which explicitly concatenates patches of decomposed time series components to create embeddings that effectively encode the temporal dynamics. Next, we leverage the pre-trained word token embeddings to derive semantic anchors and align selected anchors with time series embeddings by maximizing the cosine similarity in the joint space. This way, $S^2$IP-LLM can retrieve relevant semantic anchors as prompts to provide strong indicators (context) for time series that exhibit different temporal dynamics. With thorough empirical studies on multiple benchmark datasets, we demonstrate that the proposed $S^2$IP-LLM can achieve superior forecasting performance over state-of-the-art baselines. Furthermore, our ablation studies and visualizations verify the necessity of prompt learning informed by semantic space.
Structural Knowledge Informed Continual Multivariate Time Series Forecasting
Feb 20, 2024



Recent studies in multivariate time series (MTS) forecasting reveal that explicitly modeling the hidden dependencies among different time series can yield promising forecasting performance and reliable explanations. However, modeling variable dependencies remains underexplored when MTS is continuously accumulated under different regimes (stages). Due to the potential distribution and dependency disparities, the underlying model may encounter the catastrophic forgetting problem, i.e., it is challenging to memorize and infer different types of variable dependencies across different regimes while maintaining forecasting performance. To address this issue, we propose a novel Structural Knowledge Informed Continual Learning (SKI-CL) framework to perform MTS forecasting within a continual learning paradigm, which leverages structural knowledge to steer the forecasting model toward identifying and adapting to different regimes, and selects representative MTS samples from each regime for memory replay. Specifically, we develop a forecasting model based on graph structure learning, where a consistency regularization scheme is imposed between the learned variable dependencies and the structural knowledge while optimizing the forecasting objective over the MTS data. As such, MTS representations learned in each regime are associated with distinct structural knowledge, which helps the model memorize a variety of conceivable scenarios and results in accurate forecasts in the continual learning context. Meanwhile, we develop a representation-matching memory replay scheme that maximizes the temporal coverage of MTS data to efficiently preserve the underlying temporal dynamics and dependency structures of each regime. Thorough empirical studies on synthetic and real-world benchmarks validate SKI-CL's efficacy and advantages over the state-of-the-art for continual MTS forecasting tasks.
Empowering Time Series Analysis with Large Language Models: A Survey
Feb 05, 2024Recently, remarkable progress has been made over large language models (LLMs), demonstrating their unprecedented capability in varieties of natural language tasks. However, completely training a large general-purpose model from the scratch is challenging for time series analysis, due to the large volumes and varieties of time series data, as well as the non-stationarity that leads to concept drift impeding continuous model adaptation and re-training. Recent advances have shown that pre-trained LLMs can be exploited to capture complex dependencies in time series data and facilitate various applications. In this survey, we provide a systematic overview of existing methods that leverage LLMs for time series analysis. Specifically, we first state the challenges and motivations of applying language models in the context of time series as well as brief preliminaries of LLMs. Next, we summarize the general pipeline for LLM-based time series analysis, categorize existing methods into different groups (i.e., direct query, tokenization, prompt design, fine-tune, and model integration), and highlight the key ideas within each group. We also discuss the applications of LLMs for both general and spatial-temporal time series data, tailored to specific domains. Finally, we thoroughly discuss future research opportunities to empower time series analysis with LLMs.
Federated Variational Learning for Anomaly Detection in Multivariate Time Series
Aug 29, 2021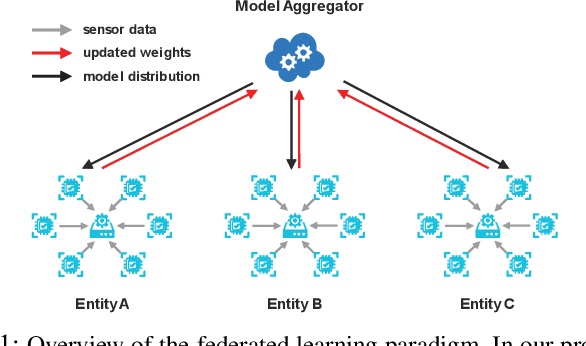
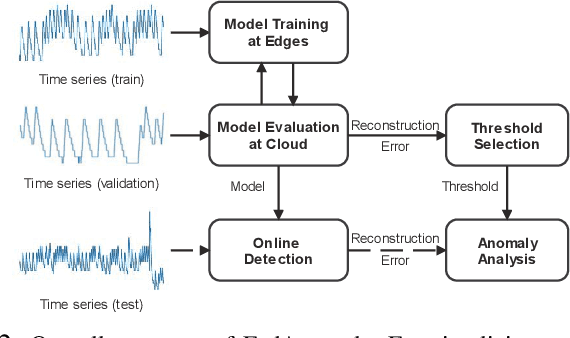
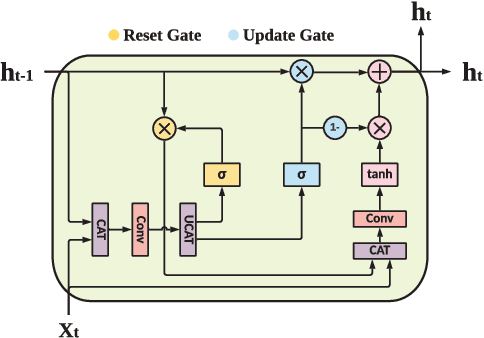
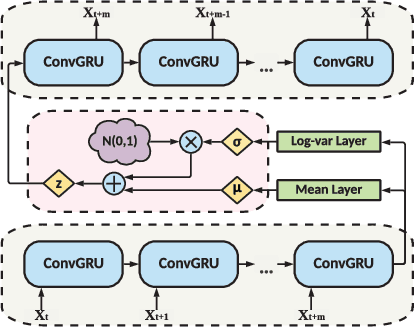
Anomaly detection has been a challenging task given high-dimensional multivariate time series data generated by networked sensors and actuators in Cyber-Physical Systems (CPS). Besides the highly nonlinear, complex, and dynamic natures of such time series, the lack of labeled data impedes data exploitation in a supervised manner and thus prevents an accurate detection of abnormal phenomenons. On the other hand, the collected data at the edge of the network is often privacy sensitive and large in quantity, which may hinder the centralized training at the main server. To tackle these issues, we propose an unsupervised time series anomaly detection framework in a federated fashion to continuously monitor the behaviors of interconnected devices within a network and alerts for abnormal incidents so that countermeasures can be taken before undesired consequences occur. To be specific, we leave the training data distributed at the edge to learn a shared Variational Autoencoder (VAE) based on Convolutional Gated Recurrent Unit (ConvGRU) model, which jointly captures feature and temporal dependencies in the multivariate time series data for representation learning and downstream anomaly detection tasks. Experiments on three real-world networked sensor datasets illustrate the advantage of our approach over other state-of-the-art models. We also conduct extensive experiments to demonstrate the effectiveness of our detection framework under non-federated and federated settings in terms of overall performance and detection latency.
Learning to Detect: A Data-driven Approach for Network Intrusion Detection
Aug 18, 2021
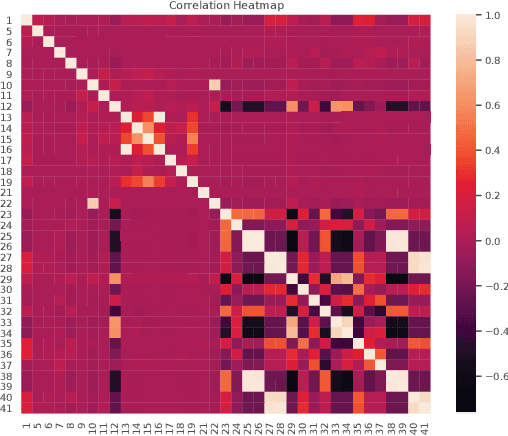
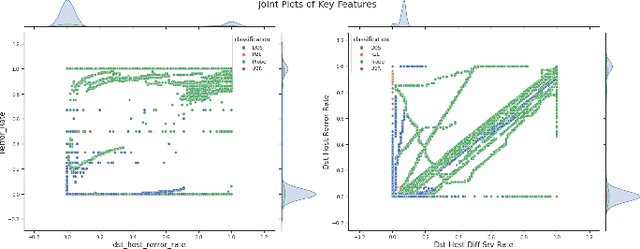
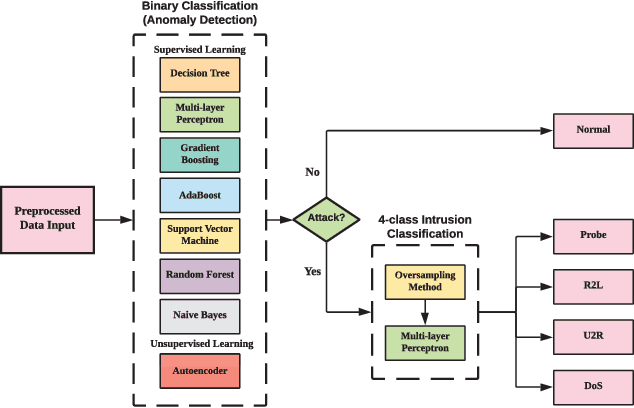
With massive data being generated daily and the ever-increasing interconnectivity of the world's Internet infrastructures, a machine learning based intrusion detection system (IDS) has become a vital component to protect our economic and national security. In this paper, we perform a comprehensive study on NSL-KDD, a network traffic dataset, by visualizing patterns and employing different learning-based models to detect cyber attacks. Unlike previous shallow learning and deep learning models that use the single learning model approach for intrusion detection, we adopt a hierarchy strategy, in which the intrusion and normal behavior are classified firstly, and then the specific types of attacks are classified. We demonstrate the advantage of the unsupervised representation learning model in binary intrusion detection tasks. Besides, we alleviate the data imbalance problem with SVM-SMOTE oversampling technique in 4-class classification and further demonstrate the effectiveness and the drawback of the oversampling mechanism with a deep neural network as a base model.