 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpowering Power Outage Prediction with Spatially Aware Hybrid Graph Neural Networks and Contrastive Learning
Apr 06, 2026Extreme weather events, such as severe storms, hurricanes, snowstorms, and ice storms, which are exacerbated by climate change, frequently cause widespread power outages. These outages halt industrial operations, impact communities, damage critical infrastructure, profoundly disrupt economies, and have far-reaching effects across various sectors. To mitigate these effects, the University of Connecticut and Eversource Energy Center have developed an outage prediction modeling (OPM) system to provide pre-emptive forecasts for electric distribution networks before such weather events occur. However, existing predictive models in the system do not incorporate the spatial effect of extreme weather events. To this end, we develop Spatially Aware Hybrid Graph Neural Networks (SA-HGNN) with contrastive learning to enhance the OPM predictions for extreme weather-induced power outages. Specifically, we first encode spatial relationships of both static features (e.g., land cover, infrastructure) and event-specific dynamic features (e.g., wind speed, precipitation) via Spatially Aware Hybrid Graph Neural Networks (SA-HGNN). Next, we leverage contrastive learning to handle the imbalance problem associated with different types of extreme weather events and generate location-specific embeddings by minimizing intra-event distances between similar locations while maximizing inter-event distances across all locations. Thorough empirical studies in four utility service territories, i.e., Connecticut, Western Massachusetts, Eastern Massachusetts, and New Hampshire, demonstrate that SA-HGNN can achieve state-of-the-art performance for power outage prediction.
Ada-RS: Adaptive Rejection Sampling for Selective Thinking
Feb 23, 2026Large language models (LLMs) are increasingly being deployed in cost and latency-sensitive settings. While chain-of-thought improves reasoning, it can waste tokens on simple requests. We study selective thinking for tool-using LLMs and introduce Adaptive Rejection Sampling (Ada-RS), an algorithm-agnostic sample filtering framework for learning selective and efficient reasoning. For each given context, Ada-RS scores multiple sampled completions with an adaptive length-penalized reward then applies stochastic rejection sampling to retain only high-reward candidates (or preference pairs) for downstream optimization. We demonstrate how Ada-RS plugs into both preference pair (e.g. DPO) or grouped policy optimization strategies (e.g. DAPO). Using Qwen3-8B with LoRA on a synthetic tool call-oriented e-commerce benchmark, Ada-RS improves the accuracy-efficiency frontier over standard algorithms by reducing average output tokens by up to 80% and reducing thinking rate by up to 95% while maintaining or improving tool call accuracy. These results highlight that training-signal selection is a powerful lever for efficient reasoning in latency-sensitive deployments.
Toward Scalable Verifiable Reward: Proxy State-Based Evaluation for Multi-turn Tool-Calling LLM Agents
Feb 18, 2026Interactive large language model (LLM) agents operating via multi-turn dialogue and multi-step tool calling are increasingly used in production. Benchmarks for these agents must both reliably compare models and yield on-policy training data. Prior agentic benchmarks (e.g., tau-bench, tau2-bench, AppWorld) rely on fully deterministic backends, which are costly to build and iterate. We propose Proxy State-Based Evaluation, an LLM-driven simulation framework that preserves final state-based evaluation without a deterministic database. Specifically, a scenario specifies the user goal, user/system facts, expected final state, and expected agent behavior, and an LLM state tracker infers a structured proxy state from the full interaction trace. LLM judges then verify goal completion and detect tool/user hallucinations against scenario constraints. Empirically, our benchmark produces stable, model-differentiating rankings across families and inference-time reasoning efforts, and its on-/off-policy rollouts provide supervision that transfers to unseen scenarios. Careful scenario specification yields near-zero simulator hallucination rates as supported by ablation studies. The framework also supports sensitivity analyses over user personas. Human-LLM judge agreement exceeds 90%, indicating reliable automated evaluation. Overall, proxy state-based evaluation offers a practical, scalable alternative to deterministic agentic benchmarks for industrial LLM agents.
Multi-modal Time Series Analysis: A Tutorial and Survey
Mar 17, 2025Multi-modal time series analysis has recently emerged as a prominent research area in data mining, driven by the increasing availability of diverse data modalities, such as text, images, and structured tabular data from real-world sources. However, effective analysis of multi-modal time series is hindered by data heterogeneity, modality gap, misalignment, and inherent noise. Recent advancements in multi-modal time series methods have exploited the multi-modal context via cross-modal interactions based on deep learning methods, significantly enhancing various downstream tasks. In this tutorial and survey, we present a systematic and up-to-date overview of multi-modal time series datasets and methods. We first state the existing challenges of multi-modal time series analysis and our motivations, with a brief introduction of preliminaries. Then, we summarize the general pipeline and categorize existing methods through a unified cross-modal interaction framework encompassing fusion, alignment, and transference at different levels (\textit{i.e.}, input, intermediate, output), where key concepts and ideas are highlighted. We also discuss the real-world applications of multi-modal analysis for both standard and spatial time series, tailored to general and specific domains. Finally, we discuss future research directions to help practitioners explore and exploit multi-modal time series. The up-to-date resources are provided in the GitHub repository: https://github.com/UConn-DSIS/Multi-modal-Time-Series-Analysis
4D Gaussian Splatting: Modeling Dynamic Scenes with Native 4D Primitives
Dec 30, 2024



Dynamic 3D scene representation and novel view synthesis from captured videos are crucial for enabling immersive experiences required by AR/VR and metaverse applications. However, this task is challenging due to the complexity of unconstrained real-world scenes and their temporal dynamics. In this paper, we frame dynamic scenes as a spatio-temporal 4D volume learning problem, offering a native explicit reformulation with minimal assumptions about motion, which serves as a versatile dynamic scene learning framework. Specifically, we represent a target dynamic scene using a collection of 4D Gaussian primitives with explicit geometry and appearance features, dubbed as 4D Gaussian splatting (4DGS). This approach can capture relevant information in space and time by fitting the underlying spatio-temporal volume. Modeling the spacetime as a whole with 4D Gaussians parameterized by anisotropic ellipses that can rotate arbitrarily in space and time, our model can naturally learn view-dependent and time-evolved appearance with 4D spherindrical harmonics. Notably, our 4DGS model is the first solution that supports real-time rendering of high-resolution, photorealistic novel views for complex dynamic scenes. To enhance efficiency, we derive several compact variants that effectively reduce memory footprint and mitigate the risk of overfitting. Extensive experiments validate the superiority of 4DGS in terms of visual quality and efficiency across a range of dynamic scene-related tasks (e.g., novel view synthesis, 4D generation, scene understanding) and scenarios (e.g., single object, indoor scenes, driving environments, synthetic and real data).
Driving Scene Synthesis on Free-form Trajectories with Generative Prior
Dec 02, 2024

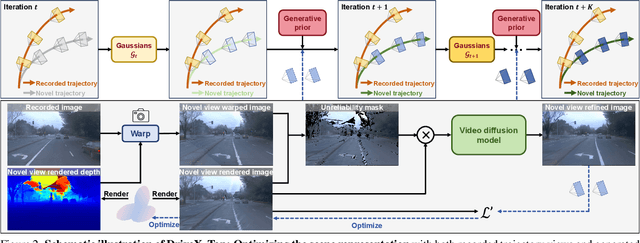

Driving scene synthesis along free-form trajectories is essential for driving simulations to enable closed-loop evaluation of end-to-end driving policies. While existing methods excel at novel view synthesis on recorded trajectories, they face challenges with novel trajectories due to limited views of driving videos and the vastness of driving environments. To tackle this challenge, we propose a novel free-form driving view synthesis approach, dubbed DriveX, by leveraging video generative prior to optimize a 3D model across a variety of trajectories. Concretely, we crafted an inverse problem that enables a video diffusion model to be utilized as a prior for many-trajectory optimization of a parametric 3D model (e.g., Gaussian splatting). To seamlessly use the generative prior, we iteratively conduct this process during optimization. Our resulting model can produce high-fidelity virtual driving environments outside the recorded trajectory, enabling free-form trajectory driving simulation. Beyond real driving scenes, DriveX can also be utilized to simulate virtual driving worlds from AI-generated videos.
Tetrahedron Splatting for 3D Generation
Jun 03, 2024



3D representation is essential to the significant advance of 3D generation with 2D diffusion priors. As a flexible representation, NeRF has been first adopted for 3D representation. With density-based volumetric rendering, it however suffers both intensive computational overhead and inaccurate mesh extraction. Using a signed distance field and Marching Tetrahedra, DMTet allows for precise mesh extraction and real-time rendering but is limited in handling large topological changes in meshes, leading to optimization challenges. Alternatively, 3D Gaussian Splatting (3DGS) is favored in both training and rendering efficiency while falling short in mesh extraction. In this work, we introduce a novel 3D representation, Tetrahedron Splatting (TeT-Splatting), that supports easy convergence during optimization, precise mesh extraction, and real-time rendering simultaneously. This is achieved by integrating surface-based volumetric rendering within a structured tetrahedral grid while preserving the desired ability of precise mesh extraction, and a tile-based differentiable tetrahedron rasterizer. Furthermore, we incorporate eikonal and normal consistency regularization terms for the signed distance field to improve generation quality and stability. Critically, our representation can be trained without mesh extraction, making the optimization process easier to converge. Our TeT-Splatting can be readily integrated in existing 3D generation pipelines, along with polygonal mesh for texture optimization. Extensive experiments show that our TeT-Splatting strikes a superior tradeoff among convergence speed, render efficiency, and mesh quality as compared to previous alternatives under varying 3D generation settings.
Diffusion$^2$: Dynamic 3D Content Generation via Score Composition of Orthogonal Diffusion Models
Apr 02, 2024



Recent advancements in 3D generation are predominantly propelled by improvements in 3D-aware image diffusion models which are pretrained on Internet-scale image data and fine-tuned on massive 3D data, offering the capability of producing highly consistent multi-view images. However, due to the scarcity of synchronized multi-view video data, it is impractical to adapt this paradigm to 4D generation directly. Despite that, the available video and 3D data are adequate for training video and multi-view diffusion models that can provide satisfactory dynamic and geometric priors respectively. In this paper, we present Diffusion$^2$, a novel framework for dynamic 3D content creation that leverages the knowledge about geometric consistency and temporal smoothness from these models to directly sample dense multi-view and multi-frame images which can be employed to optimize continuous 4D representation. Specifically, we design a simple yet effective denoising strategy via score composition of video and multi-view diffusion models based on the probability structure of the images to be generated. Owing to the high parallelism of the image generation and the efficiency of the modern 4D reconstruction pipeline, our framework can generate 4D content within few minutes. Furthermore, our method circumvents the reliance on 4D data, thereby having the potential to benefit from the scalability of the foundation video and multi-view diffusion models. Extensive experiments demonstrate the efficacy of our proposed framework and its capability to flexibly adapt to various types of prompts.
$\textbf{S}^2$IP-LLM: Semantic Space Informed Prompt Learning with LLM for Time Series Forecasting
Mar 09, 2024



Recently, there has been a growing interest in leveraging pre-trained large language models (LLMs) for various time series applications. However, the semantic space of LLMs, established through the pre-training, is still underexplored and may help yield more distinctive and informative representations to facilitate time series forecasting. To this end, we propose Semantic Space Informed Prompt learning with LLM ($S^2$IP-LLM) to align the pre-trained semantic space with time series embeddings space and perform time series forecasting based on learned prompts from the joint space. We first design a tokenization module tailored for cross-modality alignment, which explicitly concatenates patches of decomposed time series components to create embeddings that effectively encode the temporal dynamics. Next, we leverage the pre-trained word token embeddings to derive semantic anchors and align selected anchors with time series embeddings by maximizing the cosine similarity in the joint space. This way, $S^2$IP-LLM can retrieve relevant semantic anchors as prompts to provide strong indicators (context) for time series that exhibit different temporal dynamics. With thorough empirical studies on multiple benchmark datasets, we demonstrate that the proposed $S^2$IP-LLM can achieve superior forecasting performance over state-of-the-art baselines. Furthermore, our ablation studies and visualizations verify the necessity of prompt learning informed by semantic space.
Structural Knowledge Informed Continual Multivariate Time Series Forecasting
Feb 20, 2024



Recent studies in multivariate time series (MTS) forecasting reveal that explicitly modeling the hidden dependencies among different time series can yield promising forecasting performance and reliable explanations. However, modeling variable dependencies remains underexplored when MTS is continuously accumulated under different regimes (stages). Due to the potential distribution and dependency disparities, the underlying model may encounter the catastrophic forgetting problem, i.e., it is challenging to memorize and infer different types of variable dependencies across different regimes while maintaining forecasting performance. To address this issue, we propose a novel Structural Knowledge Informed Continual Learning (SKI-CL) framework to perform MTS forecasting within a continual learning paradigm, which leverages structural knowledge to steer the forecasting model toward identifying and adapting to different regimes, and selects representative MTS samples from each regime for memory replay. Specifically, we develop a forecasting model based on graph structure learning, where a consistency regularization scheme is imposed between the learned variable dependencies and the structural knowledge while optimizing the forecasting objective over the MTS data. As such, MTS representations learned in each regime are associated with distinct structural knowledge, which helps the model memorize a variety of conceivable scenarios and results in accurate forecasts in the continual learning context. Meanwhile, we develop a representation-matching memory replay scheme that maximizes the temporal coverage of MTS data to efficiently preserve the underlying temporal dynamics and dependency structures of each regime. Thorough empirical studies on synthetic and real-world benchmarks validate SKI-CL's efficacy and advantages over the state-of-the-art for continual MTS forecasting tasks.