 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDriving Scene Synthesis on Free-form Trajectories with Generative Prior
Dec 02, 2024

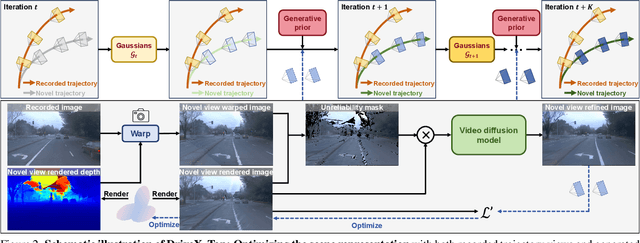

Driving scene synthesis along free-form trajectories is essential for driving simulations to enable closed-loop evaluation of end-to-end driving policies. While existing methods excel at novel view synthesis on recorded trajectories, they face challenges with novel trajectories due to limited views of driving videos and the vastness of driving environments. To tackle this challenge, we propose a novel free-form driving view synthesis approach, dubbed DriveX, by leveraging video generative prior to optimize a 3D model across a variety of trajectories. Concretely, we crafted an inverse problem that enables a video diffusion model to be utilized as a prior for many-trajectory optimization of a parametric 3D model (e.g., Gaussian splatting). To seamlessly use the generative prior, we iteratively conduct this process during optimization. Our resulting model can produce high-fidelity virtual driving environments outside the recorded trajectory, enabling free-form trajectory driving simulation. Beyond real driving scenes, DriveX can also be utilized to simulate virtual driving worlds from AI-generated videos.
Automating the Diagnosis of Human Vision Disorders by Cross-modal 3D Generation
May 24, 2024



Understanding the hidden mechanisms behind human's visual perception is a fundamental quest in neuroscience, underpins a wide variety of critical applications, e.g. clinical diagnosis. To that end, investigating into the neural responses of human mind activities, such as functional Magnetic Resonance Imaging (fMRI), has been a significant research vehicle. However, analyzing fMRI signals is challenging, costly, daunting, and demanding for professional training. Despite remarkable progress in artificial intelligence (AI) based fMRI analysis, existing solutions are limited and far away from being clinically meaningful. In this context, we leap forward to demonstrate how AI can go beyond the current state of the art by decoding fMRI into visually plausible 3D visuals, enabling automatic clinical analysis of fMRI data, even without healthcare professionals. Innovationally, we reformulate the task of analyzing fMRI data as a conditional 3D scene reconstruction problem. We design a novel cross-modal 3D scene representation learning method, Brain3D, that takes as input the fMRI data of a subject who was presented with a 2D object image, and yields as output the corresponding 3D object visuals. Importantly, we show that in simulated scenarios our AI agent captures the distinct functionalities of each region of human vision system as well as their intricate interplay relationships, aligning remarkably with the established discoveries of neuroscience. Non-expert diagnosis indicate that Brain3D can successfully identify the disordered brain regions, such as V1, V2, V3, V4, and the medial temporal lobe (MTL) within the human visual system. We also present results in cross-modal 3D visual construction setting, showcasing the perception quality of our 3D scene generation.
FaceGuard: Proactive Deepfake Detection
Sep 13, 2021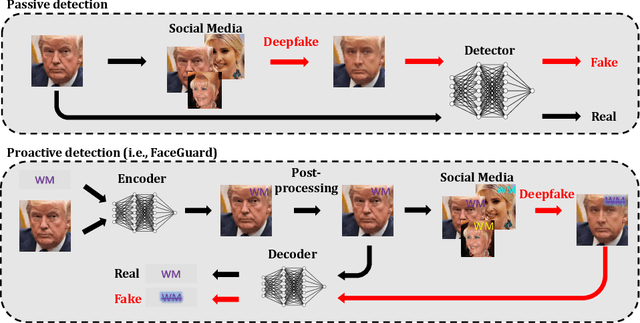

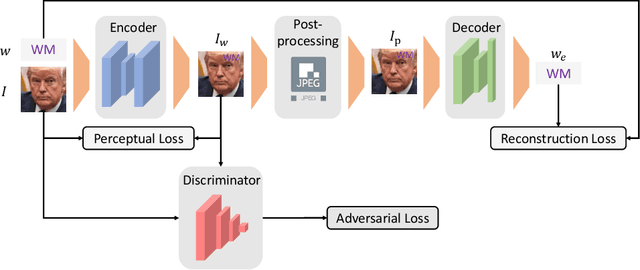
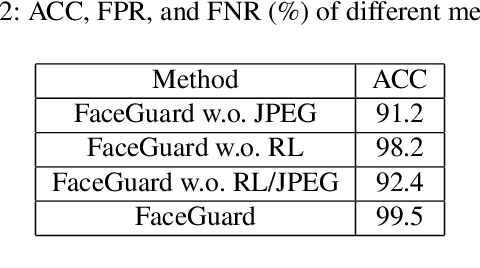
Existing deepfake-detection methods focus on passive detection, i.e., they detect fake face images via exploiting the artifacts produced during deepfake manipulation. A key limitation of passive detection is that it cannot detect fake faces that are generated by new deepfake generation methods. In this work, we propose FaceGuard, a proactive deepfake-detection framework. FaceGuard embeds a watermark into a real face image before it is published on social media. Given a face image that claims to be an individual (e.g., Nicolas Cage), FaceGuard extracts a watermark from it and predicts the face image to be fake if the extracted watermark does not match well with the individual's ground truth one. A key component of FaceGuard is a new deep-learning-based watermarking method, which is 1) robust to normal image post-processing such as JPEG compression, Gaussian blurring, cropping, and resizing, but 2) fragile to deepfake manipulation. Our evaluation on multiple datasets shows that FaceGuard can detect deepfakes accurately and outperforms existing methods.