 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTOPIC: A Parallel Association Paradigm for Multi-Object Tracking under Complex Motions and Diverse Scenes
Aug 22, 2023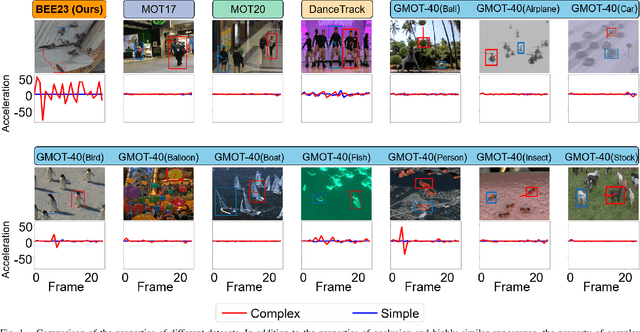
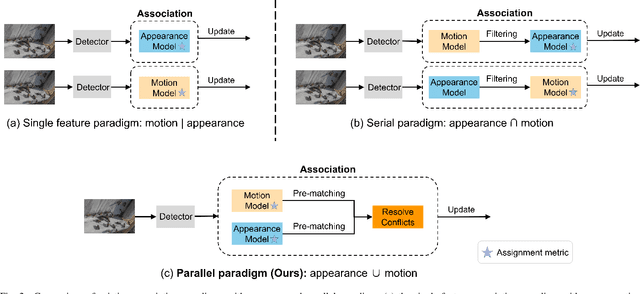


Video data and algorithms have been driving advances in multi-object tracking (MOT). While existing MOT datasets focus on occlusion and appearance similarity, complex motion patterns are widespread yet overlooked. To address this issue, we introduce a new dataset called BEE23 to highlight complex motions. Identity association algorithms have long been the focus of MOT research. Existing trackers can be categorized into two association paradigms: single-feature paradigm (based on either motion or appearance feature) and serial paradigm (one feature serves as secondary while the other is primary). However, these paradigms are incapable of fully utilizing different features. In this paper, we propose a parallel paradigm and present the Two rOund Parallel matchIng meChanism (TOPIC) to implement it. The TOPIC leverages both motion and appearance features and can adaptively select the preferable one as the assignment metric based on motion level. Moreover, we provide an Attention-based Appearance Reconstruct Module (AARM) to reconstruct appearance feature embeddings, thus enhancing the representation of appearance features. Comprehensive experiments show that our approach achieves state-of-the-art performance on four public datasets and BEE23. Notably, our proposed parallel paradigm surpasses the performance of existing association paradigms by a large margin, e.g., reducing false negatives by 12% to 51% compared to the single-feature association paradigm. The introduced dataset and association paradigm in this work offers a fresh perspective for advancing the MOT field. The source code and dataset are available at https://github.com/holmescao/TOPICTrack.
FLCert: Provably Secure Federated Learning against Poisoning Attacks
Oct 04, 2022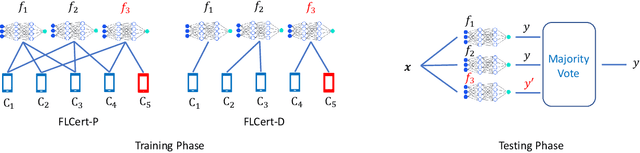
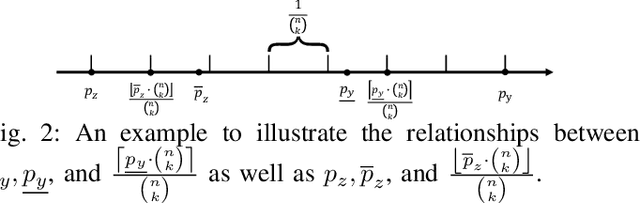

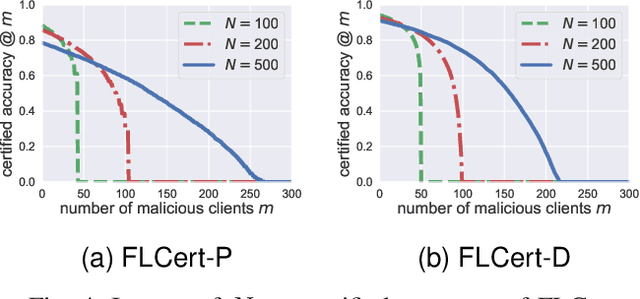
Due to its distributed nature, federated learning is vulnerable to poisoning attacks, in which malicious clients poison the training process via manipulating their local training data and/or local model updates sent to the cloud server, such that the poisoned global model misclassifies many indiscriminate test inputs or attacker-chosen ones. Existing defenses mainly leverage Byzantine-robust federated learning methods or detect malicious clients. However, these defenses do not have provable security guarantees against poisoning attacks and may be vulnerable to more advanced attacks. In this work, we aim to bridge the gap by proposing FLCert, an ensemble federated learning framework, that is provably secure against poisoning attacks with a bounded number of malicious clients. Our key idea is to divide the clients into groups, learn a global model for each group of clients using any existing federated learning method, and take a majority vote among the global models to classify a test input. Specifically, we consider two methods to group the clients and propose two variants of FLCert correspondingly, i.e., FLCert-P that randomly samples clients in each group, and FLCert-D that divides clients to disjoint groups deterministically. Our extensive experiments on multiple datasets show that the label predicted by our FLCert for a test input is provably unaffected by a bounded number of malicious clients, no matter what poisoning attacks they use.
FLDetector: Defending Federated Learning Against Model Poisoning Attacks via Detecting Malicious Clients
Jul 20, 2022



Federated learning (FL) is vulnerable to model poisoning attacks, in which malicious clients corrupt the global model via sending manipulated model updates to the server. Existing defenses mainly rely on Byzantine-robust FL methods, which aim to learn an accurate global model even if some clients are malicious. However, they can only resist a small number of malicious clients in practice. It is still an open challenge how to defend against model poisoning attacks with a large number of malicious clients. Our FLDetector addresses this challenge via detecting malicious clients. FLDetector aims to detect and remove the majority of the malicious clients such that a Byzantine-robust FL method can learn an accurate global model using the remaining clients. Our key observation is that, in model poisoning attacks, the model updates from a client in multiple iterations are inconsistent. Therefore, FLDetector detects malicious clients via checking their model-updates consistency. Roughly speaking, the server predicts a client's model update in each iteration based on its historical model updates using the Cauchy mean value theorem and L-BFGS, and flags a client as malicious if the received model update from the client and the predicted model update are inconsistent in multiple iterations. Our extensive experiments on three benchmark datasets show that FLDetector can accurately detect malicious clients in multiple state-of-the-art model poisoning attacks. After removing the detected malicious clients, existing Byzantine-robust FL methods can learn accurate global models.Our code is available at https://github.com/zaixizhang/FLDetector.
A dataset of ant colonies motion trajectories in indoor and outdoor scenes for social cluster behavior study
Apr 09, 2022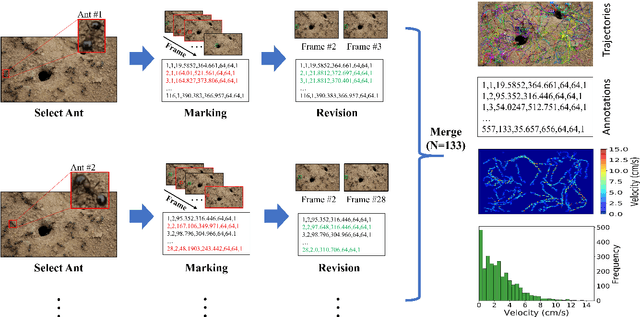
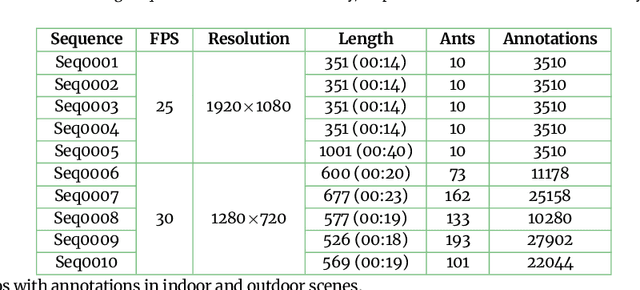
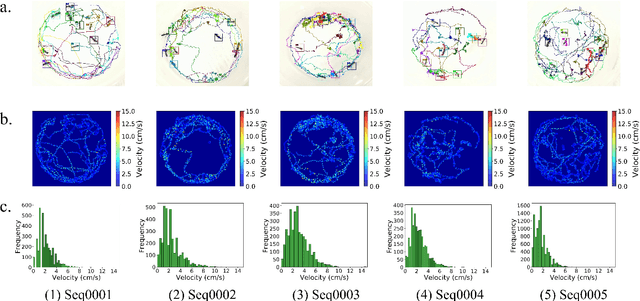
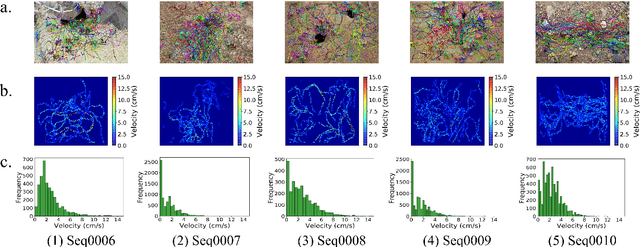
Motion and interaction of social insects (such as ants) have been studied by many researchers to understand the clustering mechanism. Most studies in the field of ant behavior have only focused on indoor environments, while outdoor environments are still underexplored. In this paper, we collect 10 videos of ant colonies from different indoor and outdoor scenes. And we develop an image sequence marking software named VisualMarkData, which enables us to provide annotations of ants in the video. In all 5354 frames, the location information and the identification number of each ant are recorded for a total of 712 ants and 114112 annotations. Moreover, we provide visual analysis tools to assess and validate the technical quality and reproducibility of our data. It is hoped that this dataset will contribute to a deeper exploration on the behavior of the ant colony.
MPAF: Model Poisoning Attacks to Federated Learning based on Fake Clients
Mar 16, 2022
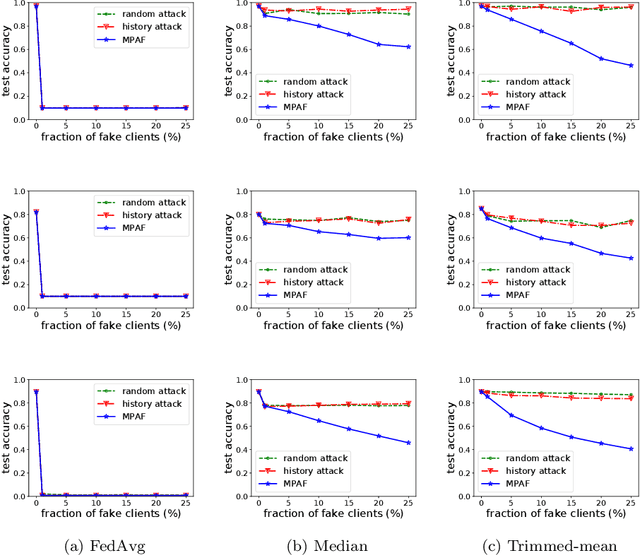
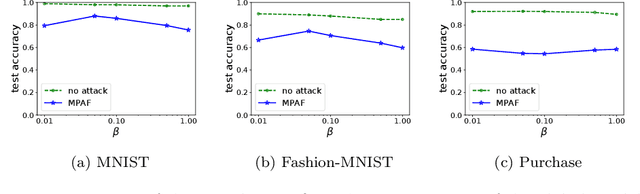

Existing model poisoning attacks to federated learning assume that an attacker has access to a large fraction of compromised genuine clients. However, such assumption is not realistic in production federated learning systems that involve millions of clients. In this work, we propose the first Model Poisoning Attack based on Fake clients called MPAF. Specifically, we assume the attacker injects fake clients to a federated learning system and sends carefully crafted fake local model updates to the cloud server during training, such that the learnt global model has low accuracy for many indiscriminate test inputs. Towards this goal, our attack drags the global model towards an attacker-chosen base model that has low accuracy. Specifically, in each round of federated learning, the fake clients craft fake local model updates that point to the base model and scale them up to amplify their impact before sending them to the cloud server. Our experiments show that MPAF can significantly decrease the test accuracy of the global model, even if classical defenses and norm clipping are adopted, highlighting the need for more advanced defenses.
FaceGuard: Proactive Deepfake Detection
Sep 13, 2021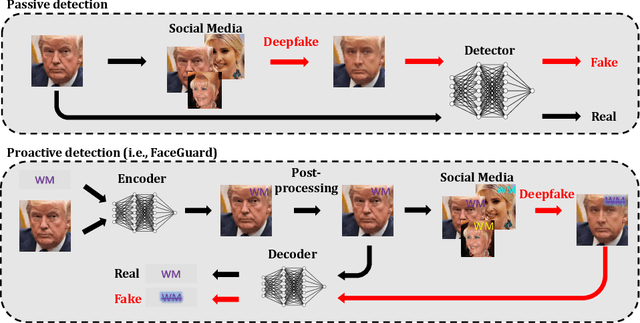

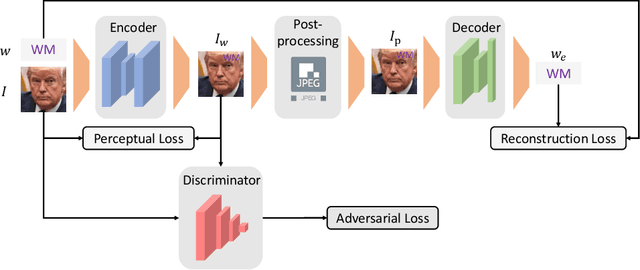
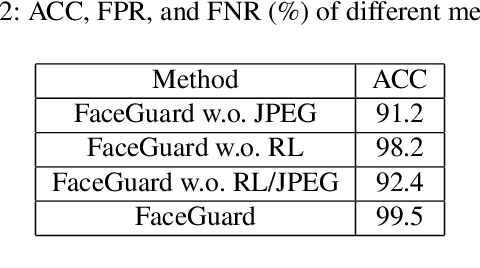
Existing deepfake-detection methods focus on passive detection, i.e., they detect fake face images via exploiting the artifacts produced during deepfake manipulation. A key limitation of passive detection is that it cannot detect fake faces that are generated by new deepfake generation methods. In this work, we propose FaceGuard, a proactive deepfake-detection framework. FaceGuard embeds a watermark into a real face image before it is published on social media. Given a face image that claims to be an individual (e.g., Nicolas Cage), FaceGuard extracts a watermark from it and predicts the face image to be fake if the extracted watermark does not match well with the individual's ground truth one. A key component of FaceGuard is a new deep-learning-based watermarking method, which is 1) robust to normal image post-processing such as JPEG compression, Gaussian blurring, cropping, and resizing, but 2) fragile to deepfake manipulation. Our evaluation on multiple datasets shows that FaceGuard can detect deepfakes accurately and outperforms existing methods.
Understanding the Security of Deepfake Detection
Jul 07, 2021
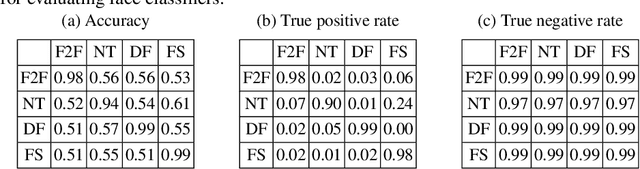
Deepfakes pose growing challenges to the trust of information on the Internet. Thus, detecting deepfakes has attracted increasing attentions from both academia and industry. State-of-the-art deepfake detection methods consist of two key components, i.e., face extractor and face classifier, which extract the face region in an image and classify it to be real/fake, respectively. Existing studies mainly focused on improving the detection performance in non-adversarial settings, leaving security of deepfake detection in adversarial settings largely unexplored. In this work, we aim to bridge the gap. In particular, we perform a systematic measurement study to understand the security of the state-of-the-art deepfake detection methods in adversarial settings. We use two large-scale public deepfakes data sources including FaceForensics++ and Facebook Deepfake Detection Challenge, where the deepfakes are fake face images; and we train state-of-the-art deepfake detection methods. These detection methods can achieve 0.94--0.99 accuracies in non-adversarial settings on these datasets. However, our measurement results uncover multiple security limitations of the deepfake detection methods in adversarial settings. First, we find that an attacker can evade a face extractor, i.e., the face extractor fails to extract the correct face regions, via adding small Gaussian noise to its deepfake images. Second, we find that a face classifier trained using deepfakes generated by one method cannot detect deepfakes generated by another method, i.e., an attacker can evade detection via generating deepfakes using a new method. Third, we find that an attacker can leverage backdoor attacks developed by the adversarial machine learning community to evade a face classifier. Our results highlight that deepfake detection should consider the adversarial nature of the problem.
IGrow: A Smart Agriculture Solution to Autonomous Greenhouse Control
Jul 06, 2021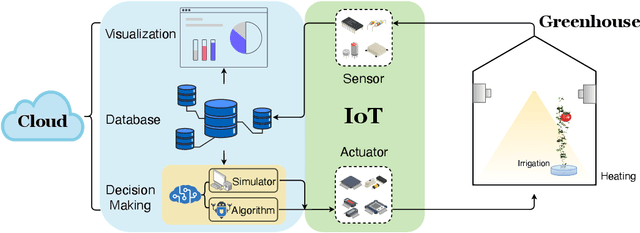
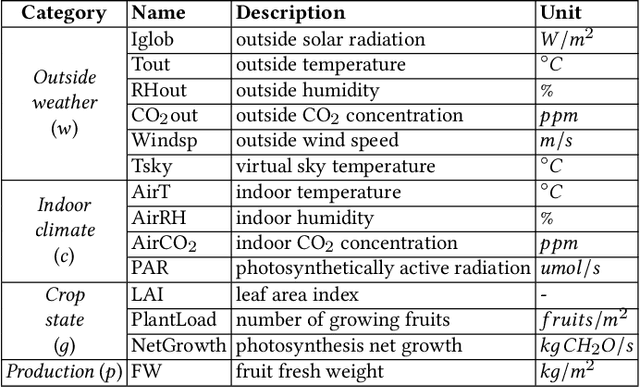
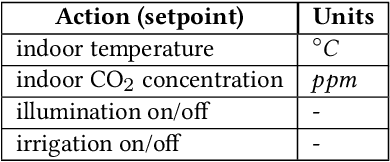
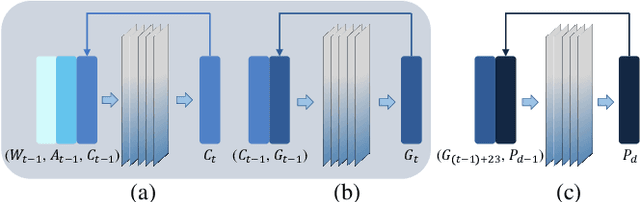
Agriculture is the foundation of human civilization. However, the rapid increase and aging of the global population pose challenges on this cornerstone by demanding more healthy and fresh food. Internet of Things (IoT) technology makes modern autonomous greenhouse a viable and reliable engine of food production. However, the educated and skilled labor capable of overseeing high-tech greenhouses is scarce. Artificial intelligence (AI) and cloud computing technologies are promising solutions for precision control and high-efficiency production in such controlled environments. In this paper, we propose a smart agriculture solution, namely iGrow: (1) we use IoT and cloud computing technologies to measure, collect, and manage growing data, to support iteration of our decision-making AI module, which consists of an incremental model and an optimization algorithm; (2) we propose a three-stage incremental model based on accumulating data, enabling growers/central computers to schedule control strategies conveniently and at low cost; (3) we propose a model-based iterative optimization algorithm, which can dynamically optimize the greenhouse control strategy in real-time production. In the simulated experiment, evaluation results show the accuracy of our incremental model is comparable to an advanced tomato simulator, while our optimization algorithms can beat the champion of the 2nd Autonomous Greenhouse Challenge. Compelling results from the A/B test in real greenhouses demonstrate that our solution significantly increases production (commercially sellable fruits) (+ 10.15%) and net profit (+ 87.07%) with statistical significance compared to planting experts.
Provably Secure Federated Learning against Malicious Clients
Feb 16, 2021
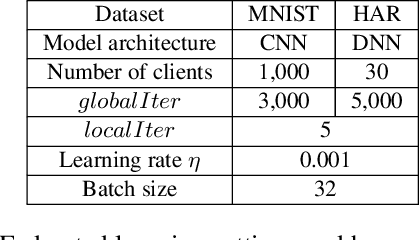
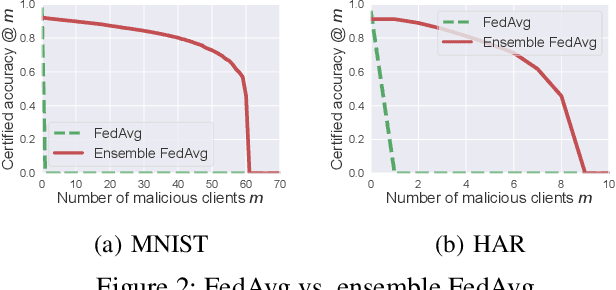
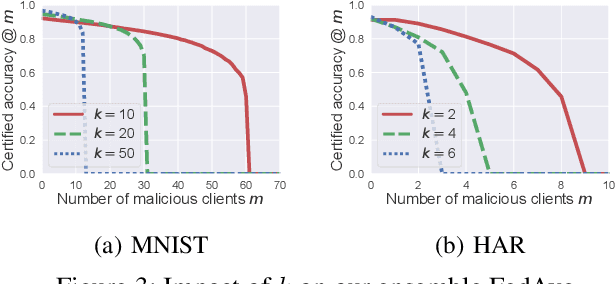
Federated learning enables clients to collaboratively learn a shared global model without sharing their local training data with a cloud server. However, malicious clients can corrupt the global model to predict incorrect labels for testing examples. Existing defenses against malicious clients leverage Byzantine-robust federated learning methods. However, these methods cannot provably guarantee that the predicted label for a testing example is not affected by malicious clients. We bridge this gap via ensemble federated learning. In particular, given any base federated learning algorithm, we use the algorithm to learn multiple global models, each of which is learnt using a randomly selected subset of clients. When predicting the label of a testing example, we take majority vote among the global models. We show that our ensemble federated learning with any base federated learning algorithm is provably secure against malicious clients. Specifically, the label predicted by our ensemble global model for a testing example is provably not affected by a bounded number of malicious clients. Moreover, we show that our derived bound is tight. We evaluate our method on MNIST and Human Activity Recognition datasets. For instance, our method can achieve a certified accuracy of 88% on MNIST when 20 out of 1,000 clients are malicious.
FLTrust: Byzantine-robust Federated Learning via Trust Bootstrapping
Dec 27, 2020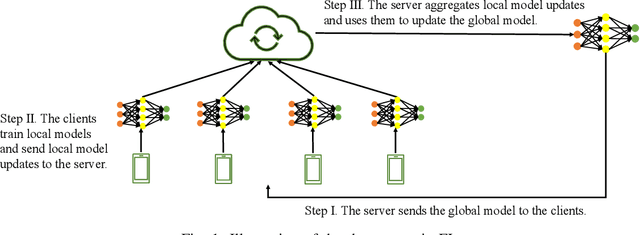
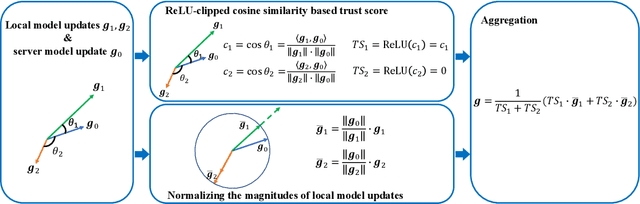
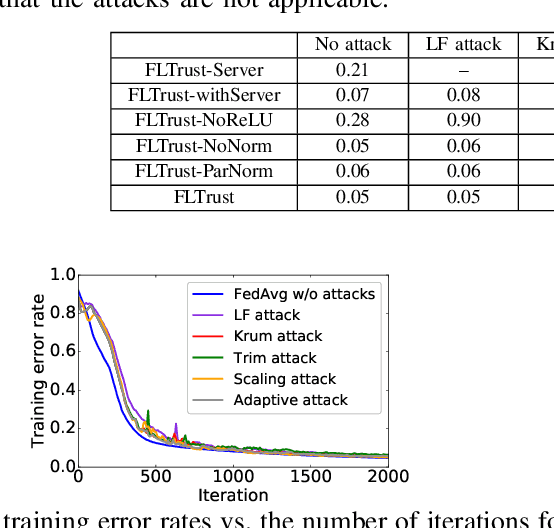
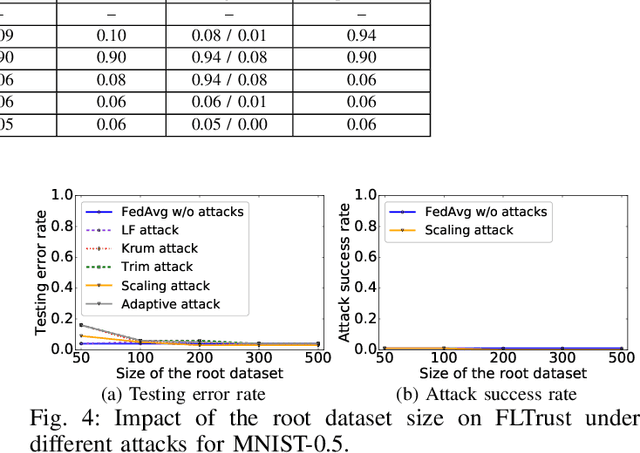
Byzantine-robust federated learning aims to enable a service provider to learn an accurate global model when a bounded number of clients are malicious. The key idea of existing Byzantine-robust federated learning methods is that the service provider performs statistical analysis among the clients' local model updates and removes suspicious ones, before aggregating them to update the global model. However, malicious clients can still corrupt the global models in these methods via sending carefully crafted local model updates to the service provider. The fundamental reason is that there is no root of trust in existing federated learning methods. In this work, we bridge the gap via proposing FLTrust, a new federated learning method in which the service provider itself bootstraps trust. In particular, the service provider itself collects a clean small training dataset (called root dataset) for the learning task and the service provider maintains a model (called server model) based on it to bootstrap trust. In each iteration, the service provider first assigns a trust score to each local model update from the clients, where a local model update has a lower trust score if its direction deviates more from the direction of the server model update. Then, the service provider normalizes the magnitudes of the local model updates such that they lie in the same hyper-sphere as the server model update in the vector space. Our normalization limits the impact of malicious local model updates with large magnitudes. Finally, the service provider computes the average of the normalized local model updates weighted by their trust scores as a global model update, which is used to update the global model. Our extensive evaluations on six datasets from different domains show that our FLTrust is secure against both existing attacks and strong adaptive attacks.