 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the Security of Deepfake Detection
Paper and Code
Jul 07, 2021
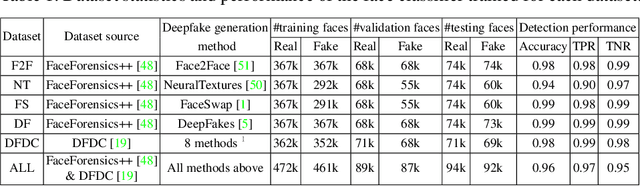
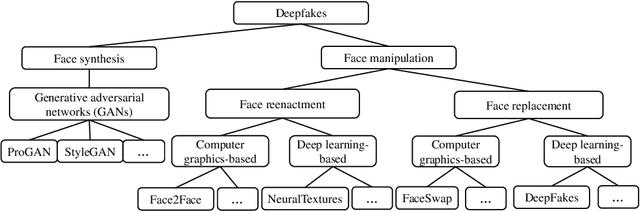
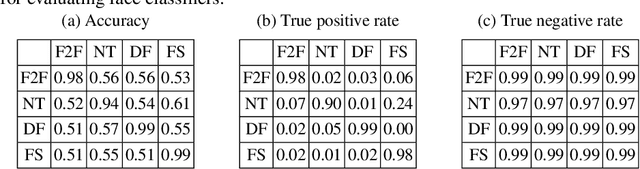
Deepfakes pose growing challenges to the trust of information on the Internet. Thus, detecting deepfakes has attracted increasing attentions from both academia and industry. State-of-the-art deepfake detection methods consist of two key components, i.e., face extractor and face classifier, which extract the face region in an image and classify it to be real/fake, respectively. Existing studies mainly focused on improving the detection performance in non-adversarial settings, leaving security of deepfake detection in adversarial settings largely unexplored. In this work, we aim to bridge the gap. In particular, we perform a systematic measurement study to understand the security of the state-of-the-art deepfake detection methods in adversarial settings. We use two large-scale public deepfakes data sources including FaceForensics++ and Facebook Deepfake Detection Challenge, where the deepfakes are fake face images; and we train state-of-the-art deepfake detection methods. These detection methods can achieve 0.94--0.99 accuracies in non-adversarial settings on these datasets. However, our measurement results uncover multiple security limitations of the deepfake detection methods in adversarial settings. First, we find that an attacker can evade a face extractor, i.e., the face extractor fails to extract the correct face regions, via adding small Gaussian noise to its deepfake images. Second, we find that a face classifier trained using deepfakes generated by one method cannot detect deepfakes generated by another method, i.e., an attacker can evade detection via generating deepfakes using a new method. Third, we find that an attacker can leverage backdoor attacks developed by the adversarial machine learning community to evade a face classifier. Our results highlight that deepfake detection should consider the adversarial nature of the problem.