 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simple Hypergraph Kernel Convolution based on Discounted Markov Diffusion Process
Oct 30, 2022



Kernels on discrete structures evaluate pairwise similarities between objects which capture semantics and inherent topology information. Existing kernels on discrete structures are only developed by topology information(such as adjacency matrix of graphs), without considering original attributes of objects. This paper proposes a two-phase paradigm to aggregate comprehensive information on discrete structures leading to a Discount Markov Diffusion Learnable Kernel (DMDLK). Specifically, based on the underlying projection of DMDLK, we design a Simple Hypergraph Kernel Convolution (SHKC) for hidden representation of vertices. SHKC can adjust diffusion steps rather than stacking convolution layers to aggregate information from long-range neighborhoods which prevents over-smoothing issues of existing hypergraph convolutions. Moreover, we utilize the uniform stability bound theorem in transductive learning to analyze critical factors for the effectiveness and generalization ability of SHKC from a theoretical perspective. The experimental results on several benchmark datasets for node classification tasks verified the superior performance of SHKC over state-of-the-art methods.
Robust Imitation Learning from Corrupted Demonstrations
Jan 29, 2022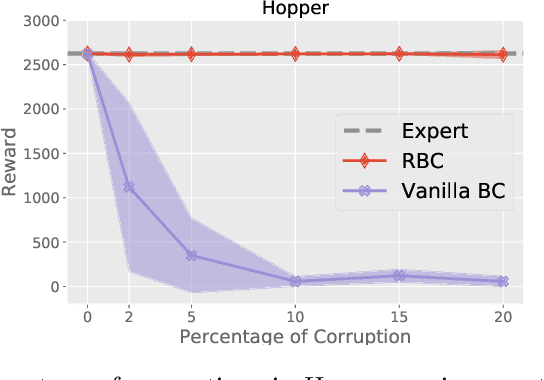
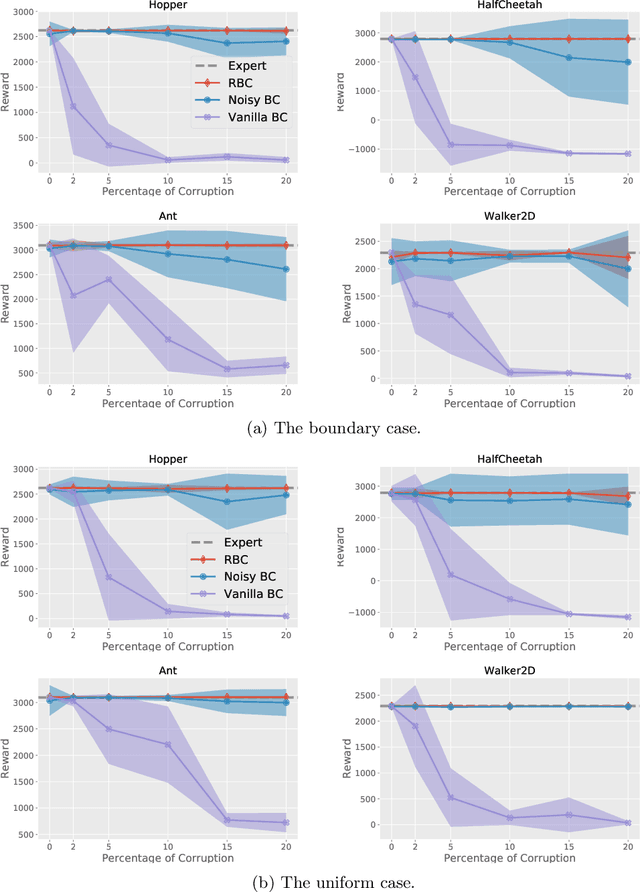
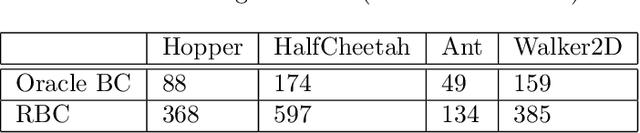
We consider offline Imitation Learning from corrupted demonstrations where a constant fraction of data can be noise or even arbitrary outliers. Classical approaches such as Behavior Cloning assumes that demonstrations are collected by an presumably optimal expert, hence may fail drastically when learning from corrupted demonstrations. We propose a novel robust algorithm by minimizing a Median-of-Means (MOM) objective which guarantees the accurate estimation of policy, even in the presence of constant fraction of outliers. Our theoretical analysis shows that our robust method in the corrupted setting enjoys nearly the same error scaling and sample complexity guarantees as the classical Behavior Cloning in the expert demonstration setting. Our experiments on continuous-control benchmarks validate that our method exhibits the predicted robustness and effectiveness, and achieves competitive results compared to existing imitation learning methods.
Robust Model-based Reinforcement Learning for Autonomous Greenhouse Control
Aug 26, 2021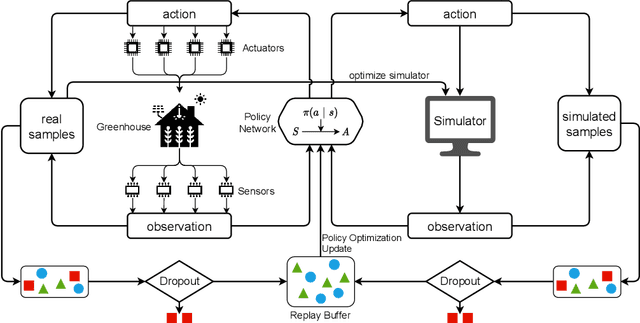
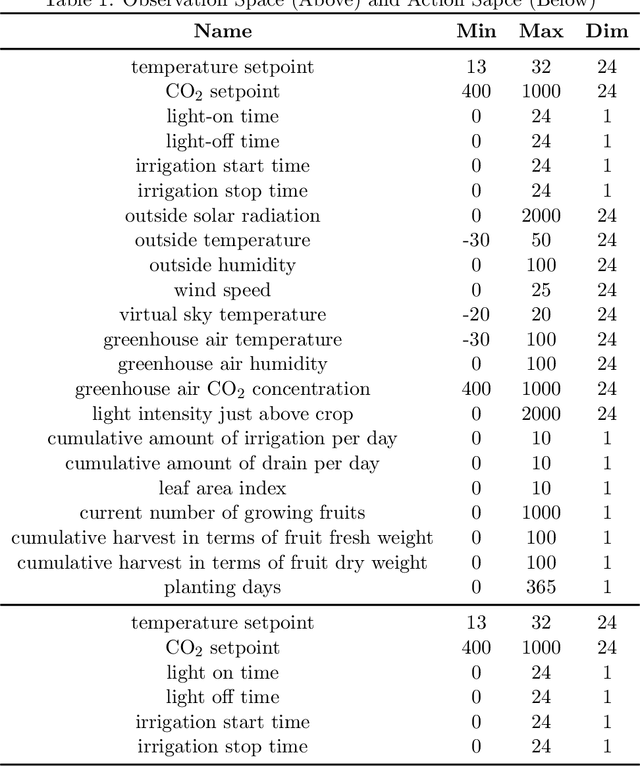

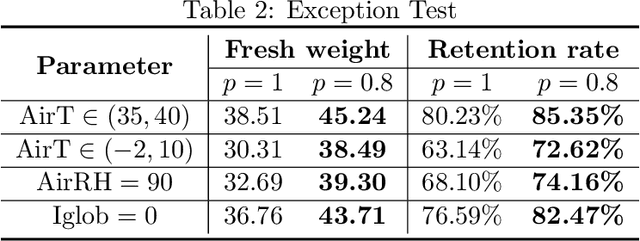
Due to the high efficiency and less weather dependency, autonomous greenhouses provide an ideal solution to meet the increasing demand for fresh food. However, managers are faced with some challenges in finding appropriate control strategies for crop growth, since the decision space of the greenhouse control problem is an astronomical number. Therefore, an intelligent closed-loop control framework is highly desired to generate an automatic control policy. As a powerful tool for optimal control, reinforcement learning (RL) algorithms can surpass human beings' decision-making and can also be seamlessly integrated into the closed-loop control framework. However, in complex real-world scenarios such as agricultural automation control, where the interaction with the environment is time-consuming and expensive, the application of RL algorithms encounters two main challenges, i.e., sample efficiency and safety. Although model-based RL methods can greatly mitigate the efficiency problem of greenhouse control, the safety problem has not got too much attention. In this paper, we present a model-based robust RL framework for autonomous greenhouse control to meet the sample efficiency and safety challenges. Specifically, our framework introduces an ensemble of environment models to work as a simulator and assist in policy optimization, thereby addressing the low sample efficiency problem. As for the safety concern, we propose a sample dropout module to focus more on worst-case samples, which can help improve the adaptability of the greenhouse planting policy in extreme cases. Experimental results demonstrate that our approach can learn a more effective greenhouse planting policy with better robustness than existing methods.
MBDP: A Model-based Approach to Achieve both Robustness and Sample Efficiency via Double Dropout Planning
Aug 03, 2021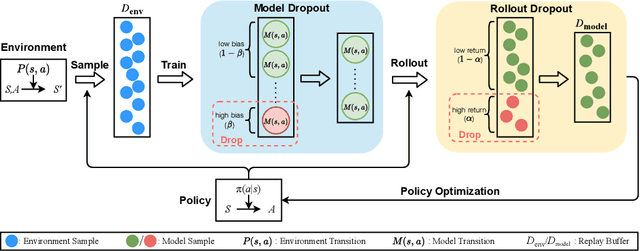



Model-based reinforcement learning is a widely accepted solution for solving excessive sample demands. However, the predictions of the dynamics models are often not accurate enough, and the resulting bias may incur catastrophic decisions due to insufficient robustness. Therefore, it is highly desired to investigate how to improve the robustness of model-based RL algorithms while maintaining high sampling efficiency. In this paper, we propose Model-Based Double-dropout Planning (MBDP) to balance robustness and efficiency. MBDP consists of two kinds of dropout mechanisms, where the rollout-dropout aims to improve the robustness with a small cost of sample efficiency, while the model-dropout is designed to compensate for the lost efficiency at a slight expense of robustness. By combining them in a complementary way, MBDP provides a flexible control mechanism to meet different demands of robustness and efficiency by tuning two corresponding dropout ratios. The effectiveness of MBDP is demonstrated both theoretically and experimentally.
IGrow: A Smart Agriculture Solution to Autonomous Greenhouse Control
Jul 06, 2021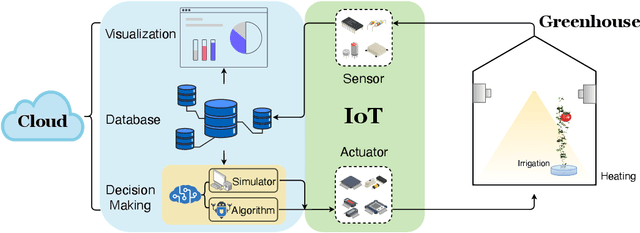
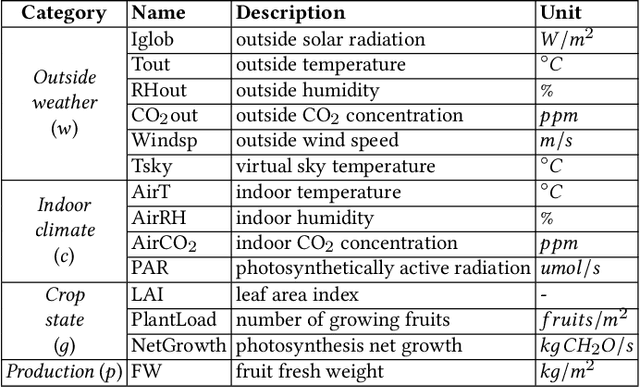
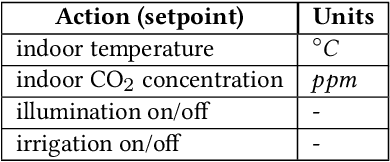
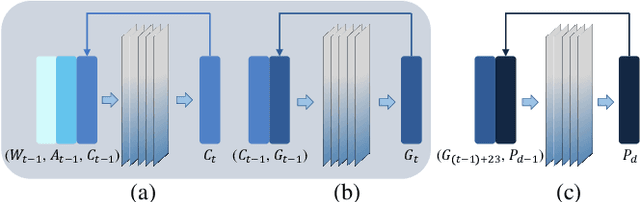
Agriculture is the foundation of human civilization. However, the rapid increase and aging of the global population pose challenges on this cornerstone by demanding more healthy and fresh food. Internet of Things (IoT) technology makes modern autonomous greenhouse a viable and reliable engine of food production. However, the educated and skilled labor capable of overseeing high-tech greenhouses is scarce. Artificial intelligence (AI) and cloud computing technologies are promising solutions for precision control and high-efficiency production in such controlled environments. In this paper, we propose a smart agriculture solution, namely iGrow: (1) we use IoT and cloud computing technologies to measure, collect, and manage growing data, to support iteration of our decision-making AI module, which consists of an incremental model and an optimization algorithm; (2) we propose a three-stage incremental model based on accumulating data, enabling growers/central computers to schedule control strategies conveniently and at low cost; (3) we propose a model-based iterative optimization algorithm, which can dynamically optimize the greenhouse control strategy in real-time production. In the simulated experiment, evaluation results show the accuracy of our incremental model is comparable to an advanced tomato simulator, while our optimization algorithms can beat the champion of the 2nd Autonomous Greenhouse Challenge. Compelling results from the A/B test in real greenhouses demonstrate that our solution significantly increases production (commercially sellable fruits) (+ 10.15%) and net profit (+ 87.07%) with statistical significance compared to planting experts.
Sample Efficient Reinforcement Learning via Model-Ensemble Exploration and Exploitation
Jul 05, 2021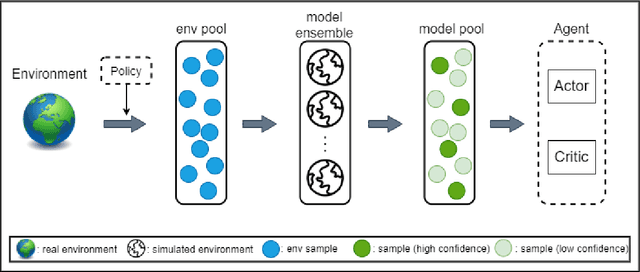
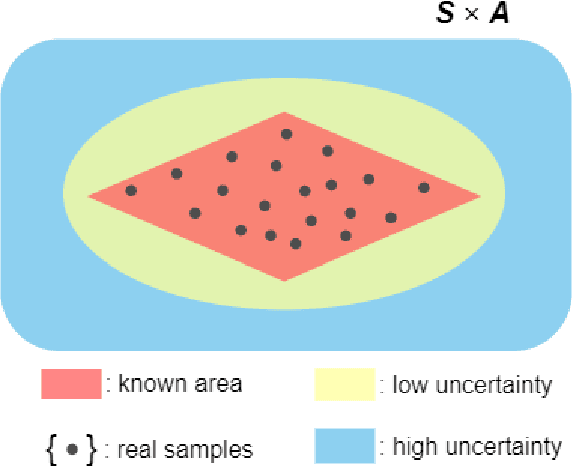
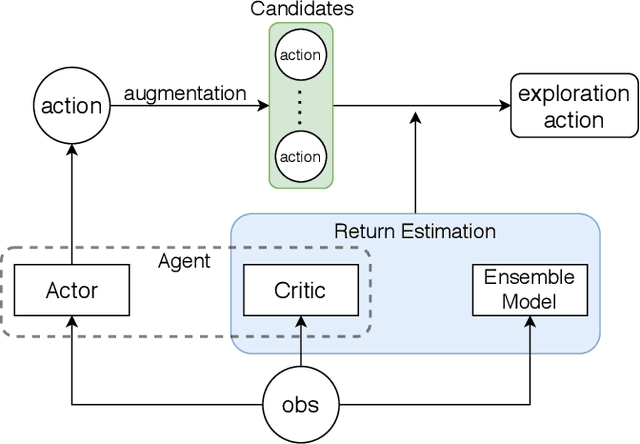

Model-based deep reinforcement learning has achieved success in various domains that require high sample efficiencies, such as Go and robotics. However, there are some remaining issues, such as planning efficient explorations to learn more accurate dynamic models, evaluating the uncertainty of the learned models, and more rational utilization of models. To mitigate these issues, we present MEEE, a model-ensemble method that consists of optimistic exploration and weighted exploitation. During exploration, unlike prior methods directly selecting the optimal action that maximizes the expected accumulative return, our agent first generates a set of action candidates and then seeks out the optimal action that takes both expected return and future observation novelty into account. During exploitation, different discounted weights are assigned to imagined transition tuples according to their model uncertainty respectively, which will prevent model predictive error propagation in agent training. Experiments on several challenging continuous control benchmark tasks demonstrated that our approach outperforms other model-free and model-based state-of-the-art methods, especially in sample complexity.
Bias-reduced multi-step hindsight experience replay
Feb 25, 2021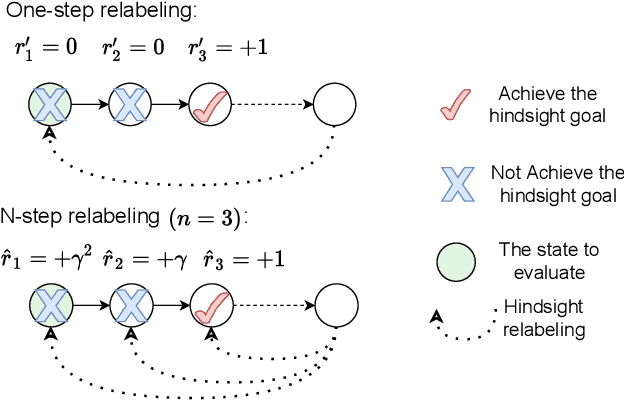
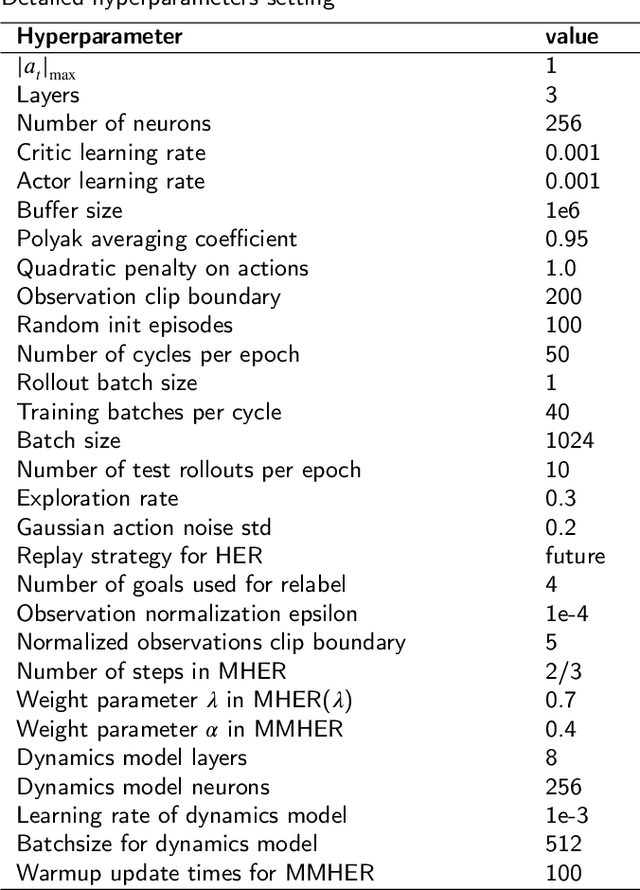
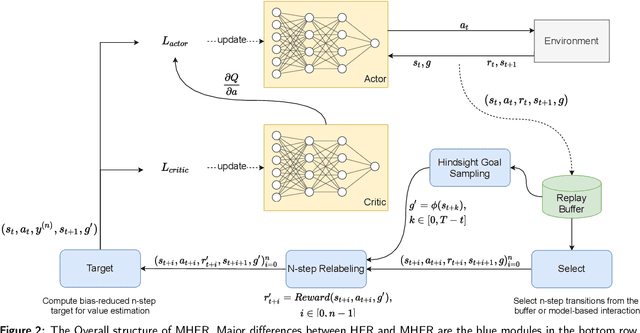
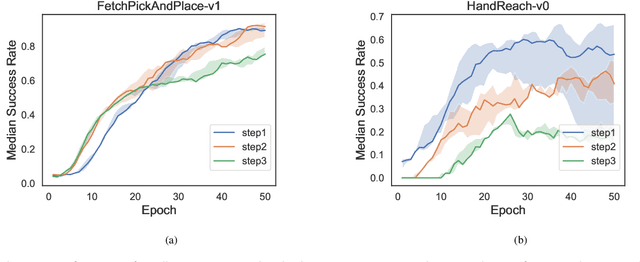
Multi-goal reinforcement learning is widely used in planning and robot manipulation. Two main challenges in multi-goal reinforcement learning are sparse rewards and sample inefficiency. Hindsight Experience Replay (HER) aims to tackle the two challenges with hindsight knowledge. However, HER and its previous variants still need millions of samples and a huge computation. In this paper, we propose \emph{Multi-step Hindsight Experience Replay} (MHER) based on $n$-step relabeling, incorporating multi-step relabeled returns to improve sample efficiency. Despite the advantages of $n$-step relabeling, we theoretically and experimentally prove the off-policy $n$-step bias introduced by $n$-step relabeling may lead to poor performance in many environments. To address the above issue, two bias-reduced MHER algorithms, MHER($\lambda$) and Model-based MHER (MMHER) are presented. MHER($\lambda$) exploits the $\lambda$ return while MMHER benefits from model-based value expansions. Experimental results on numerous multi-goal robotic tasks show that our solutions can successfully alleviate off-policy $n$-step bias and achieve significantly higher sample efficiency than HER and Curriculum-guided HER with little additional computation beyond HER.
Improved Context-Based Offline Meta-RL with Attention and Contrastive Learning
Feb 22, 2021
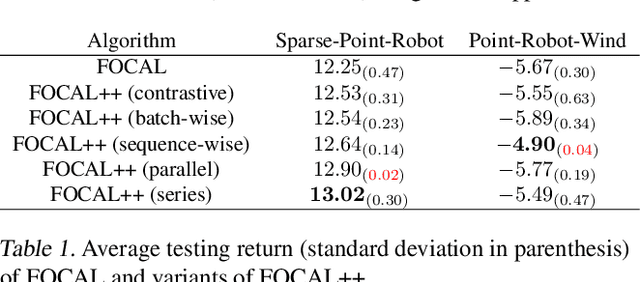
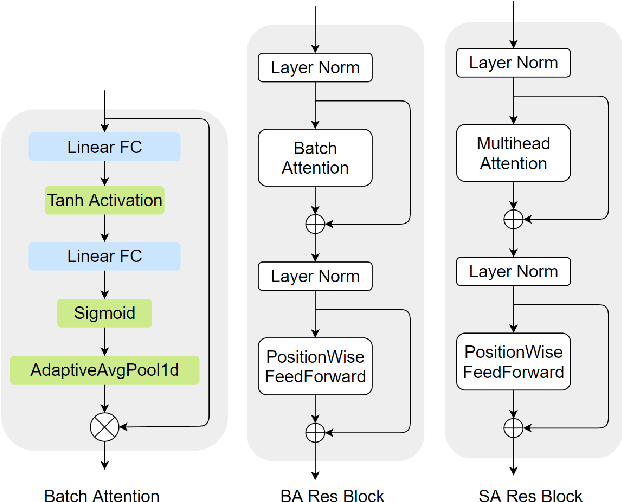
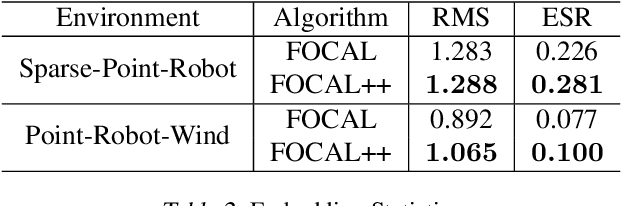
Meta-learning for offline reinforcement learning (OMRL) is an understudied problem with tremendous potential impact by enabling RL algorithms in many real-world applications. A popular solution to the problem is to infer task identity as augmented state using a context-based encoder, for which efficient learning of task representations remains an open challenge. In this work, we improve upon one of the SOTA OMRL algorithms, FOCAL, by incorporating intra-task attention mechanism and inter-task contrastive learning objectives for more effective task inference and learning of control. Theoretical analysis and experiments are presented to demonstrate the superior performance, efficiency and robustness of our end-to-end and model free method compared to prior algorithms across multiple meta-RL benchmarks.
Efficient Fully-Offline Meta-Reinforcement Learning via Distance Metric Learning and Behavior Regularization
Oct 02, 2020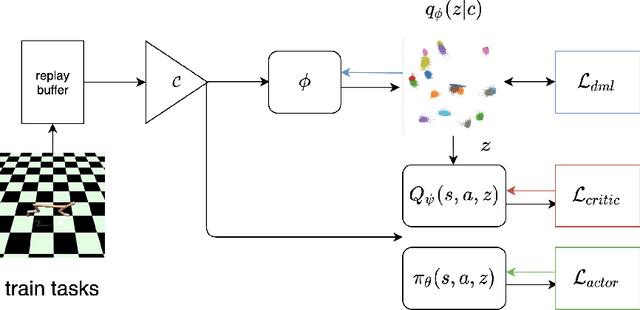
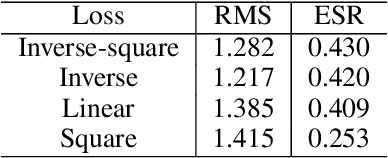
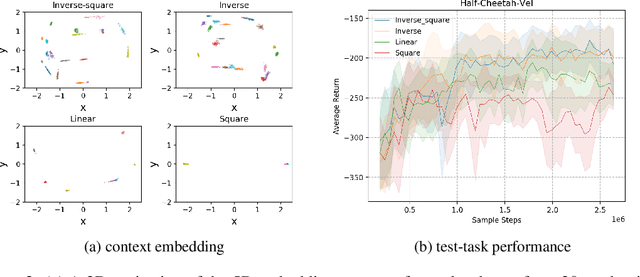
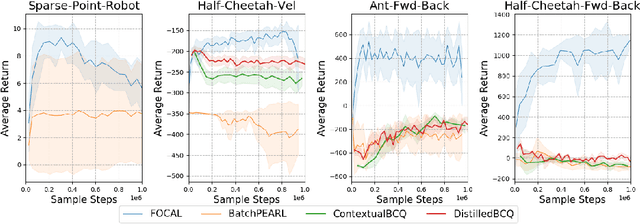
We study the offline meta-reinforcement learning (OMRL) problem, a paradigm which enables reinforcement learning (RL) algorithms to quickly adapt to unseen tasks without any interactions with the environments, making RL truly practical in many real-world applications. This problem is still not fully understood, for which two major challenges need to be addressed. First, offline RL often suffers from bootstrapping errors of out-of-distribution state-actions which leads to divergence of value functions. Second, meta-RL requires efficient and robust task inference learned jointly with control policy. In this work, we enforce behavior regularization on learned policy as a general approach to offline RL, combined with a deterministic context encoder for efficient task inference. We propose a novel negative-power distance metric on bounded context embedding space, whose gradients propagation is detached from that of the Bellman backup. We provide analysis and insight showing that some simple design choices can yield substantial improvements over recent approaches involving meta-RL and distance metric learning. To the best of our knowledge, our method is the first model-free and end-to-end OMRL algorithm, which is computationally efficient and demonstrated to outperform prior algorithms on several meta-RL benchmarks.
Label Aware Graph Convolutional Network -- Not All Edges Deserve Your Attention
Jul 10, 2019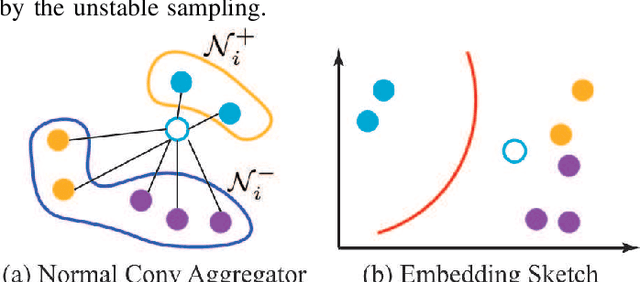
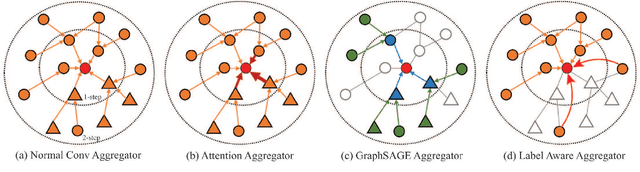

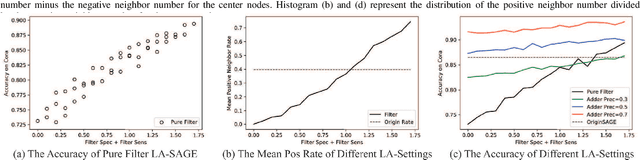
Graph classification is practically important in many domains. To solve this problem, one usually calculates a low-dimensional representation for each node in the graph with supervised or unsupervised approaches. Most existing approaches consider all the edges between nodes while overlooking whether the edge will brings positive or negative influence to the node representation learning. In many real-world applications, however, some connections among the nodes can be noisy for graph convolution, and not all the edges deserve your attention. In this work, we distinguish the positive and negative impacts of the neighbors to the node in graph node classification, and propose to enhance the graph convolutional network by considering the labels between the neighbor edges. We present a novel GCN framework, called Label-aware Graph Convolutional Network (LAGCN), which incorporates the supervised and unsupervised learning by introducing the edge label predictor. As a general model, LAGCN can be easily adapted in various previous GCN and enhance their performance with some theoretical guarantees. Experimental results on multiple real-world datasets show that LAGCN is competitive against various state-of-the-art methods in graph classification.