 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLFEC: A New Task for Unified Linguistic and Factual Error Correction in paragraph-level Chinese Professional Writing
Feb 27, 2026Chinese text correction has traditionally focused on spelling and grammar, while factual error correction is usually treated separately. However, in paragraph-level Chinese professional writing, linguistic (word/grammar/punctuation) and factual errors frequently co-occur and interact, making unified correction both necessary and challenging. This paper introduces CLFEC (Chinese Linguistic & Factual Error Correction), a new task for joint linguistic and factual correction. We construct a mixed, multi-domain Chinese professional writing dataset spanning current affairs, finance, law, and medicine. We then conduct a systematic study of LLM-based correction paradigms, from prompting to retrieval-augmented generation (RAG) and agentic workflows. The analysis reveals practical challenges, including limited generalization of specialized correction models, the need for evidence grounding for factual repair, the difficulty of mixed-error paragraphs, and over-correction on clean inputs. Results further show that handling linguistic and factual Error within the same context outperform decoupled processes, and that agentic workflows can be effective with suitable backbone models. Overall, our dataset and empirical findings provide guidance for building reliable, fully automatic proofreading systems in industrial settings.
Multi-agent Application System in Office Collaboration Scenarios
Mar 26, 2025This paper introduces a multi-agent application system designed to enhance office collaboration efficiency and work quality. The system integrates artificial intelligence, machine learning, and natural language processing technologies, achieving functionalities such as task allocation, progress monitoring, and information sharing. The agents within the system are capable of providing personalized collaboration support based on team members' needs and incorporate data analysis tools to improve decision-making quality. The paper also proposes an intelligent agent architecture that separates Plan and Solver, and through techniques such as multi-turn query rewriting and business tool retrieval, it enhances the agent's multi-intent and multi-turn dialogue capabilities. Furthermore, the paper details the design of tools and multi-turn dialogue in the context of office collaboration scenarios, and validates the system's effectiveness through experiments and evaluations. Ultimately, the system has demonstrated outstanding performance in real business applications, particularly in query understanding, task planning, and tool calling. Looking forward, the system is expected to play a more significant role in addressing complex interaction issues within dynamic environments and large-scale multi-agent systems.
Autonomous Driving in Unstructured Environments: How Far Have We Come?
Oct 10, 2024

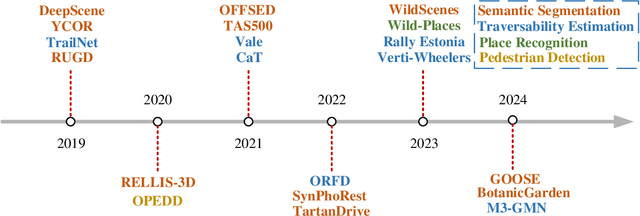

Research on autonomous driving in unstructured outdoor environments is less advanced than in structured urban settings due to challenges like environmental diversities and scene complexity. These environments-such as rural areas and rugged terrains-pose unique obstacles that are not common in structured urban areas. Despite these difficulties, autonomous driving in unstructured outdoor environments is crucial for applications in agriculture, mining, and military operations. Our survey reviews over 250 papers for autonomous driving in unstructured outdoor environments, covering offline mapping, pose estimation, environmental perception, path planning, end-to-end autonomous driving, datasets, and relevant challenges. We also discuss emerging trends and future research directions. This review aims to consolidate knowledge and encourage further research for autonomous driving in unstructured environments. To support ongoing work, we maintain an active repository with up-to-date literature and open-source projects at: https://github.com/chaytonmin/Survey-Autonomous-Driving-in-Unstructured-Environments.
Occ-BEV: Multi-Camera Unified Pre-training via 3D Scene Reconstruction
Jun 07, 2023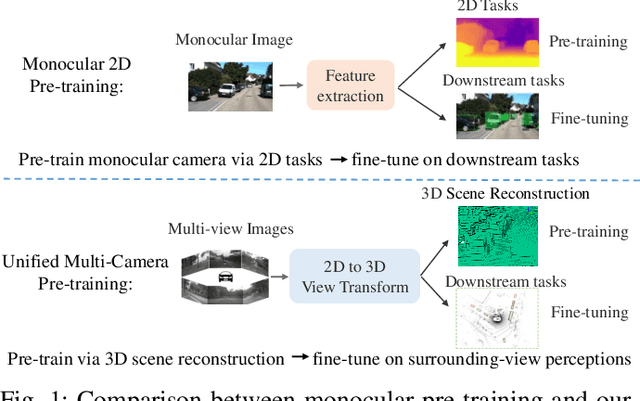



Multi-camera 3D perception has emerged as a prominent research field in autonomous driving, offering a viable and cost-effective alternative to LiDAR-based solutions. However, existing multi-camera algorithms primarily rely on monocular image pre-training, which overlooks the spatial and temporal correlations among different camera views. To address this limitation, we propose the first multi-camera unified pre-training framework called Occ-BEV, which involves initially reconstructing the 3D scene as the foundational stage and subsequently fine-tuning the model on downstream tasks. Specifically, a 3D decoder is designed for leveraging Bird's Eye View (BEV) features from multi-view images to predict the 3D geometric occupancy to enable the model to capture a more comprehensive understanding of the 3D environment. A significant benefit of Occ-BEV is its capability of utilizing a considerable volume of unlabeled image-LiDAR pairs for pre-training purposes. The proposed multi-camera unified pre-training framework demonstrates promising results in key tasks such as multi-camera 3D object detection and surrounding semantic scene completion. When compared to monocular pre-training methods on the nuScenes dataset, Occ-BEV shows a significant improvement of about 2.0% in mAP and 2.0% in NDS for multi-camera 3D object detection, as well as a 3% increase in mIoU for surrounding semantic scene completion. Codes are publicly available at https://github.com/chaytonmin/Occ-BEV.
A Simple Hypergraph Kernel Convolution based on Discounted Markov Diffusion Process
Oct 30, 2022



Kernels on discrete structures evaluate pairwise similarities between objects which capture semantics and inherent topology information. Existing kernels on discrete structures are only developed by topology information(such as adjacency matrix of graphs), without considering original attributes of objects. This paper proposes a two-phase paradigm to aggregate comprehensive information on discrete structures leading to a Discount Markov Diffusion Learnable Kernel (DMDLK). Specifically, based on the underlying projection of DMDLK, we design a Simple Hypergraph Kernel Convolution (SHKC) for hidden representation of vertices. SHKC can adjust diffusion steps rather than stacking convolution layers to aggregate information from long-range neighborhoods which prevents over-smoothing issues of existing hypergraph convolutions. Moreover, we utilize the uniform stability bound theorem in transductive learning to analyze critical factors for the effectiveness and generalization ability of SHKC from a theoretical perspective. The experimental results on several benchmark datasets for node classification tasks verified the superior performance of SHKC over state-of-the-art methods.
Hypergraph Convolutional Networks via Equivalency between Hypergraphs and Undirected Graphs
Apr 06, 2022
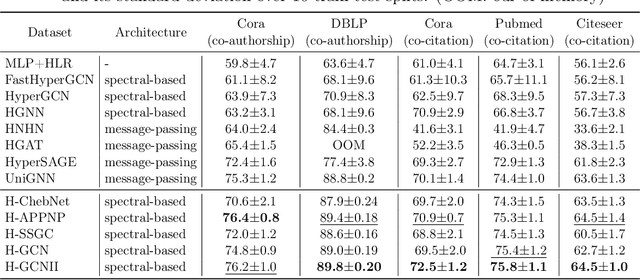
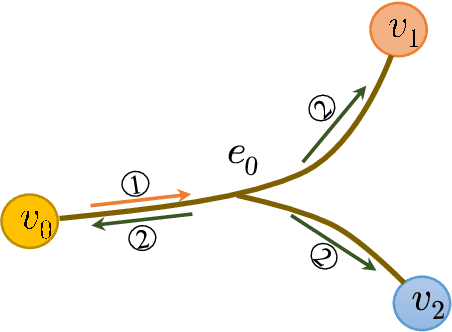

As a powerful tool for modeling complex relationships, hypergraphs are gaining popularity from the graph learning community. However, commonly used frameworks in deep hypergraph learning focus on hypergraphs with \textit{edge-independent vertex weights}(EIVWs), without considering hypergraphs with \textit{edge-dependent vertex weights} (EDVWs) that have more modeling power. To compensate for this, in this paper, we present General Hypergraph Spectral Convolution(GHSC), a general learning framework that not only can handle EDVW and EIVW hypergraphs, but more importantly, enables theoretically explicitly utilizing the existing powerful Graph Convolutional Neural Networks (GCNNs) such that largely ease the design of Hypergraph Neural Networks. In this framework, the graph Laplacian of the given undirected GCNNs is replaced with a unified hypergraph Laplacian that incorporates vertex weight information from a random walk perspective by equating our defined generalized hypergraphs with simple undirected graphs. Extensive experiments from various domains including social network analysis, visual objective classification, protein learning demonstrate that the proposed framework can achieve state-of-the-art performance.