 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOcc-BEV: Multi-Camera Unified Pre-training via 3D Scene Reconstruction
Jun 07, 2023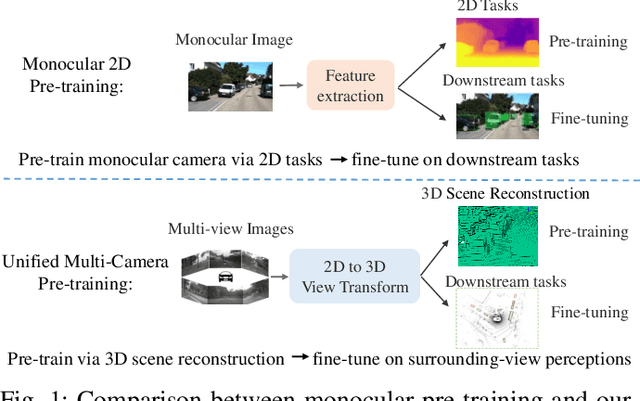



Multi-camera 3D perception has emerged as a prominent research field in autonomous driving, offering a viable and cost-effective alternative to LiDAR-based solutions. However, existing multi-camera algorithms primarily rely on monocular image pre-training, which overlooks the spatial and temporal correlations among different camera views. To address this limitation, we propose the first multi-camera unified pre-training framework called Occ-BEV, which involves initially reconstructing the 3D scene as the foundational stage and subsequently fine-tuning the model on downstream tasks. Specifically, a 3D decoder is designed for leveraging Bird's Eye View (BEV) features from multi-view images to predict the 3D geometric occupancy to enable the model to capture a more comprehensive understanding of the 3D environment. A significant benefit of Occ-BEV is its capability of utilizing a considerable volume of unlabeled image-LiDAR pairs for pre-training purposes. The proposed multi-camera unified pre-training framework demonstrates promising results in key tasks such as multi-camera 3D object detection and surrounding semantic scene completion. When compared to monocular pre-training methods on the nuScenes dataset, Occ-BEV shows a significant improvement of about 2.0% in mAP and 2.0% in NDS for multi-camera 3D object detection, as well as a 3% increase in mIoU for surrounding semantic scene completion. Codes are publicly available at https://github.com/chaytonmin/Occ-BEV.