 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutonomous Driving in Unstructured Environments: How Far Have We Come?
Oct 10, 2024

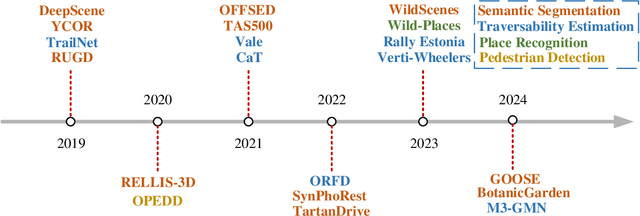

Research on autonomous driving in unstructured outdoor environments is less advanced than in structured urban settings due to challenges like environmental diversities and scene complexity. These environments-such as rural areas and rugged terrains-pose unique obstacles that are not common in structured urban areas. Despite these difficulties, autonomous driving in unstructured outdoor environments is crucial for applications in agriculture, mining, and military operations. Our survey reviews over 250 papers for autonomous driving in unstructured outdoor environments, covering offline mapping, pose estimation, environmental perception, path planning, end-to-end autonomous driving, datasets, and relevant challenges. We also discuss emerging trends and future research directions. This review aims to consolidate knowledge and encourage further research for autonomous driving in unstructured environments. To support ongoing work, we maintain an active repository with up-to-date literature and open-source projects at: https://github.com/chaytonmin/Survey-Autonomous-Driving-in-Unstructured-Environments.
Contrastive Label Disambiguation for Self-Supervised Terrain Traversability Learning in Off-Road Environments
Jul 06, 2023



Discriminating the traversability of terrains is a crucial task for autonomous driving in off-road environments. However, it is challenging due to the diverse, ambiguous, and platform-specific nature of off-road traversability. In this paper, we propose a novel self-supervised terrain traversability learning framework, utilizing a contrastive label disambiguation mechanism. Firstly, weakly labeled training samples with pseudo labels are automatically generated by projecting actual driving experiences onto the terrain models constructed in real time. Subsequently, a prototype-based contrastive representation learning method is designed to learn distinguishable embeddings, facilitating the self-supervised updating of those pseudo labels. As the iterative interaction between representation learning and pseudo label updating, the ambiguities in those pseudo labels are gradually eliminated, enabling the learning of platform-specific and task-specific traversability without any human-provided annotations. Experimental results on the RELLIS-3D dataset and our Gobi Desert driving dataset demonstrate the effectiveness of the proposed method.
Traversability Analysis for Autonomous Driving in Complex Environment: A LiDAR-based Terrain Modeling Approach
Jul 05, 2023For autonomous driving, traversability analysis is one of the most basic and essential tasks. In this paper, we propose a novel LiDAR-based terrain modeling approach, which could output stable, complete and accurate terrain models and traversability analysis results. As terrain is an inherent property of the environment that does not change with different view angles, our approach adopts a multi-frame information fusion strategy for terrain modeling. Specifically, a normal distributions transform mapping approach is adopted to accurately model the terrain by fusing information from consecutive LiDAR frames. Then the spatial-temporal Bayesian generalized kernel inference and bilateral filtering are utilized to promote the stability and completeness of the results while simultaneously retaining the sharp terrain edges. Based on the terrain modeling results, the traversability of each region is obtained by performing geometric connectivity analysis between neighboring terrain regions. Experimental results show that the proposed method could run in real-time and outperforms state-of-the-art approaches.
* accepted to Journal of Field Robotics
Occ-BEV: Multi-Camera Unified Pre-training via 3D Scene Reconstruction
Jun 07, 2023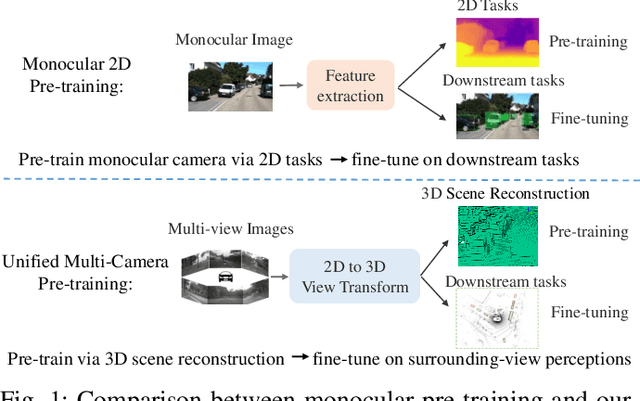



Multi-camera 3D perception has emerged as a prominent research field in autonomous driving, offering a viable and cost-effective alternative to LiDAR-based solutions. However, existing multi-camera algorithms primarily rely on monocular image pre-training, which overlooks the spatial and temporal correlations among different camera views. To address this limitation, we propose the first multi-camera unified pre-training framework called Occ-BEV, which involves initially reconstructing the 3D scene as the foundational stage and subsequently fine-tuning the model on downstream tasks. Specifically, a 3D decoder is designed for leveraging Bird's Eye View (BEV) features from multi-view images to predict the 3D geometric occupancy to enable the model to capture a more comprehensive understanding of the 3D environment. A significant benefit of Occ-BEV is its capability of utilizing a considerable volume of unlabeled image-LiDAR pairs for pre-training purposes. The proposed multi-camera unified pre-training framework demonstrates promising results in key tasks such as multi-camera 3D object detection and surrounding semantic scene completion. When compared to monocular pre-training methods on the nuScenes dataset, Occ-BEV shows a significant improvement of about 2.0% in mAP and 2.0% in NDS for multi-camera 3D object detection, as well as a 3% increase in mIoU for surrounding semantic scene completion. Codes are publicly available at https://github.com/chaytonmin/Occ-BEV.