 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Vision-Language-Action Model with Visual Prompt for OFF-Road Autonomous Driving
Jan 07, 2026Efficient trajectory planning in off-road terrains presents a formidable challenge for autonomous vehicles, often necessitating complex multi-step pipelines. However, traditional approaches exhibit limited adaptability in dynamic environments. To address these limitations, this paper proposes OFF-EMMA, a novel end-to-end multimodal framework designed to overcome the deficiencies of insufficient spatial perception and unstable reasoning in visual-language-action (VLA) models for off-road autonomous driving scenarios. The framework explicitly annotates input images through the design of a visual prompt block and introduces a chain-of-thought with self-consistency (COT-SC) reasoning strategy to enhance the accuracy and robustness of trajectory planning. The visual prompt block utilizes semantic segmentation masks as visual prompts, enhancing the spatial understanding ability of pre-trained visual-language models for complex terrains. The COT- SC strategy effectively mitigates the error impact of outliers on planning performance through a multi-path reasoning mechanism. Experimental results on the RELLIS-3D off-road dataset demonstrate that OFF-EMMA significantly outperforms existing methods, reducing the average L2 error of the Qwen backbone model by 13.3% and decreasing the failure rate from 16.52% to 6.56%.
Autonomous Driving in Unstructured Environments: How Far Have We Come?
Oct 10, 2024

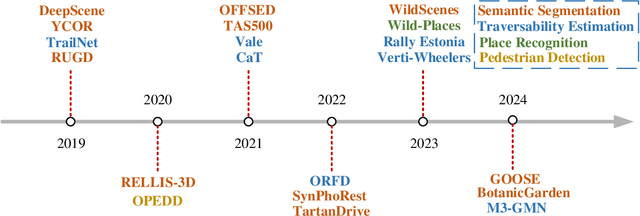

Research on autonomous driving in unstructured outdoor environments is less advanced than in structured urban settings due to challenges like environmental diversities and scene complexity. These environments-such as rural areas and rugged terrains-pose unique obstacles that are not common in structured urban areas. Despite these difficulties, autonomous driving in unstructured outdoor environments is crucial for applications in agriculture, mining, and military operations. Our survey reviews over 250 papers for autonomous driving in unstructured outdoor environments, covering offline mapping, pose estimation, environmental perception, path planning, end-to-end autonomous driving, datasets, and relevant challenges. We also discuss emerging trends and future research directions. This review aims to consolidate knowledge and encourage further research for autonomous driving in unstructured environments. To support ongoing work, we maintain an active repository with up-to-date literature and open-source projects at: https://github.com/chaytonmin/Survey-Autonomous-Driving-in-Unstructured-Environments.
DriveWorld: 4D Pre-trained Scene Understanding via World Models for Autonomous Driving
May 07, 2024Vision-centric autonomous driving has recently raised wide attention due to its lower cost. Pre-training is essential for extracting a universal representation. However, current vision-centric pre-training typically relies on either 2D or 3D pre-text tasks, overlooking the temporal characteristics of autonomous driving as a 4D scene understanding task. In this paper, we address this challenge by introducing a world model-based autonomous driving 4D representation learning framework, dubbed \emph{DriveWorld}, which is capable of pre-training from multi-camera driving videos in a spatio-temporal fashion. Specifically, we propose a Memory State-Space Model for spatio-temporal modelling, which consists of a Dynamic Memory Bank module for learning temporal-aware latent dynamics to predict future changes and a Static Scene Propagation module for learning spatial-aware latent statics to offer comprehensive scene contexts. We additionally introduce a Task Prompt to decouple task-aware features for various downstream tasks. The experiments demonstrate that DriveWorld delivers promising results on various autonomous driving tasks. When pre-trained with the OpenScene dataset, DriveWorld achieves a 7.5% increase in mAP for 3D object detection, a 3.0% increase in IoU for online mapping, a 5.0% increase in AMOTA for multi-object tracking, a 0.1m decrease in minADE for motion forecasting, a 3.0% increase in IoU for occupancy prediction, and a 0.34m reduction in average L2 error for planning.
UniWorld: Autonomous Driving Pre-training via World Models
Aug 14, 2023In this paper, we draw inspiration from Alberto Elfes' pioneering work in 1989, where he introduced the concept of the occupancy grid as World Models for robots. We imbue the robot with a spatial-temporal world model, termed UniWorld, to perceive its surroundings and predict the future behavior of other participants. UniWorld involves initially predicting 4D geometric occupancy as the World Models for foundational stage and subsequently fine-tuning on downstream tasks. UniWorld can estimate missing information concerning the world state and predict plausible future states of the world. Besides, UniWorld's pre-training process is label-free, enabling the utilization of massive amounts of image-LiDAR pairs to build a Foundational Model.The proposed unified pre-training framework demonstrates promising results in key tasks such as motion prediction, multi-camera 3D object detection, and surrounding semantic scene completion. When compared to monocular pre-training methods on the nuScenes dataset, UniWorld shows a significant improvement of about 1.5% in IoU for motion prediction, 2.0% in mAP and 2.0% in NDS for multi-camera 3D object detection, as well as a 3% increase in mIoU for surrounding semantic scene completion. By adopting our unified pre-training method, a 25% reduction in 3D training annotation costs can be achieved, offering significant practical value for the implementation of real-world autonomous driving. Codes are publicly available at https://github.com/chaytonmin/UniWorld.
Contrastive Label Disambiguation for Self-Supervised Terrain Traversability Learning in Off-Road Environments
Jul 06, 2023



Discriminating the traversability of terrains is a crucial task for autonomous driving in off-road environments. However, it is challenging due to the diverse, ambiguous, and platform-specific nature of off-road traversability. In this paper, we propose a novel self-supervised terrain traversability learning framework, utilizing a contrastive label disambiguation mechanism. Firstly, weakly labeled training samples with pseudo labels are automatically generated by projecting actual driving experiences onto the terrain models constructed in real time. Subsequently, a prototype-based contrastive representation learning method is designed to learn distinguishable embeddings, facilitating the self-supervised updating of those pseudo labels. As the iterative interaction between representation learning and pseudo label updating, the ambiguities in those pseudo labels are gradually eliminated, enabling the learning of platform-specific and task-specific traversability without any human-provided annotations. Experimental results on the RELLIS-3D dataset and our Gobi Desert driving dataset demonstrate the effectiveness of the proposed method.
Occ-BEV: Multi-Camera Unified Pre-training via 3D Scene Reconstruction
Jun 07, 2023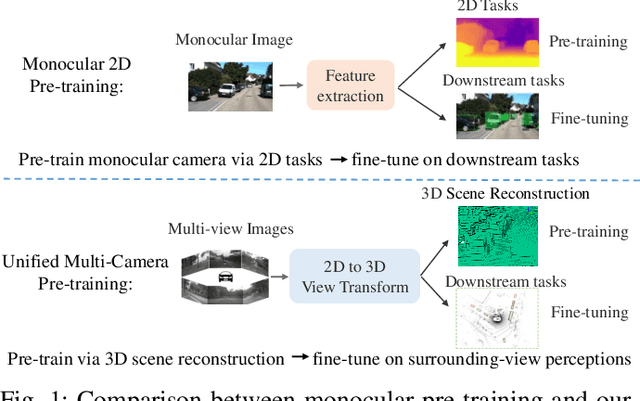



Multi-camera 3D perception has emerged as a prominent research field in autonomous driving, offering a viable and cost-effective alternative to LiDAR-based solutions. However, existing multi-camera algorithms primarily rely on monocular image pre-training, which overlooks the spatial and temporal correlations among different camera views. To address this limitation, we propose the first multi-camera unified pre-training framework called Occ-BEV, which involves initially reconstructing the 3D scene as the foundational stage and subsequently fine-tuning the model on downstream tasks. Specifically, a 3D decoder is designed for leveraging Bird's Eye View (BEV) features from multi-view images to predict the 3D geometric occupancy to enable the model to capture a more comprehensive understanding of the 3D environment. A significant benefit of Occ-BEV is its capability of utilizing a considerable volume of unlabeled image-LiDAR pairs for pre-training purposes. The proposed multi-camera unified pre-training framework demonstrates promising results in key tasks such as multi-camera 3D object detection and surrounding semantic scene completion. When compared to monocular pre-training methods on the nuScenes dataset, Occ-BEV shows a significant improvement of about 2.0% in mAP and 2.0% in NDS for multi-camera 3D object detection, as well as a 3% increase in mIoU for surrounding semantic scene completion. Codes are publicly available at https://github.com/chaytonmin/Occ-BEV.
Voxel-MAE: Masked Autoencoders for Pre-training Large-scale Point Clouds
Jun 27, 2022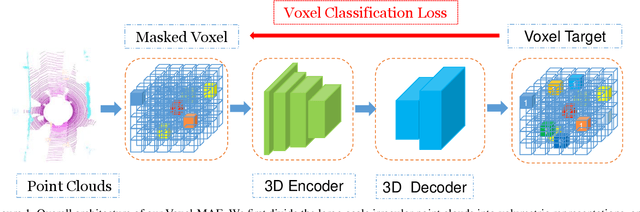
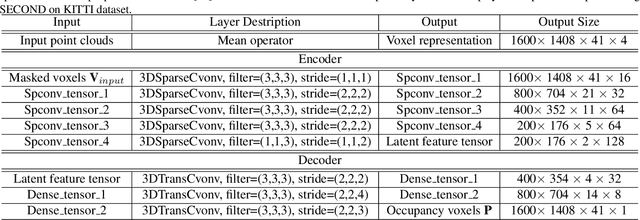
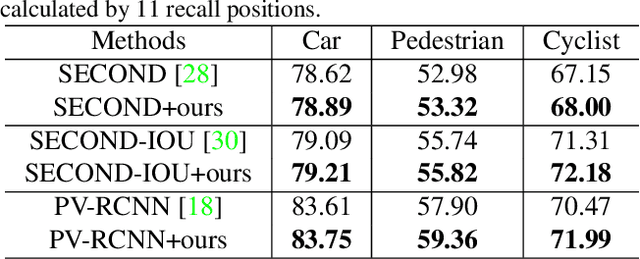
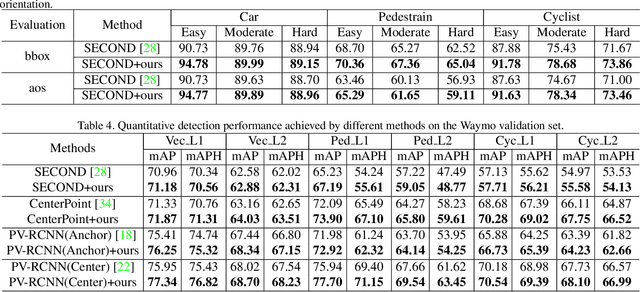
Mask-based pre-training has achieved great success for self-supervised learning in image, video, and language, without manually annotated supervision. However, it has not yet been studied about large-scale point clouds with redundant spatial information in autonomous driving. As the number of large-scale point clouds is huge, it is impossible to reconstruct the input point clouds. In this paper, we propose a mask voxel classification network for large-scale point clouds pre-training. Our key idea is to divide the point clouds into voxel representations and classify whether the voxel contains point clouds. This simple strategy makes the network to be voxel-aware of the object shape, thus improving the performance of the downstream tasks, such as 3D object detection. Our Voxel-MAE with even a 90% masking ratio can still learn representative features for the high spatial redundancy of large-scale point clouds. We also validate the effectiveness of Voxel-MAE in unsupervised domain adaptative tasks, which proves the generalization ability of Voxel-MAE. Our Voxel-MAE proves that it is feasible to pre-train large-scale point clouds without data annotations to enhance the perception ability of the autonomous vehicle. Extensive experiments show great effectiveness of our pre-trained model with 3D object detectors (SECOND, CenterPoint, and PV-RCNN) on two popular datasets (KITTI, Waymo). Codes are publicly available at https://github.com/chaytonmin/Voxel-MAE.
ORFD: A Dataset and Benchmark for Off-Road Freespace Detection
Jun 26, 2022



Freespace detection is an essential component of autonomous driving technology and plays an important role in trajectory planning. In the last decade, deep learning-based free space detection methods have been proved feasible. However, these efforts were focused on urban road environments and few deep learning-based methods were specifically designed for off-road free space detection due to the lack of off-road benchmarks. In this paper, we present the ORFD dataset, which, to our knowledge, is the first off-road free space detection dataset. The dataset was collected in different scenes (woodland, farmland, grassland, and countryside), different weather conditions (sunny, rainy, foggy, and snowy), and different light conditions (bright light, daylight, twilight, darkness), which totally contains 12,198 LiDAR point cloud and RGB image pairs with the traversable area, non-traversable area and unreachable area annotated in detail. We propose a novel network named OFF-Net, which unifies Transformer architecture to aggregate local and global information, to meet the requirement of large receptive fields for free space detection tasks. We also propose the cross-attention to dynamically fuse LiDAR and RGB image information for accurate off-road free space detection. Dataset and code are publicly available athttps://github.com/chaytonmin/OFF-Net.
Trajectory Prediction for Autonomous Driving with Topometric Map
May 09, 2021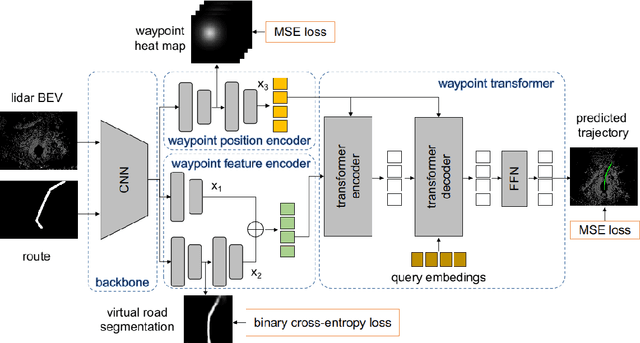
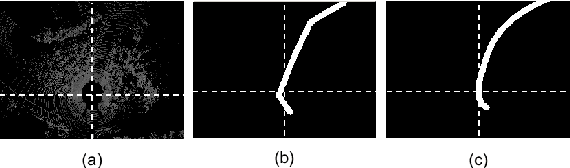
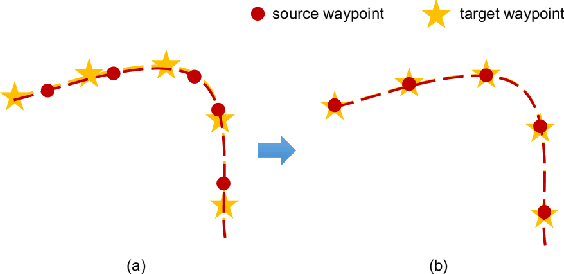
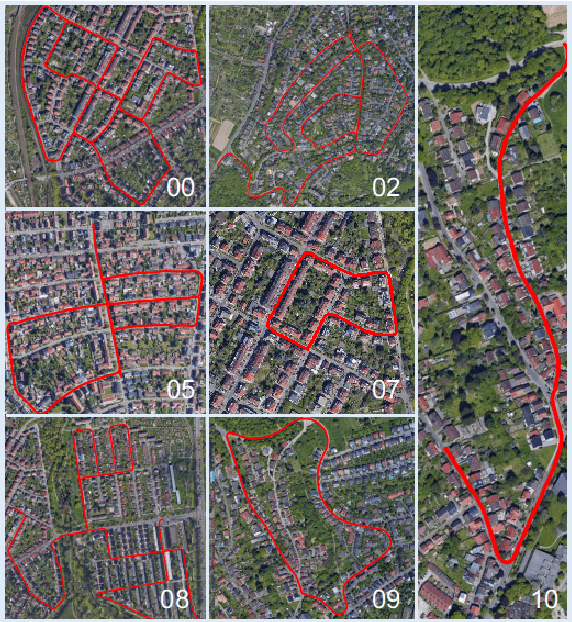
State-of-the-art autonomous driving systems rely on high definition (HD) maps for localization and navigation. However, building and maintaining HD maps is time-consuming and expensive. Furthermore, the HD maps assume structured environment such as the existence of major road and lanes, which are not present in rural areas. In this work, we propose an end-to-end transformer networks based approach for map-less autonomous driving. The proposed model takes raw LiDAR data and noisy topometric map as input and produces precise local trajectory for navigation. We demonstrate the effectiveness of our method in real-world driving data, including both urban and rural areas. The experimental results show that the proposed method outperforms state-of-the-art multimodal methods and is robust to the perturbations of the topometric map. The code of the proposed method is publicly available at \url{https://github.com/Jiaolong/trajectory-prediction}.
Attentional Graph Neural Network for Parking-slot Detection
Apr 06, 2021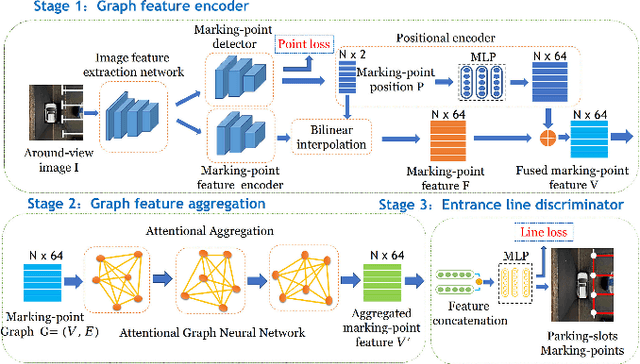
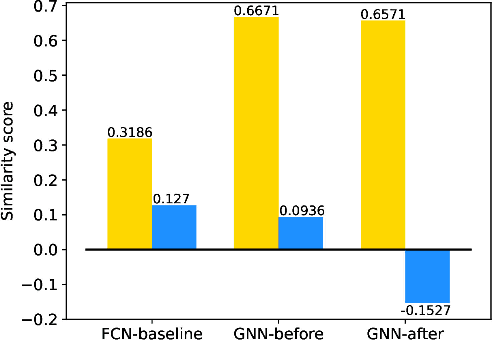

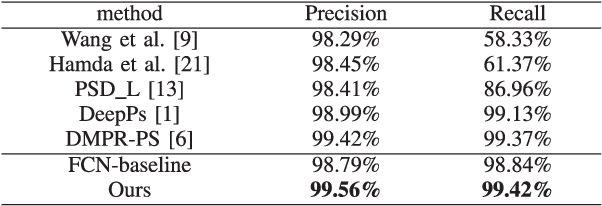
Deep learning has recently demonstrated its promising performance for vision-based parking-slot detection. However, very few existing methods explicitly take into account learning the link information of the marking-points, resulting in complex post-processing and erroneous detection. In this paper, we propose an attentional graph neural network based parking-slot detection method, which refers the marking-points in an around-view image as graph-structured data and utilize graph neural network to aggregate the neighboring information between marking-points. Without any manually designed post-processing, the proposed method is end-to-end trainable. Extensive experiments have been conducted on public benchmark dataset, where the proposed method achieves state-of-the-art accuracy. Code is publicly available at \url{https://github.com/Jiaolong/gcn-parking-slot}.
* Accepted by RAL