 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Label Disambiguation for Self-Supervised Terrain Traversability Learning in Off-Road Environments
Jul 06, 2023



Discriminating the traversability of terrains is a crucial task for autonomous driving in off-road environments. However, it is challenging due to the diverse, ambiguous, and platform-specific nature of off-road traversability. In this paper, we propose a novel self-supervised terrain traversability learning framework, utilizing a contrastive label disambiguation mechanism. Firstly, weakly labeled training samples with pseudo labels are automatically generated by projecting actual driving experiences onto the terrain models constructed in real time. Subsequently, a prototype-based contrastive representation learning method is designed to learn distinguishable embeddings, facilitating the self-supervised updating of those pseudo labels. As the iterative interaction between representation learning and pseudo label updating, the ambiguities in those pseudo labels are gradually eliminated, enabling the learning of platform-specific and task-specific traversability without any human-provided annotations. Experimental results on the RELLIS-3D dataset and our Gobi Desert driving dataset demonstrate the effectiveness of the proposed method.
Learning Task-preferred Inference Routes for Gradient De-conflict in Multi-output DNNs
May 31, 2023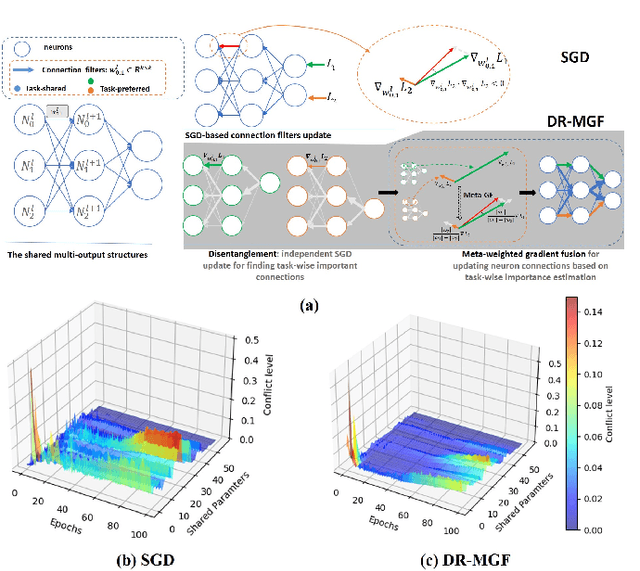

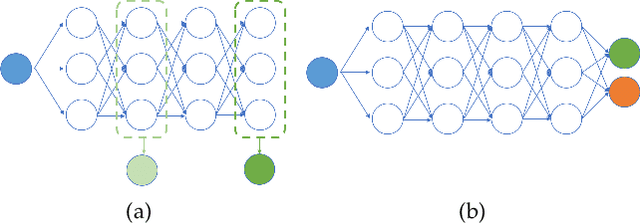

Multi-output deep neural networks(MONs) contain multiple task branches, and these tasks usually share partial network filters that lead to the entanglement of different task inference routes. Due to the inconsistent optimization objectives, the task gradients used for training MONs will interfere with each other on the shared routes, which will decrease the overall model performance. To address this issue, we propose a novel gradient de-conflict algorithm named DR-MGF(Dynamic Routes and Meta-weighted Gradient Fusion) in this work. Different from existing de-conflict methods, DR-MGF achieves gradient de-conflict in MONs by learning task-preferred inference routes. The proposed method is motivated by our experimental findings: the shared filters are not equally important to different tasks. By designing the learnable task-specific importance variables, DR-MGF evaluates the importance of filters for different tasks. Through making the dominances of tasks over filters be proportional to the task-specific importance of filters, DR-MGF can effectively reduce the inter-task interference. The task-specific importance variables ultimately determine task-preferred inference routes at the end of training iterations. Extensive experimental results on CIFAR, ImageNet, and NYUv2 illustrate that DR-MGF outperforms the existing de-conflict methods both in prediction accuracy and convergence speed of MONs. Furthermore, DR-MGF can be extended to general MONs without modifying the overall network structures.
Interpolation-based Contrastive Learning for Few-Label Semi-Supervised Learning
Feb 24, 2022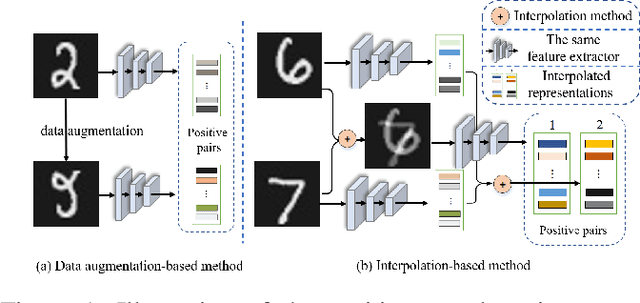

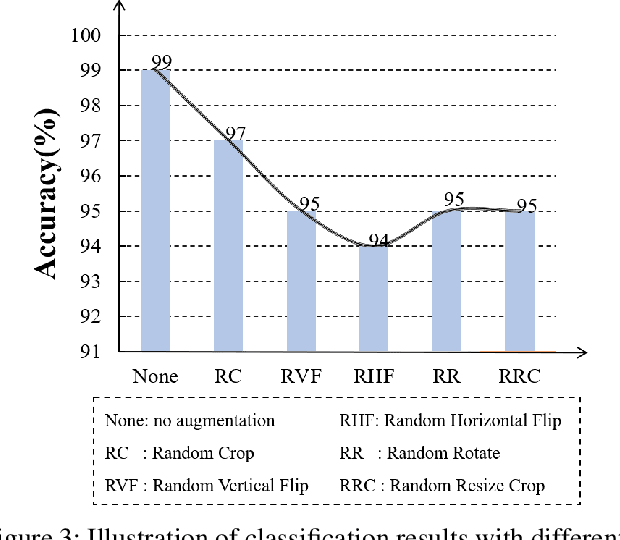
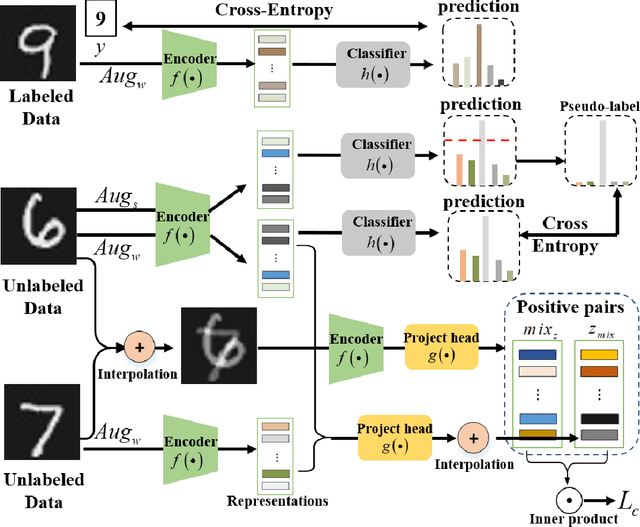
Semi-supervised learning (SSL) has long been proved to be an effective technique to construct powerful models with limited labels. In the existing literature, consistency regularization-based methods, which force the perturbed samples to have similar predictions with the original ones have attracted much attention for their promising accuracy. However, we observe that, the performance of such methods decreases drastically when the labels get extremely limited, e.g., 2 or 3 labels for each category. Our empirical study finds that the main problem lies with the drifting of semantic information in the procedure of data augmentation. The problem can be alleviated when enough supervision is provided. However, when little guidance is available, the incorrect regularization would mislead the network and undermine the performance of the algorithm. To tackle the problem, we (1) propose an interpolation-based method to construct more reliable positive sample pairs; (2) design a novel contrastive loss to guide the embedding of the learned network to change linearly between samples so as to improve the discriminative capability of the network by enlarging the margin decision boundaries. Since no destructive regularization is introduced, the performance of our proposed algorithm is largely improved. Specifically, the proposed algorithm outperforms the second best algorithm (Comatch) with 5.3% by achieving 88.73% classification accuracy when only two labels are available for each class on the CIFAR-10 dataset. Moreover, we further prove the generality of the proposed method by improving the performance of the existing state-of-the-art algorithms considerably with our proposed strategy.