 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpolation-based Contrastive Learning for Few-Label Semi-Supervised Learning
Paper and Code
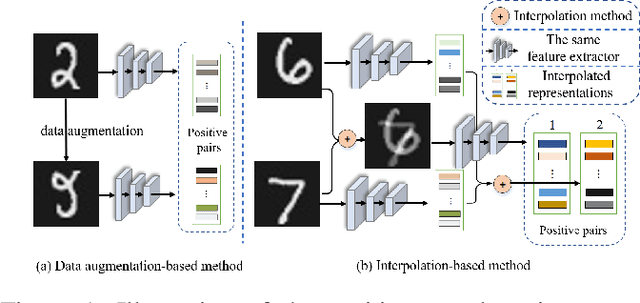

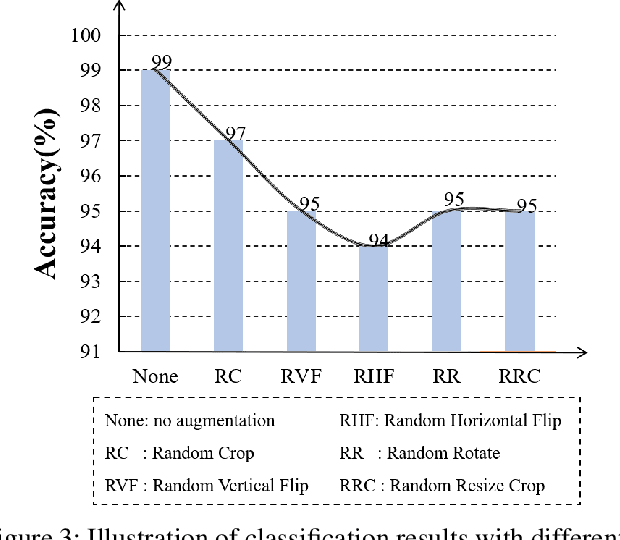
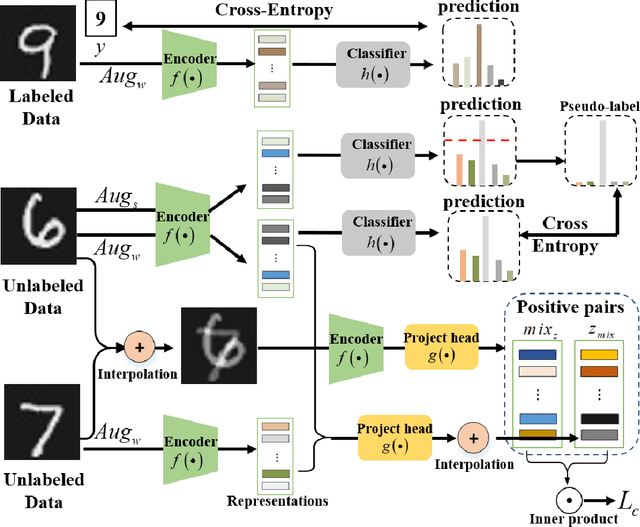
Semi-supervised learning (SSL) has long been proved to be an effective technique to construct powerful models with limited labels. In the existing literature, consistency regularization-based methods, which force the perturbed samples to have similar predictions with the original ones have attracted much attention for their promising accuracy. However, we observe that, the performance of such methods decreases drastically when the labels get extremely limited, e.g., 2 or 3 labels for each category. Our empirical study finds that the main problem lies with the drifting of semantic information in the procedure of data augmentation. The problem can be alleviated when enough supervision is provided. However, when little guidance is available, the incorrect regularization would mislead the network and undermine the performance of the algorithm. To tackle the problem, we (1) propose an interpolation-based method to construct more reliable positive sample pairs; (2) design a novel contrastive loss to guide the embedding of the learned network to change linearly between samples so as to improve the discriminative capability of the network by enlarging the margin decision boundaries. Since no destructive regularization is introduced, the performance of our proposed algorithm is largely improved. Specifically, the proposed algorithm outperforms the second best algorithm (Comatch) with 5.3% by achieving 88.73% classification accuracy when only two labels are available for each class on the CIFAR-10 dataset. Moreover, we further prove the generality of the proposed method by improving the performance of the existing state-of-the-art algorithms considerably with our proposed strategy.