 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImgCoT: Compressing Long Chain of Thought into Compact Visual Tokens for Efficient Reasoning of Large Language Model
Jan 30, 2026Compressing long chains of thought (CoT) into compact latent tokens is crucial for efficient reasoning with large language models (LLMs). Recent studies employ autoencoders to achieve this by reconstructing textual CoT from latent tokens, thus encoding CoT semantics. However, treating textual CoT as the reconstruction target forces latent tokens to preserve surface-level linguistic features (e.g., word choice and syntax), introducing a strong linguistic inductive bias that prioritizes linguistic form over reasoning structure and limits logical abstraction. Thus, we propose ImgCoT that replaces the reconstruction target from textual CoT to the visual CoT obtained by rendering CoT into images. This substitutes linguistic bias with spatial inductive bias, i.e., a tendency to model spatial layouts of the reasoning steps in visual CoT, enabling latent tokens to better capture global reasoning structure. Moreover, although visual latent tokens encode abstract reasoning structure, they may blur reasoning details. We thus propose a loose ImgCoT, a hybrid reasoning that augments visual latent tokens with a few key textual reasoning steps, selected based on low token log-likelihood. This design allows LLMs to retain both global reasoning structure and fine-grained reasoning details with fewer tokens than the complete CoT. Extensive experiments across multiple datasets and LLMs demonstrate the effectiveness of the two versions of ImgCoT.
Deep Temporal Graph Clustering: A Comprehensive Benchmark and Datasets
Jan 19, 2026Temporal Graph Clustering (TGC) is a new task with little attention, focusing on node clustering in temporal graphs. Compared with existing static graph clustering, it can find the balance between time requirement and space requirement (Time-Space Balance) through the interaction sequence-based batch-processing pattern. However, there are two major challenges that hinder the development of TGC, i.e., inapplicable clustering techniques and inapplicable datasets. To address these challenges, we propose a comprehensive benchmark, called BenchTGC. Specially, we design a BenchTGC Framework to illustrate the paradigm of temporal graph clustering and improve existing clustering techniques to fit temporal graphs. In addition, we also discuss problems with public temporal graph datasets and develop multiple datasets suitable for TGC task, called BenchTGC Datasets. According to extensive experiments, we not only verify the advantages of BenchTGC, but also demonstrate the necessity and importance of TGC task. We wish to point out that the dynamically changing and complex scenarios in real world are the foundation of temporal graph clustering. The code and data is available at: https://github.com/MGitHubL/BenchTGC.
Skip-Thinking: Chunk-wise Chain-of-Thought Distillation Enable Smaller Language Models to Reason Better and Faster
May 24, 2025Chain-of-thought (CoT) distillation allows a large language model (LLM) to guide a small language model (SLM) in reasoning tasks. Existing methods train the SLM to learn the long rationale in one iteration, resulting in two issues: 1) Long rationales lead to a large token-level batch size during training, making gradients of core reasoning tokens (i.e., the token will directly affect the correctness of subsequent reasoning) over-smoothed as they contribute a tiny fraction of the rationale. As a result, the SLM converges to sharp minima where it fails to grasp the reasoning logic. 2) The response is slow, as the SLM must generate a long rationale before reaching the answer. Therefore, we propose chunk-wise training (CWT), which uses a heuristic search to divide the rationale into internal semantically coherent chunks and focuses SLM on learning from only one chunk per iteration. In this way, CWT naturally isolates non-reasoning chunks that do not involve the core reasoning token (e.g., summary and transitional chunks) from the SLM learning for reasoning chunks, making the fraction of the core reasoning token increase in the corresponding iteration. Based on CWT, skip-thinking training (STT) is proposed. STT makes the SLM automatically skip non-reasoning medium chunks to reach the answer, improving reasoning speed while maintaining accuracy. We validate our approach on a variety of SLMs and multiple reasoning tasks.
Soft Reasoning Paths for Knowledge Graph Completion
May 06, 2025Reasoning paths are reliable information in knowledge graph completion (KGC) in which algorithms can find strong clues of the actual relation between entities. However, in real-world applications, it is difficult to guarantee that computationally affordable paths exist toward all candidate entities. According to our observation, the prediction accuracy drops significantly when paths are absent. To make the proposed algorithm more stable against the missing path circumstances, we introduce soft reasoning paths. Concretely, a specific learnable latent path embedding is concatenated to each relation to help better model the characteristics of the corresponding paths. The combination of the relation and the corresponding learnable embedding is termed a soft path in our paper. By aligning the soft paths with the reasoning paths, a learnable embedding is guided to learn a generalized path representation of the corresponding relation. In addition, we introduce a hierarchical ranking strategy to make full use of information about the entity, relation, path, and soft path to help improve both the efficiency and accuracy of the model. Extensive experimental results illustrate that our algorithm outperforms the compared state-of-the-art algorithms by a notable margin. The code will be made publicly available after the paper is officially accepted.
Knowledge Graph Completion with Relation-Aware Anchor Enhancement
Apr 08, 2025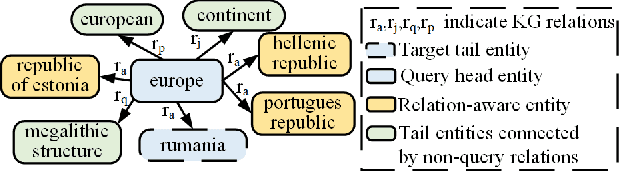
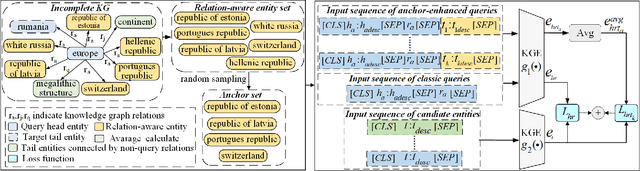
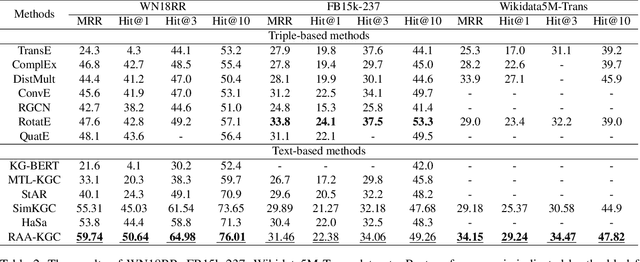
Text-based knowledge graph completion methods take advantage of pre-trained language models (PLM) to enhance intrinsic semantic connections of raw triplets with detailed text descriptions. Typical methods in this branch map an input query (textual descriptions associated with an entity and a relation) and its candidate entities into feature vectors, respectively, and then maximize the probability of valid triples. These methods are gaining promising performance and increasing attention for the rapid development of large language models. According to the property of the language models, the more related and specific context information the input query provides, the more discriminative the resultant embedding will be. In this paper, through observation and validation, we find a neglected fact that the relation-aware neighbors of the head entities in queries could act as effective contexts for more precise link prediction. Driven by this finding, we propose a relation-aware anchor enhanced knowledge graph completion method (RAA-KGC). Specifically, in our method, to provide a reference of what might the target entity be like, we first generate anchor entities within the relation-aware neighborhood of the head entity. Then, by pulling the query embedding towards the neighborhoods of the anchors, it is tuned to be more discriminative for target entity matching. The results of our extensive experiments not only validate the efficacy of RAA-KGC but also reveal that by integrating our relation-aware anchor enhancement strategy, the performance of current leading methods can be notably enhanced without substantial modifications.
Post-Semantic-Thinking: A Robust Strategy to Distill Reasoning Capacity from Large Language Models
Apr 14, 2024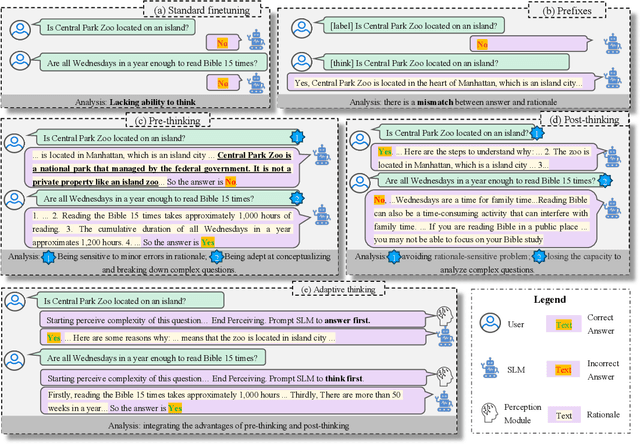
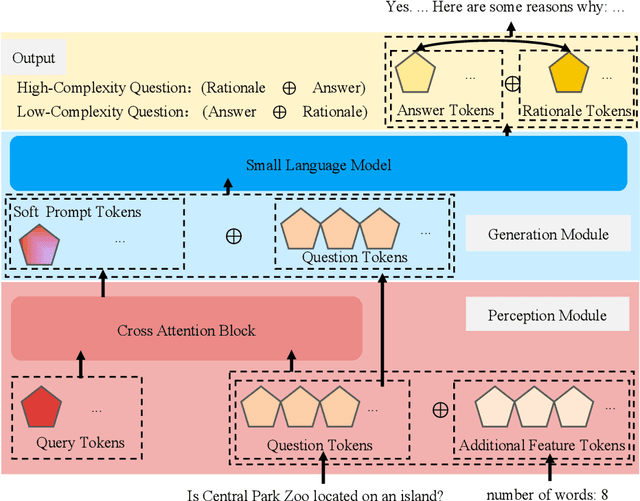
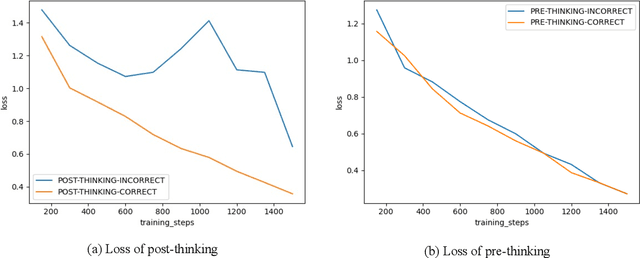
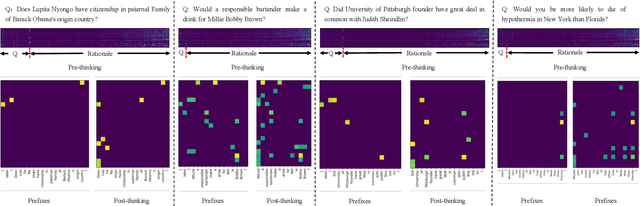
Chain of thought finetuning aims to endow small student models with reasoning capacity to improve their performance towards a specific task by allowing them to imitate the reasoning procedure of large language models (LLMs) beyond simply predicting the answer to the question. However, the existing methods 1) generate rationale before the answer, making their answer correctness sensitive to the hallucination in the rationale;2) force the student model to repeat the exact LLMs rationale expression word-after-word, which could have the model biased towards learning the expression in rationale but count against the model from understanding the core logic behind it. Therefore, we propose a robust Post-Semantic-Thinking (PST) strategy to generate answers before rationale. Thanks to this answer-first setting, 1) the answering procedure can escape from the adverse effects caused by hallucinations in the rationale; 2) the complex reasoning procedure is tightly bound with the relatively concise answer, making the reasoning for questions easier with the prior information in the answer; 3) the efficiency of the method can also benefit from the setting since users can stop the generation right after answers are outputted when inference is conducted. Furthermore, the PST strategy loose the constraint against the generated rationale to be close to the LLMs gold standard in the hidden semantic space instead of the vocabulary space, thus making the small student model better comprehend the semantic reasoning logic in rationale. Extensive experiments conducted across 12 reasoning tasks demonstrate the effectiveness of PST.
One-Step Late Fusion Multi-view Clustering with Compressed Subspace
Jan 03, 2024

Late fusion multi-view clustering (LFMVC) has become a rapidly growing class of methods in the multi-view clustering (MVC) field, owing to its excellent computational speed and clustering performance. One bottleneck faced by existing late fusion methods is that they are usually aligned to the average kernel function, which makes the clustering performance highly dependent on the quality of datasets. Another problem is that they require subsequent k-means clustering after obtaining the consensus partition matrix to get the final discrete labels, and the resulting separation of the label learning and cluster structure optimization processes limits the integrity of these models. To address the above issues, we propose an integrated framework named One-Step Late Fusion Multi-view Clustering with Compressed Subspace (OS-LFMVC-CS). Specifically, we use the consensus subspace to align the partition matrix while optimizing the partition fusion, and utilize the fused partition matrix to guide the learning of discrete labels. A six-step iterative optimization approach with verified convergence is proposed. Sufficient experiments on multiple datasets validate the effectiveness and efficiency of our proposed method.
Anchor-based Multi-view Subspace Clustering with Hierarchical Feature Descent
Oct 11, 2023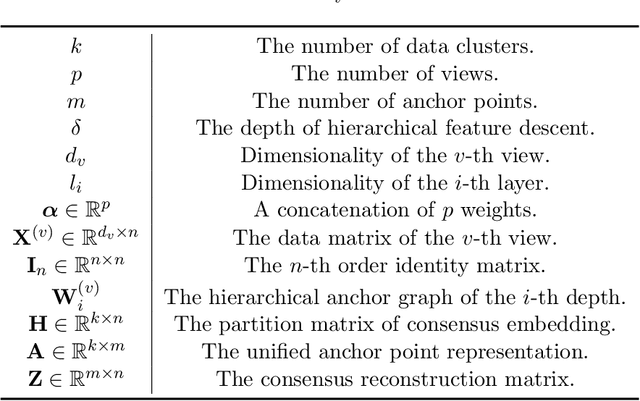
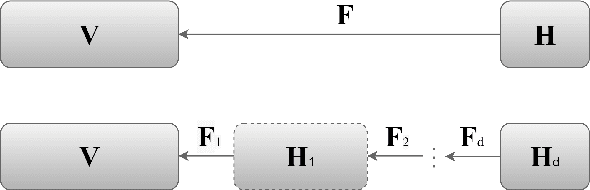
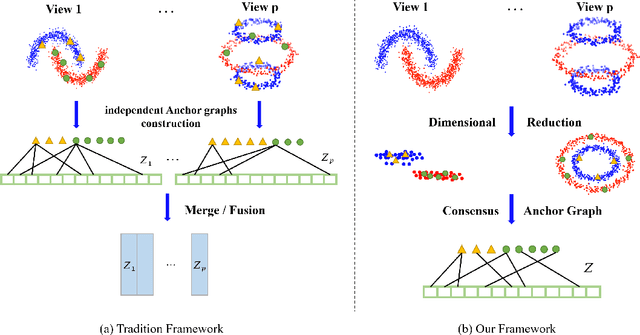
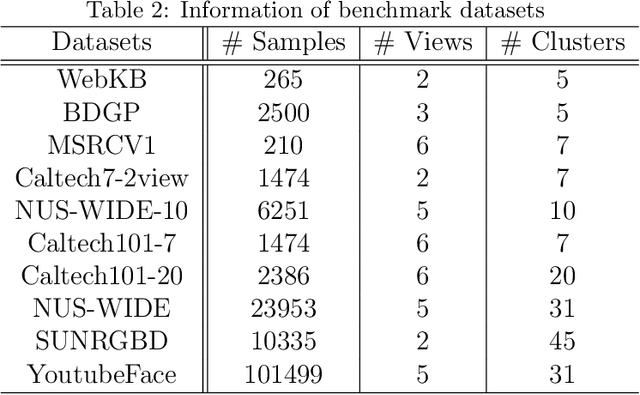
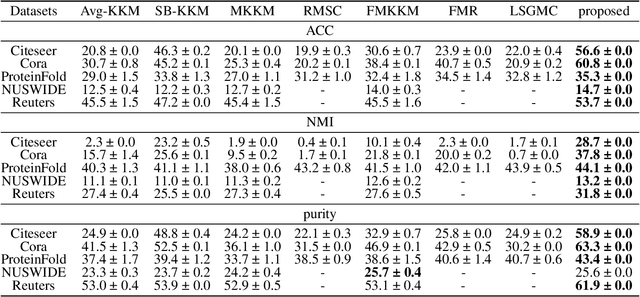
Multi-view clustering has attracted growing attention owing to its capabilities of aggregating information from various sources and its promising horizons in public affairs. Up till now, many advanced approaches have been proposed in recent literature. However, there are several ongoing difficulties to be tackled. One common dilemma occurs while attempting to align the features of different views. We dig out as well as deploy the dependency amongst views through hierarchical feature descent, which leads to a common latent space( STAGE 1). This latent space, for the first time of its kind, is regarded as a 'resemblance space', as it reveals certain correlations and dependencies of different views. To be exact, the one-hot encoding of a category can also be referred to as a resemblance space in its terminal phase. Moreover, due to the intrinsic fact that most of the existing multi-view clustering algorithms stem from k-means clustering and spectral clustering, this results in cubic time complexity w.r.t. the number of the objects. However, we propose Anchor-based Multi-view Subspace Clustering with Hierarchical Feature Descent(MVSC-HFD) to further reduce the computing complexity to linear time cost through a unified sampling strategy in resemblance space( STAGE 2), followed by subspace clustering to learn the representation collectively( STAGE 3). Extensive experimental results on public benchmark datasets demonstrate that our proposed model consistently outperforms the state-of-the-art techniques.
TMac: Temporal Multi-Modal Graph Learning for Acoustic Event Classification
Sep 26, 2023Audiovisual data is everywhere in this digital age, which raises higher requirements for the deep learning models developed on them. To well handle the information of the multi-modal data is the key to a better audiovisual modal. We observe that these audiovisual data naturally have temporal attributes, such as the time information for each frame in the video. More concretely, such data is inherently multi-modal according to both audio and visual cues, which proceed in a strict chronological order. It indicates that temporal information is important in multi-modal acoustic event modeling for both intra- and inter-modal. However, existing methods deal with each modal feature independently and simply fuse them together, which neglects the mining of temporal relation and thus leads to sub-optimal performance. With this motivation, we propose a Temporal Multi-modal graph learning method for Acoustic event Classification, called TMac, by modeling such temporal information via graph learning techniques. In particular, we construct a temporal graph for each acoustic event, dividing its audio data and video data into multiple segments. Each segment can be considered as a node, and the temporal relationships between nodes can be considered as timestamps on their edges. In this case, we can smoothly capture the dynamic information in intra-modal and inter-modal. Several experiments are conducted to demonstrate TMac outperforms other SOTA models in performance. Our code is available at https://github.com/MGitHubL/TMac.
DealMVC: Dual Contrastive Calibration for Multi-view Clustering
Sep 02, 2023


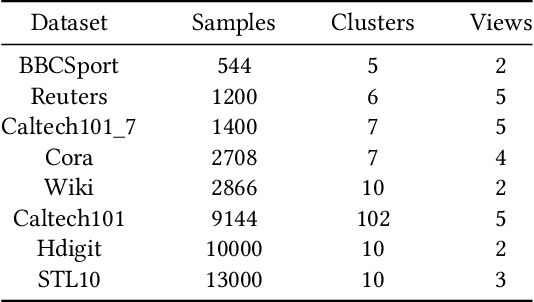
Benefiting from the strong view-consistent information mining capacity, multi-view contrastive clustering has attracted plenty of attention in recent years. However, we observe the following drawback, which limits the clustering performance from further improvement. The existing multi-view models mainly focus on the consistency of the same samples in different views while ignoring the circumstance of similar but different samples in cross-view scenarios. To solve this problem, we propose a novel Dual contrastive calibration network for Multi-View Clustering (DealMVC). Specifically, we first design a fusion mechanism to obtain a global cross-view feature. Then, a global contrastive calibration loss is proposed by aligning the view feature similarity graph and the high-confidence pseudo-label graph. Moreover, to utilize the diversity of multi-view information, we propose a local contrastive calibration loss to constrain the consistency of pair-wise view features. The feature structure is regularized by reliable class information, thus guaranteeing similar samples have similar features in different views. During the training procedure, the interacted cross-view feature is jointly optimized at both local and global levels. In comparison with other state-of-the-art approaches, the comprehensive experimental results obtained from eight benchmark datasets provide substantial validation of the effectiveness and superiority of our algorithm. We release the code of DealMVC at https://github.com/xihongyang1999/DealMVC on GitHub.