 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-Step Late Fusion Multi-view Clustering with Compressed Subspace
Jan 03, 2024

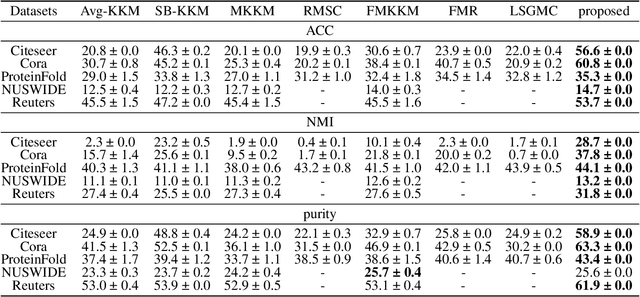
Late fusion multi-view clustering (LFMVC) has become a rapidly growing class of methods in the multi-view clustering (MVC) field, owing to its excellent computational speed and clustering performance. One bottleneck faced by existing late fusion methods is that they are usually aligned to the average kernel function, which makes the clustering performance highly dependent on the quality of datasets. Another problem is that they require subsequent k-means clustering after obtaining the consensus partition matrix to get the final discrete labels, and the resulting separation of the label learning and cluster structure optimization processes limits the integrity of these models. To address the above issues, we propose an integrated framework named One-Step Late Fusion Multi-view Clustering with Compressed Subspace (OS-LFMVC-CS). Specifically, we use the consensus subspace to align the partition matrix while optimizing the partition fusion, and utilize the fused partition matrix to guide the learning of discrete labels. A six-step iterative optimization approach with verified convergence is proposed. Sufficient experiments on multiple datasets validate the effectiveness and efficiency of our proposed method.
Anchor-based Multi-view Subspace Clustering with Hierarchical Feature Descent
Oct 11, 2023
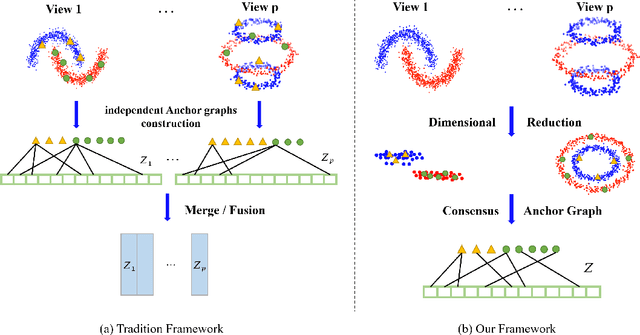
Multi-view clustering has attracted growing attention owing to its capabilities of aggregating information from various sources and its promising horizons in public affairs. Up till now, many advanced approaches have been proposed in recent literature. However, there are several ongoing difficulties to be tackled. One common dilemma occurs while attempting to align the features of different views. We dig out as well as deploy the dependency amongst views through hierarchical feature descent, which leads to a common latent space( STAGE 1). This latent space, for the first time of its kind, is regarded as a 'resemblance space', as it reveals certain correlations and dependencies of different views. To be exact, the one-hot encoding of a category can also be referred to as a resemblance space in its terminal phase. Moreover, due to the intrinsic fact that most of the existing multi-view clustering algorithms stem from k-means clustering and spectral clustering, this results in cubic time complexity w.r.t. the number of the objects. However, we propose Anchor-based Multi-view Subspace Clustering with Hierarchical Feature Descent(MVSC-HFD) to further reduce the computing complexity to linear time cost through a unified sampling strategy in resemblance space( STAGE 2), followed by subspace clustering to learn the representation collectively( STAGE 3). Extensive experimental results on public benchmark datasets demonstrate that our proposed model consistently outperforms the state-of-the-art techniques.