 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupled Travel Planning with Behavior Forest
Apr 23, 2026Behavior sequences, composed of executable steps, serve as the operational foundation for multi-constraint planning problems such as travel planning. In such tasks, each planning step is not only constrained locally but also influenced by global constraints spanning multiple subtasks, leading to a tightly coupled and complex decision process. Existing travel planning methods typically rely on a single decision space that entangles all subtasks and constraints, failing to distinguish between locally acting constraints within a subtask and global constraints that span multiple subtasks. Consequently, the model is forced to jointly reason over local and global constraints at each decision step, increasing the reasoning burden and reducing planning efficiency. To address this problem, we propose the Behavior Forest method. Specifically, our approach structures the decision-making process into a forest of parallel behavior trees, where each behavior tree is responsible for a subtask. A global coordination mechanism is introduced to orchestrate the interactions among these trees, enabling modular and coherent travel planning. Within this framework, large language models are embedded as decision engines within behavior tree nodes, performing localized reasoning conditioned on task-specific constraints to generate candidate subplans and adapt decisions based on coordination feedback. The behavior trees, in turn, provide an explicit control structure that guides LLM generation. This design decouples complex tasks and constraints into manageable subspaces, enabling task-specific reasoning and reducing the cognitive load of LLM. Experimental results show that our method outperforms state-of-the-art methods by 6.67% on the TravelPlanner and by 11.82% on the ChinaTravel benchmarks, demonstrating its effectiveness in increasing LLM performance for complex multi-constraint travel planning.
ImgCoT: Compressing Long Chain of Thought into Compact Visual Tokens for Efficient Reasoning of Large Language Model
Jan 30, 2026Compressing long chains of thought (CoT) into compact latent tokens is crucial for efficient reasoning with large language models (LLMs). Recent studies employ autoencoders to achieve this by reconstructing textual CoT from latent tokens, thus encoding CoT semantics. However, treating textual CoT as the reconstruction target forces latent tokens to preserve surface-level linguistic features (e.g., word choice and syntax), introducing a strong linguistic inductive bias that prioritizes linguistic form over reasoning structure and limits logical abstraction. Thus, we propose ImgCoT that replaces the reconstruction target from textual CoT to the visual CoT obtained by rendering CoT into images. This substitutes linguistic bias with spatial inductive bias, i.e., a tendency to model spatial layouts of the reasoning steps in visual CoT, enabling latent tokens to better capture global reasoning structure. Moreover, although visual latent tokens encode abstract reasoning structure, they may blur reasoning details. We thus propose a loose ImgCoT, a hybrid reasoning that augments visual latent tokens with a few key textual reasoning steps, selected based on low token log-likelihood. This design allows LLMs to retain both global reasoning structure and fine-grained reasoning details with fewer tokens than the complete CoT. Extensive experiments across multiple datasets and LLMs demonstrate the effectiveness of the two versions of ImgCoT.
Deep Temporal Graph Clustering: A Comprehensive Benchmark and Datasets
Jan 19, 2026Temporal Graph Clustering (TGC) is a new task with little attention, focusing on node clustering in temporal graphs. Compared with existing static graph clustering, it can find the balance between time requirement and space requirement (Time-Space Balance) through the interaction sequence-based batch-processing pattern. However, there are two major challenges that hinder the development of TGC, i.e., inapplicable clustering techniques and inapplicable datasets. To address these challenges, we propose a comprehensive benchmark, called BenchTGC. Specially, we design a BenchTGC Framework to illustrate the paradigm of temporal graph clustering and improve existing clustering techniques to fit temporal graphs. In addition, we also discuss problems with public temporal graph datasets and develop multiple datasets suitable for TGC task, called BenchTGC Datasets. According to extensive experiments, we not only verify the advantages of BenchTGC, but also demonstrate the necessity and importance of TGC task. We wish to point out that the dynamically changing and complex scenarios in real world are the foundation of temporal graph clustering. The code and data is available at: https://github.com/MGitHubL/BenchTGC.
A General Anchor-Based Framework for Scalable Fair Clustering
Nov 13, 2025Fair clustering is crucial for mitigating bias in unsupervised learning, yet existing algorithms often suffer from quadratic or super-quadratic computational complexity, rendering them impractical for large-scale datasets. To bridge this gap, we introduce the Anchor-based Fair Clustering Framework (AFCF), a novel, general, and plug-and-play framework that empowers arbitrary fair clustering algorithms with linear-time scalability. Our approach first selects a small but representative set of anchors using a novel fair sampling strategy. Then, any off-the-shelf fair clustering algorithm can be applied to this small anchor set. The core of our framework lies in a novel anchor graph construction module, where we formulate an optimization problem to propagate labels while preserving fairness. This is achieved through a carefully designed group-label joint constraint, which we prove theoretically ensures that the fairness of the final clustering on the entire dataset matches that of the anchor clustering. We solve this optimization efficiently using an ADMM-based algorithm. Extensive experiments on multiple large-scale benchmarks demonstrate that AFCF drastically accelerates state-of-the-art methods, which reduces computational time by orders of magnitude while maintaining strong clustering performance and fairness guarantees.
Breaking the Gradient Barrier: Unveiling Large Language Models for Strategic Classification
Nov 10, 2025Strategic classification~(SC) explores how individuals or entities modify their features strategically to achieve favorable classification outcomes. However, existing SC methods, which are largely based on linear models or shallow neural networks, face significant limitations in terms of scalability and capacity when applied to real-world datasets with significantly increasing scale, especially in financial services and the internet sector. In this paper, we investigate how to leverage large language models to design a more scalable and efficient SC framework, especially in the case of growing individuals engaged with decision-making processes. Specifically, we introduce GLIM, a gradient-free SC method grounded in in-context learning. During the feed-forward process of self-attention, GLIM implicitly simulates the typical bi-level optimization process of SC, including both the feature manipulation and decision rule optimization. Without fine-tuning the LLMs, our proposed GLIM enjoys the advantage of cost-effective adaptation in dynamic strategic environments. Theoretically, we prove GLIM can support pre-trained LLMs to adapt to a broad range of strategic manipulations. We validate our approach through experiments with a collection of pre-trained LLMs on real-world and synthetic datasets in financial and internet domains, demonstrating that our GLIM exhibits both robustness and efficiency, and offering an effective solution for large-scale SC tasks.
Measure Domain's Gap: A Similar Domain Selection Principle for Multi-Domain Recommendation
May 26, 2025Multi-Domain Recommendation (MDR) achieves the desirable recommendation performance by effectively utilizing the transfer information across different domains. Despite the great success, most existing MDR methods adopt a single structure to transfer complex domain-shared knowledge. However, the beneficial transferring information should vary across different domains. When there is knowledge conflict between domains or a domain is of poor quality, unselectively leveraging information from all domains will lead to a serious Negative Transfer Problem (NTP). Therefore, how to effectively model the complex transfer relationships between domains to avoid NTP is still a direction worth exploring. To address these issues, we propose a simple and dynamic Similar Domain Selection Principle (SDSP) for multi-domain recommendation in this paper. SDSP presents the initial exploration of selecting suitable domain knowledge for each domain to alleviate NTP. Specifically, we propose a novel prototype-based domain distance measure to effectively model the complexity relationship between domains. Thereafter, the proposed SDSP can dynamically find similar domains for each domain based on the supervised signals of the domain metrics and the unsupervised distance measure from the learned domain prototype. We emphasize that SDSP is a lightweight method that can be incorporated with existing MDR methods for better performance while not introducing excessive time overheads. To the best of our knowledge, it is the first solution that can explicitly measure domain-level gaps and dynamically select appropriate domains in the MDR field. Extensive experiments on three datasets demonstrate the effectiveness of our proposed method.
Skip-Thinking: Chunk-wise Chain-of-Thought Distillation Enable Smaller Language Models to Reason Better and Faster
May 24, 2025Chain-of-thought (CoT) distillation allows a large language model (LLM) to guide a small language model (SLM) in reasoning tasks. Existing methods train the SLM to learn the long rationale in one iteration, resulting in two issues: 1) Long rationales lead to a large token-level batch size during training, making gradients of core reasoning tokens (i.e., the token will directly affect the correctness of subsequent reasoning) over-smoothed as they contribute a tiny fraction of the rationale. As a result, the SLM converges to sharp minima where it fails to grasp the reasoning logic. 2) The response is slow, as the SLM must generate a long rationale before reaching the answer. Therefore, we propose chunk-wise training (CWT), which uses a heuristic search to divide the rationale into internal semantically coherent chunks and focuses SLM on learning from only one chunk per iteration. In this way, CWT naturally isolates non-reasoning chunks that do not involve the core reasoning token (e.g., summary and transitional chunks) from the SLM learning for reasoning chunks, making the fraction of the core reasoning token increase in the corresponding iteration. Based on CWT, skip-thinking training (STT) is proposed. STT makes the SLM automatically skip non-reasoning medium chunks to reach the answer, improving reasoning speed while maintaining accuracy. We validate our approach on a variety of SLMs and multiple reasoning tasks.
Soft Reasoning Paths for Knowledge Graph Completion
May 06, 2025Reasoning paths are reliable information in knowledge graph completion (KGC) in which algorithms can find strong clues of the actual relation between entities. However, in real-world applications, it is difficult to guarantee that computationally affordable paths exist toward all candidate entities. According to our observation, the prediction accuracy drops significantly when paths are absent. To make the proposed algorithm more stable against the missing path circumstances, we introduce soft reasoning paths. Concretely, a specific learnable latent path embedding is concatenated to each relation to help better model the characteristics of the corresponding paths. The combination of the relation and the corresponding learnable embedding is termed a soft path in our paper. By aligning the soft paths with the reasoning paths, a learnable embedding is guided to learn a generalized path representation of the corresponding relation. In addition, we introduce a hierarchical ranking strategy to make full use of information about the entity, relation, path, and soft path to help improve both the efficiency and accuracy of the model. Extensive experimental results illustrate that our algorithm outperforms the compared state-of-the-art algorithms by a notable margin. The code will be made publicly available after the paper is officially accepted.
Knowledge Graph Completion with Relation-Aware Anchor Enhancement
Apr 08, 2025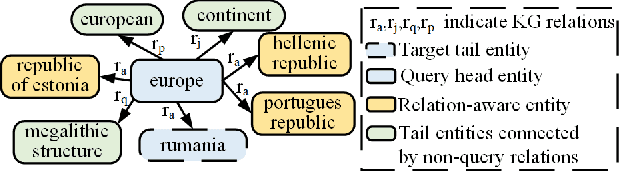
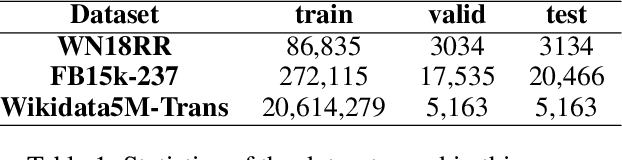
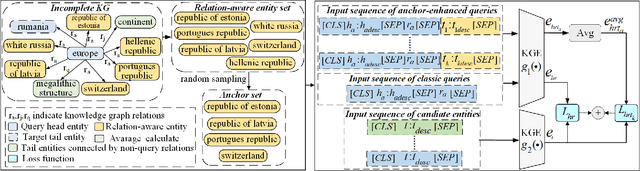
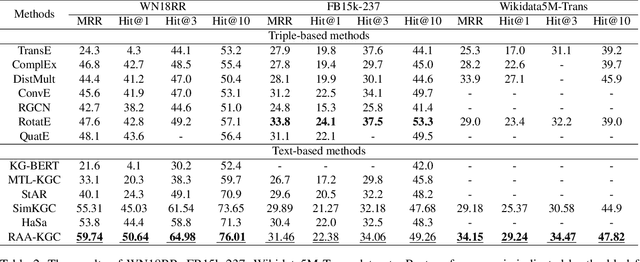
Text-based knowledge graph completion methods take advantage of pre-trained language models (PLM) to enhance intrinsic semantic connections of raw triplets with detailed text descriptions. Typical methods in this branch map an input query (textual descriptions associated with an entity and a relation) and its candidate entities into feature vectors, respectively, and then maximize the probability of valid triples. These methods are gaining promising performance and increasing attention for the rapid development of large language models. According to the property of the language models, the more related and specific context information the input query provides, the more discriminative the resultant embedding will be. In this paper, through observation and validation, we find a neglected fact that the relation-aware neighbors of the head entities in queries could act as effective contexts for more precise link prediction. Driven by this finding, we propose a relation-aware anchor enhanced knowledge graph completion method (RAA-KGC). Specifically, in our method, to provide a reference of what might the target entity be like, we first generate anchor entities within the relation-aware neighborhood of the head entity. Then, by pulling the query embedding towards the neighborhoods of the anchors, it is tuned to be more discriminative for target entity matching. The results of our extensive experiments not only validate the efficacy of RAA-KGC but also reveal that by integrating our relation-aware anchor enhancement strategy, the performance of current leading methods can be notably enhanced without substantial modifications.
Let Synthetic Data Shine: Domain Reassembly and Soft-Fusion for Single Domain Generalization
Mar 17, 2025Single Domain Generalization (SDG) aims to train models with consistent performance across diverse scenarios using data from a single source. While using latent diffusion models (LDMs) show promise in augmenting limited source data, we demonstrate that directly using synthetic data can be detrimental due to significant feature distribution discrepancies between synthetic and real target domains, leading to performance degradation. To address this issue, we propose Discriminative Domain Reassembly and Soft-Fusion (DRSF), a training framework leveraging synthetic data to improve model generalization. We employ LDMs to produce diverse pseudo-target domain samples and introduce two key modules to handle distribution bias. First, Discriminative Feature Decoupling and Reassembly (DFDR) module uses entropy-guided attention to recalibrate channel-level features, suppressing synthetic noise while preserving semantic consistency. Second, Multi-pseudo-domain Soft Fusion (MDSF) module uses adversarial training with latent-space feature interpolation, creating continuous feature transitions between domains. Extensive SDG experiments on object detection and semantic segmentation tasks demonstrate that DRSF achieves substantial performance gains with only marginal computational overhead. Notably, DRSF's plug-and-play architecture enables seamless integration with unsupervised domain adaptation paradigms, underscoring its broad applicability in addressing diverse and real-world domain challenges.