 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiff-V2M: A Hierarchical Conditional Diffusion Model with Explicit Rhythmic Modeling for Video-to-Music Generation
Nov 12, 2025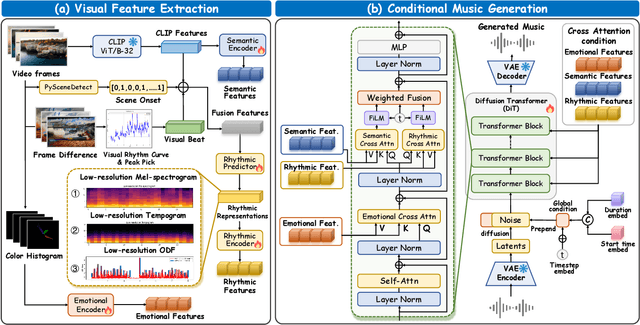
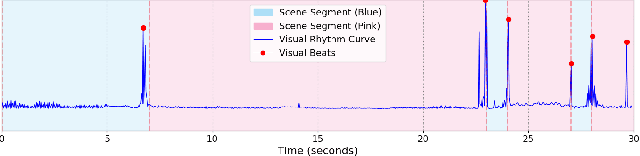
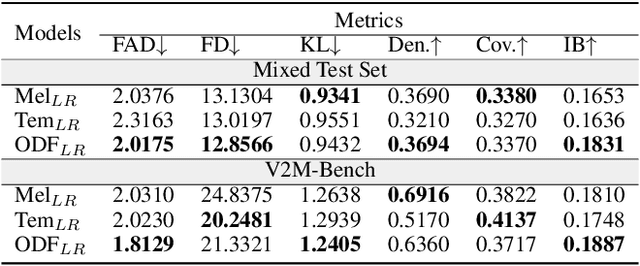
Video-to-music (V2M) generation aims to create music that aligns with visual content. However, two main challenges persist in existing methods: (1) the lack of explicit rhythm modeling hinders audiovisual temporal alignments; (2) effectively integrating various visual features to condition music generation remains non-trivial. To address these issues, we propose Diff-V2M, a general V2M framework based on a hierarchical conditional diffusion model, comprising two core components: visual feature extraction and conditional music generation. For rhythm modeling, we begin by evaluating several rhythmic representations, including low-resolution mel-spectrograms, tempograms, and onset detection functions (ODF), and devise a rhythmic predictor to infer them directly from videos. To ensure contextual and affective coherence, we also extract semantic and emotional features. All features are incorporated into the generator via a hierarchical cross-attention mechanism, where emotional features shape the affective tone via the first layer, while semantic and rhythmic features are fused in the second cross-attention layer. To enhance feature integration, we introduce timestep-aware fusion strategies, including feature-wise linear modulation (FiLM) and weighted fusion, allowing the model to adaptively balance semantic and rhythmic cues throughout the diffusion process. Extensive experiments identify low-resolution ODF as a more effective signal for modeling musical rhythm and demonstrate that Diff-V2M outperforms existing models on both in-domain and out-of-domain datasets, achieving state-of-the-art performance in terms of objective metrics and subjective comparisons. Demo and code are available at https://Tayjsl97.github.io/Diff-V2M-Demo/.
Object Style Diffusion for Generalized Object Detection in Urban Scene
Dec 18, 2024



Object detection is a critical task in computer vision, with applications in various domains such as autonomous driving and urban scene monitoring. However, deep learning-based approaches often demand large volumes of annotated data, which are costly and difficult to acquire, particularly in complex and unpredictable real-world environments. This dependency significantly hampers the generalization capability of existing object detection techniques. To address this issue, we introduce a novel single-domain object detection generalization method, named GoDiff, which leverages a pre-trained model to enhance generalization in unseen domains. Central to our approach is the Pseudo Target Data Generation (PTDG) module, which employs a latent diffusion model to generate pseudo-target domain data that preserves source domain characteristics while introducing stylistic variations. By integrating this pseudo data with source domain data, we diversify the training dataset. Furthermore, we introduce a cross-style instance normalization technique to blend style features from different domains generated by the PTDG module, thereby increasing the detector's robustness. Experimental results demonstrate that our method not only enhances the generalization ability of existing detectors but also functions as a plug-and-play enhancement for other single-domain generalization methods, achieving state-of-the-art performance in autonomous driving scenarios.
Adversarial Detection with a Dynamically Stable System
Nov 11, 2024



Adversarial detection is designed to identify and reject maliciously crafted adversarial examples(AEs) which are generated to disrupt the classification of target models. Presently, various input transformation-based methods have been developed on adversarial example detection, which typically rely on empirical experience and lead to unreliability against new attacks. To address this issue, we propose and conduct a Dynamically Stable System (DSS), which can effectively detect the adversarial examples from normal examples according to the stability of input examples. Particularly, in our paper, the generation of adversarial examples is considered as the perturbation process of a Lyapunov dynamic system, and we propose an example stability mechanism, in which a novel control term is added in adversarial example generation to ensure that the normal examples can achieve dynamic stability while the adversarial examples cannot achieve the stability. Then, based on the proposed example stability mechanism, a Dynamically Stable System (DSS) is proposed, which can utilize the disruption and restoration actions to determine the stability of input examples and detect the adversarial examples through changes in the stability of the input examples. In comparison with existing methods in three benchmark datasets(MNIST, CIFAR10, and CIFAR100), our evaluation results show that our proposed DSS can achieve ROC-AUC values of 99.83%, 97.81% and 94.47%, surpassing the state-of-the-art(SOTA) values of 97.35%, 91.10% and 93.49% in the other 7 methods.
Improving the Transferability of Adversarial Examples via Direction Tuning
Mar 27, 2023In the transfer-based adversarial attacks, adversarial examples are only generated by the surrogate models and achieve effective perturbation in the victim models. Although considerable efforts have been developed on improving the transferability of adversarial examples generated by transfer-based adversarial attacks, our investigation found that, the big deviation between the actual and steepest update directions of the current transfer-based adversarial attacks is caused by the large update step length, resulting in the generated adversarial examples can not converge well. However, directly reducing the update step length will lead to serious update oscillation so that the generated adversarial examples also can not achieve great transferability to the victim models. To address these issues, a novel transfer-based attack, namely direction tuning attack, is proposed to not only decrease the update deviation in the large step length, but also mitigate the update oscillation in the small sampling step length, thereby making the generated adversarial examples converge well to achieve great transferability on victim models. In addition, a network pruning method is proposed to smooth the decision boundary, thereby further decreasing the update oscillation and enhancing the transferability of the generated adversarial examples. The experiment results on ImageNet demonstrate that the average attack success rate (ASR) of the adversarial examples generated by our method can be improved from 87.9\% to 94.5\% on five victim models without defenses, and from 69.1\% to 76.2\% on eight advanced defense methods, in comparison with that of latest gradient-based attacks.
Fuzziness-tuned: Improving the Transferability of Adversarial Examples
Mar 17, 2023



With the development of adversarial attacks, adversairal examples have been widely used to enhance the robustness of the training models on deep neural networks. Although considerable efforts of adversarial attacks on improving the transferability of adversarial examples have been developed, the attack success rate of the transfer-based attacks on the surrogate model is much higher than that on victim model under the low attack strength (e.g., the attack strength $\epsilon=8/255$). In this paper, we first systematically investigated this issue and found that the enormous difference of attack success rates between the surrogate model and victim model is caused by the existence of a special area (known as fuzzy domain in our paper), in which the adversarial examples in the area are classified wrongly by the surrogate model while correctly by the victim model. Then, to eliminate such enormous difference of attack success rates for improving the transferability of generated adversarial examples, a fuzziness-tuned method consisting of confidence scaling mechanism and temperature scaling mechanism is proposed to ensure the generated adversarial examples can effectively skip out of the fuzzy domain. The confidence scaling mechanism and the temperature scaling mechanism can collaboratively tune the fuzziness of the generated adversarial examples through adjusting the gradient descent weight of fuzziness and stabilizing the update direction, respectively. Specifically, the proposed fuzziness-tuned method can be effectively integrated with existing adversarial attacks to further improve the transferability of adverarial examples without changing the time complexity. Extensive experiments demonstrated that fuzziness-tuned method can effectively enhance the transferability of adversarial examples in the latest transfer-based attacks.
A Multi-Stage Triple-Path Method for Speech Separation in Noisy and Reverberant Environments
Mar 07, 2023



In noisy and reverberant environments, the performance of deep learning-based speech separation methods drops dramatically because previous methods are not designed and optimized for such situations. To address this issue, we propose a multi-stage end-to-end learning method that decouples the difficult speech separation problem in noisy and reverberant environments into three sub-problems: speech denoising, separation, and de-reverberation. The probability and speed of searching for the optimal solution of the speech separation model are improved by reducing the solution space. Moreover, since the channel information of the audio sequence in the time domain is crucial for speech separation, we propose a triple-path structure capable of modeling the channel dimension of audio sequences. Experimental results show that the proposed multi-stage triple-path method can improve the performance of speech separation models at the cost of little model parameter increment.
FACM: Correct the Output of Deep Neural Network with Middle Layers Features against Adversarial Samples
Jun 02, 2022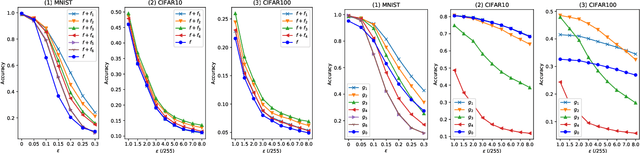
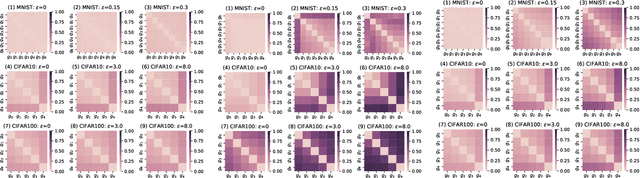


In the strong adversarial attacks against deep neural network (DNN), the output of DNN will be misclassified if and only if the last feature layer of the DNN is completely destroyed by adversarial samples, while our studies found that the middle feature layers of the DNN can still extract the effective features of the original normal category in these adversarial attacks. To this end, in this paper, a middle $\bold{F}$eature layer $\bold{A}$nalysis and $\bold{C}$onditional $\bold{M}$atching prediction distribution (FACM) model is proposed to increase the robustness of the DNN against adversarial samples through correcting the output of DNN with the features extracted by the middle layers of DNN. In particular, the middle $\bold{F}$eature layer $\bold{A}$nalysis (FA) module, the conditional matching prediction distribution (CMPD) module and the output decision module are included in our FACM model to collaboratively correct the classification of adversarial samples. The experiments results show that, our FACM model can significantly improve the robustness of the naturally trained model against various attacks, and our FA model can significantly improve the robustness of the adversarially trained model against white-box attacks with weak transferability and black box attacks where FA model includes the FA module and the output decision module, not the CMPD module.
Mask-Guided Divergence Loss Improves the Generalization and Robustness of Deep Neural Network
Jun 02, 2022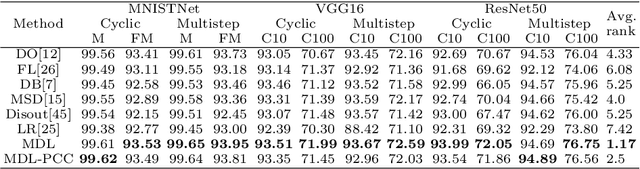
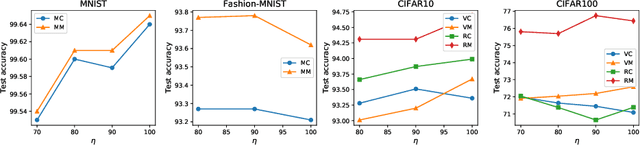
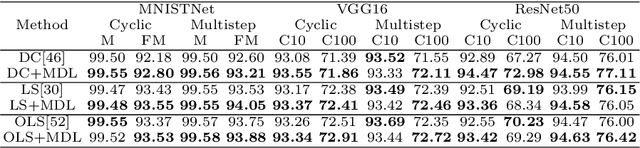
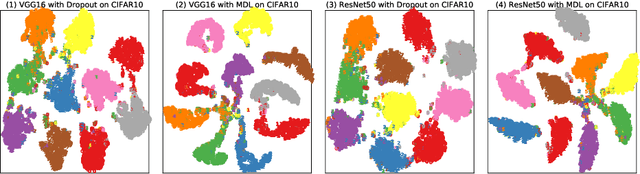
Deep neural network (DNN) with dropout can be regarded as an ensemble model consisting of lots of sub-DNNs (i.e., an ensemble sub-DNN where the sub-DNN is the remaining part of the DNN after dropout), and through increasing the diversity of the ensemble sub-DNN, the generalization and robustness of the DNN can be effectively improved. In this paper, a mask-guided divergence loss function (MDL), which consists of a cross-entropy loss term and an orthogonal term, is proposed to increase the diversity of the ensemble sub-DNN by the added orthogonal term. Particularly, the mask technique is introduced to assist in generating the orthogonal term for avoiding overfitting of the diversity learning. The theoretical analysis and extensive experiments on 4 datasets (i.e., MNIST, FashionMNIST, CIFAR10, and CIFAR100) manifest that MDL can improve the generalization and robustness of standard training and adversarial training. For CIFAR10 and CIFAR100, in standard training, the maximum improvement of accuracy is $1.38\%$ on natural data, $30.97\%$ on FGSM (i.e., Fast Gradient Sign Method) attack, $38.18\%$ on PGD (i.e., Projected Gradient Descent) attack. While in adversarial training, the maximum improvement is $1.68\%$ on natural data, $4.03\%$ on FGSM attack and $2.65\%$ on PGD attack.
Enhancing the Transferability of Adversarial Examples via a Few Queries
May 19, 2022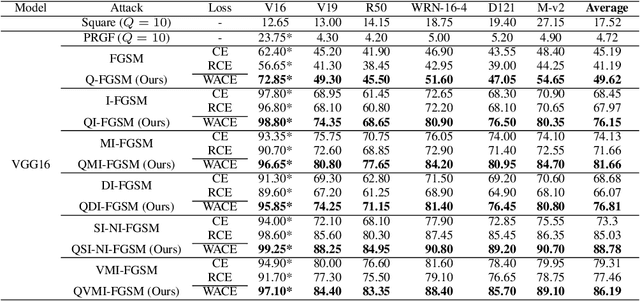
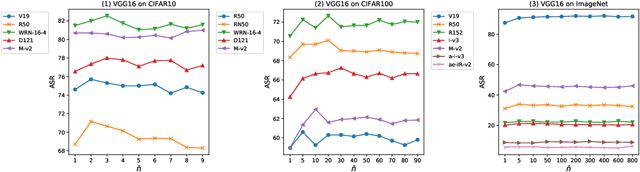
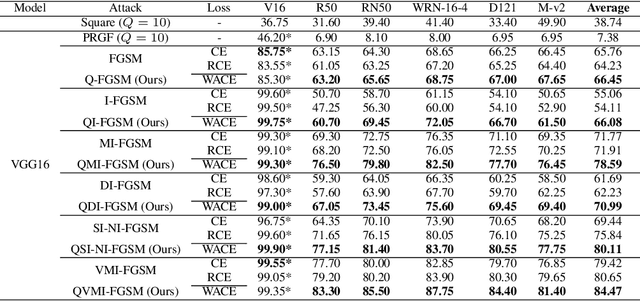
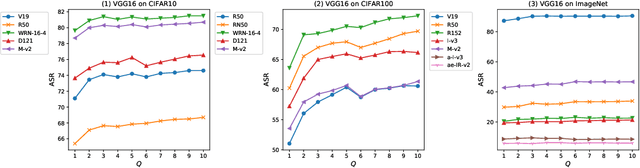
Due to the vulnerability of deep neural networks, the black-box attack has drawn great attention from the community. Though transferable priors decrease the query number of the black-box query attacks in recent efforts, the average number of queries is still larger than 100, which is easily affected by the number of queries limit policy. In this work, we propose a novel method called query prior-based method to enhance the family of fast gradient sign methods and improve their attack transferability by using a few queries. Specifically, for the untargeted attack, we find that the successful attacked adversarial examples prefer to be classified as the wrong categories with higher probability by the victim model. Therefore, the weighted augmented cross-entropy loss is proposed to reduce the gradient angle between the surrogate model and the victim model for enhancing the transferability of the adversarial examples. Theoretical analysis and extensive experiments demonstrate that our method could significantly improve the transferability of gradient-based adversarial attacks on CIFAR10/100 and ImageNet and outperform the black-box query attack with the same few queries.