 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMTDrive: Multi-turn Interactive Reinforcement Learning for Autonomous Driving
Jan 30, 2026Trajectory planning is a core task in autonomous driving, requiring the prediction of safe and comfortable paths across diverse scenarios. Integrating Multi-modal Large Language Models (MLLMs) with Reinforcement Learning (RL) has shown promise in addressing "long-tail" scenarios. However, existing methods are constrained to single-turn reasoning, limiting their ability to handle complex tasks requiring iterative refinement. To overcome this limitation, we present MTDrive, a multi-turn framework that enables MLLMs to iteratively refine trajectories based on environmental feedback. MTDrive introduces Multi-Turn Group Relative Policy Optimization (mtGRPO), which mitigates reward sparsity by computing relative advantages across turns. We further construct an interactive trajectory understanding dataset from closed-loop simulation to support multi-turn training. Experiments on the NAVSIM benchmark demonstrate superior performance compared to existing methods, validating the effectiveness of our multi-turn reasoning paradigm. Additionally, we implement system-level optimizations to reduce data transfer overhead caused by high-resolution images and multi-turn sequences, achieving 2.5x training throughput. Our data, models, and code will be made available soon.
Skipformer: A Skip-and-Recover Strategy for Efficient Speech Recognition
Mar 13, 2024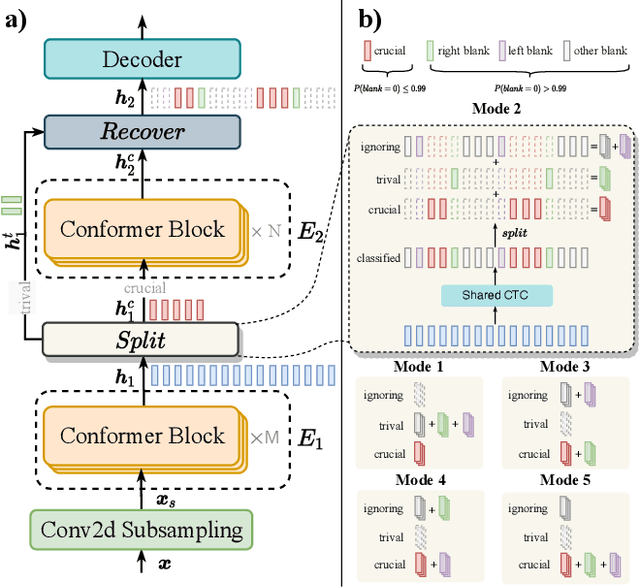
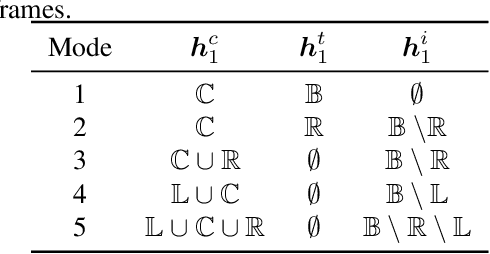
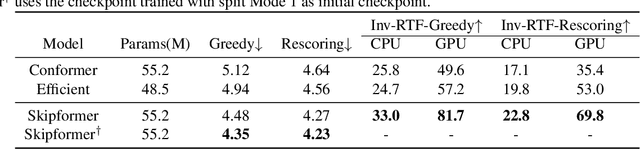
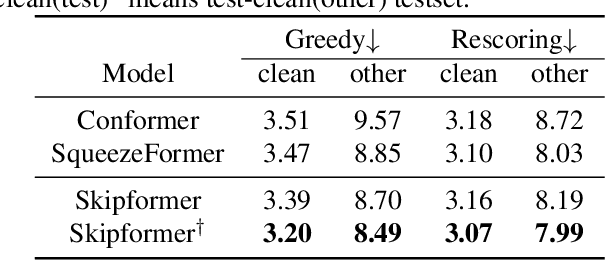
Conformer-based attention models have become the de facto backbone model for Automatic Speech Recognition tasks. A blank symbol is usually introduced to align the input and output sequences for CTC or RNN-T models. Unfortunately, the long input length overloads computational budget and memory consumption quadratically by attention mechanism. In this work, we propose a "Skip-and-Recover" Conformer architecture, named Skipformer, to squeeze sequence input length dynamically and inhomogeneously. Skipformer uses an intermediate CTC output as criteria to split frames into three groups: crucial, skipping and ignoring. The crucial group feeds into next conformer blocks and its output joint with skipping group by original temporal order as the final encoder output. Experiments show that our model reduces the input sequence length by 31 times on Aishell-1 and 22 times on Librispeech corpus. Meanwhile, the model can achieve better recognition accuracy and faster inference speed than recent baseline models. Our code is open-sourced and available online.
Learning a Structural Causal Model for Intuition Reasoning in Conversation
May 28, 2023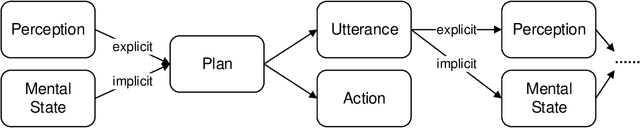
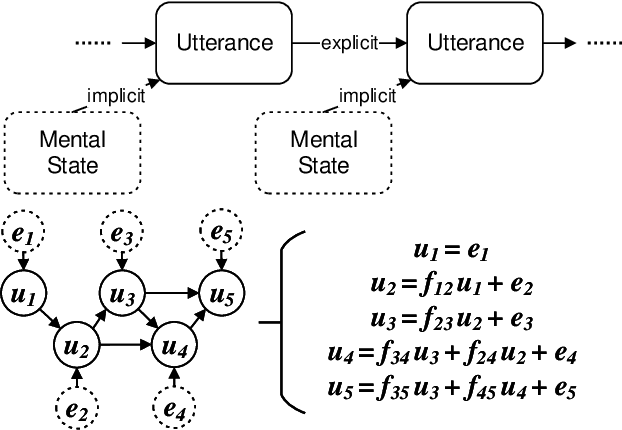

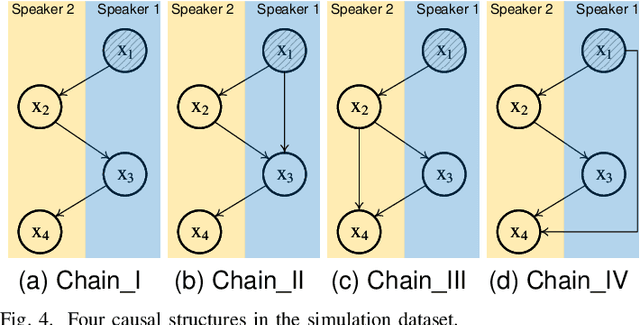
Reasoning, a crucial aspect of NLP research, has not been adequately addressed by prevailing models including Large Language Model. Conversation reasoning, as a critical component of it, remains largely unexplored due to the absence of a well-designed cognitive model. In this paper, inspired by intuition theory on conversation cognition, we develop a conversation cognitive model (CCM) that explains how each utterance receives and activates channels of information recursively. Besides, we algebraically transformed CCM into a structural causal model (SCM) under some mild assumptions, rendering it compatible with various causal discovery methods. We further propose a probabilistic implementation of the SCM for utterance-level relation reasoning. By leveraging variational inference, it explores substitutes for implicit causes, addresses the issue of their unobservability, and reconstructs the causal representations of utterances through the evidence lower bounds. Moreover, we constructed synthetic and simulated datasets incorporating implicit causes and complete cause labels, alleviating the current situation where all available datasets are implicit-causes-agnostic. Extensive experiments demonstrate that our proposed method significantly outperforms existing methods on synthetic, simulated, and real-world datasets. Finally, we analyze the performance of CCM under latent confounders and propose theoretical ideas for addressing this currently unresolved issue.
Affective Reasoning at Utterance Level in Conversations: A Causal Discovery Approach
May 04, 2023
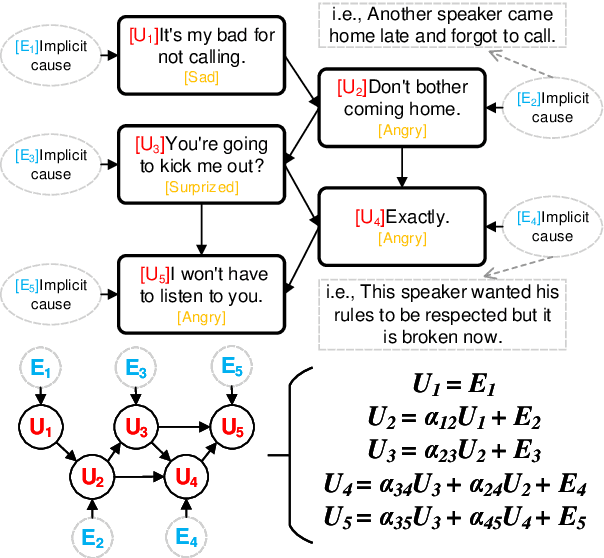


The affective reasoning task is a set of emerging affect-based tasks in conversation, including Emotion Recognition in Conversation (ERC),Emotion-Cause Pair Extraction (ECPE), and Emotion-Cause Span Recognition (ECSR). Existing methods make various assumptions on the apparent relationship while neglecting the essential causal model due to the nonuniqueness of skeletons and unobservability of implicit causes. This paper settled down the above two problems and further proposed Conversational Affective Causal Discovery (CACD). It is a novel causal discovery method showing how to discover causal relationships in a conversation via designing a common skeleton and generating a substitute for implicit causes. CACD contains two steps: (i) building a common centering one graph node causal skeleton for all utterances in variable-length conversations; (ii) Causal Auto-Encoder (CAE) correcting the skeleton to yield causal representation through generated implicit causes and known explicit causes. Comprehensive experiments demonstrate that our novel method significantly outperforms the SOTA baselines in six affect-related datasets on the three tasks.
A Multi-Stage Triple-Path Method for Speech Separation in Noisy and Reverberant Environments
Mar 07, 2023



In noisy and reverberant environments, the performance of deep learning-based speech separation methods drops dramatically because previous methods are not designed and optimized for such situations. To address this issue, we propose a multi-stage end-to-end learning method that decouples the difficult speech separation problem in noisy and reverberant environments into three sub-problems: speech denoising, separation, and de-reverberation. The probability and speed of searching for the optimal solution of the speech separation model are improved by reducing the solution space. Moreover, since the channel information of the audio sequence in the time domain is crucial for speech separation, we propose a triple-path structure capable of modeling the channel dimension of audio sequences. Experimental results show that the proposed multi-stage triple-path method can improve the performance of speech separation models at the cost of little model parameter increment.
Multi-Dimensional and Multi-Scale Modeling for Speech Separation Optimized by Discriminative Learning
Mar 07, 2023


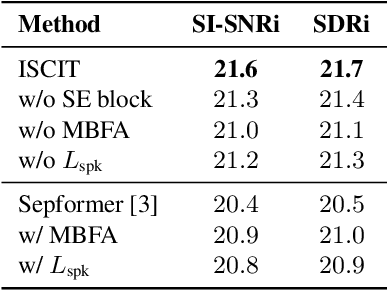
Transformer has shown advanced performance in speech separation, benefiting from its ability to capture global features. However, capturing local features and channel information of audio sequences in speech separation is equally important. In this paper, we present a novel approach named Intra-SE-Conformer and Inter-Transformer (ISCIT) for speech separation. Specifically, we design a new network SE-Conformer that can model audio sequences in multiple dimensions and scales, and apply it to the dual-path speech separation framework. Furthermore, we propose Multi-Block Feature Aggregation to improve the separation effect by selectively utilizing information from the intermediate blocks of the separation network. Meanwhile, we propose a speaker similarity discriminative loss to optimize the speech separation model to address the problem of poor performance when speakers have similar voices. Experimental results on the benchmark datasets WSJ0-2mix and WHAM! show that ISCIT can achieve state-of-the-art results.
Speech Emotion Recognition with Global-Aware Fusion on Multi-scale Feature Representation
Apr 12, 2022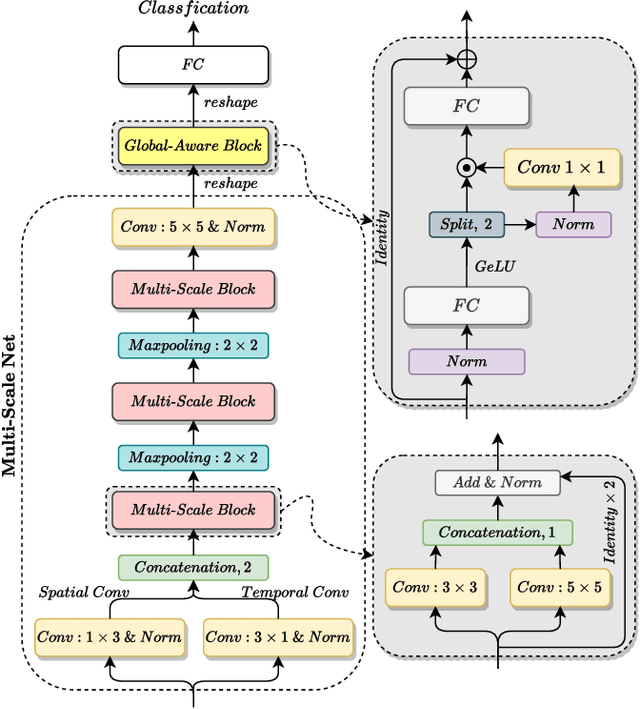
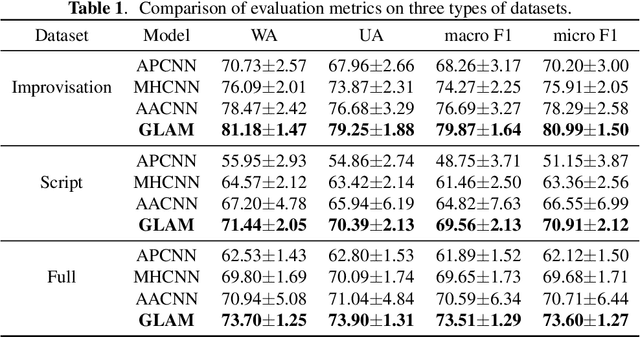


Speech Emotion Recognition (SER) is a fundamental task to predict the emotion label from speech data. Recent works mostly focus on using convolutional neural networks~(CNNs) to learn local attention map on fixed-scale feature representation by viewing time-varied spectral features as images. However, rich emotional feature at different scales and important global information are not able to be well captured due to the limits of existing CNNs for SER. In this paper, we propose a novel GLobal-Aware Multi-scale (GLAM) neural network (The code is available at https://github.com/lixiangucas01/GLAM) to learn multi-scale feature representation with global-aware fusion module to attend emotional information. Specifically, GLAM iteratively utilizes multiple convolutional kernels with different scales to learn multiple feature representation. Then, instead of using attention-based methods, a simple but effective global-aware fusion module is applied to grab most important emotional information globally. Experiments on the benchmark corpus IEMOCAP over four emotions demonstrates the superiority of our proposed model with 2.5% to 4.5% improvements on four common metrics compared to previous state-of-the-art approaches.
SQLFlow: A Bridge between SQL and Machine Learning
Jan 19, 2020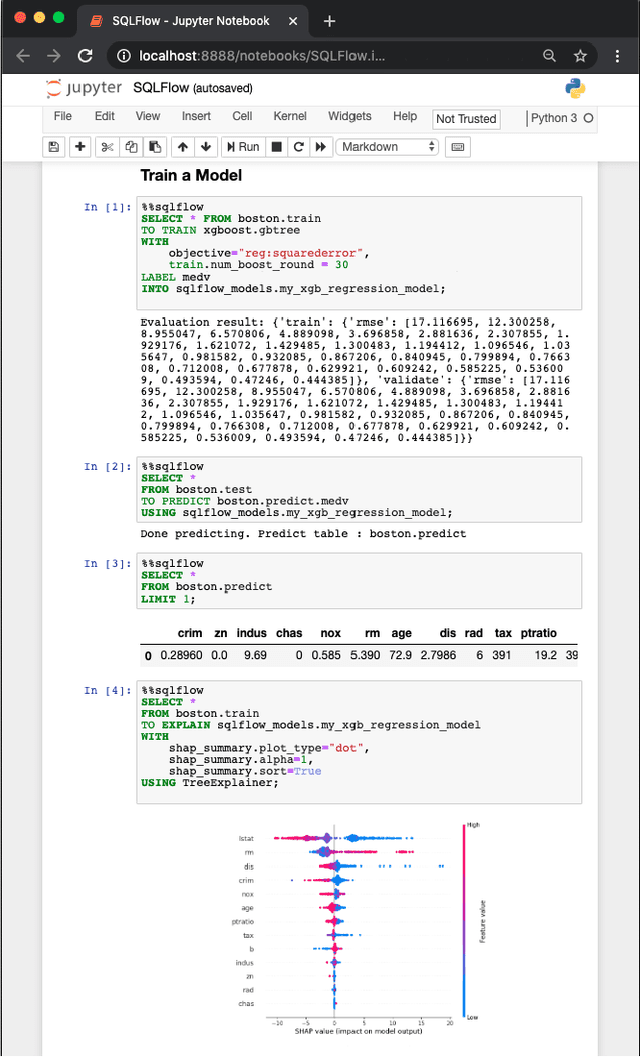

Industrial AI systems are mostly end-to-end machine learning (ML) workflows. A typical recommendation or business intelligence system includes many online micro-services and offline jobs. We describe SQLFlow for developing such workflows efficiently in SQL. SQL enables developers to write short programs focusing on the purpose (what) and ignoring the procedure (how). Previous database systems extended their SQL dialect to support ML. SQLFlow (https://sqlflow.org/sqlflow ) takes another strategy to work as a bridge over various database systems, including MySQL, Apache Hive, and Alibaba MaxCompute, and ML engines like TensorFlow, XGBoost, and scikit-learn. We extended SQL syntax carefully to make the extension working with various SQL dialects. We implement the extension by inventing a collaborative parsing algorithm. SQLFlow is efficient and expressive to a wide variety of ML techniques -- supervised and unsupervised learning; deep networks and tree models; visual model explanation in addition to training and prediction; data processing and feature extraction in addition to ML. SQLFlow compiles a SQL program into a Kubernetes-native workflow for fault-tolerable execution and on-cloud deployment. Current industrial users include Ant Financial, DiDi, and Alibaba Group.