 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkipformer: A Skip-and-Recover Strategy for Efficient Speech Recognition
Paper and Code
Mar 13, 2024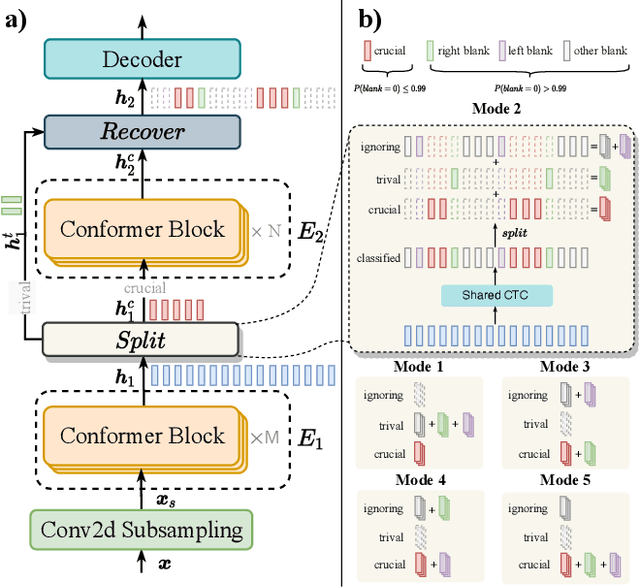
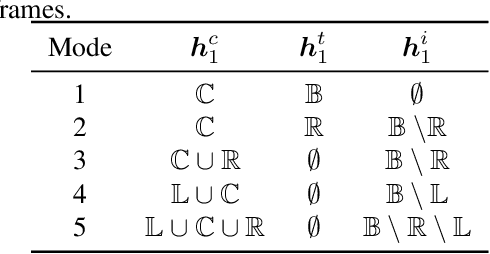
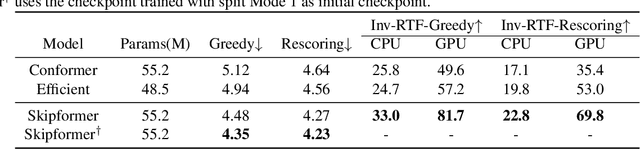
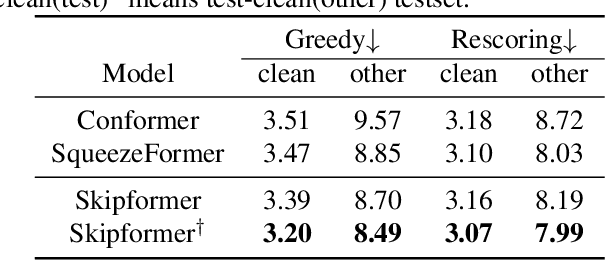
Conformer-based attention models have become the de facto backbone model for Automatic Speech Recognition tasks. A blank symbol is usually introduced to align the input and output sequences for CTC or RNN-T models. Unfortunately, the long input length overloads computational budget and memory consumption quadratically by attention mechanism. In this work, we propose a "Skip-and-Recover" Conformer architecture, named Skipformer, to squeeze sequence input length dynamically and inhomogeneously. Skipformer uses an intermediate CTC output as criteria to split frames into three groups: crucial, skipping and ignoring. The crucial group feeds into next conformer blocks and its output joint with skipping group by original temporal order as the final encoder output. Experiments show that our model reduces the input sequence length by 31 times on Aishell-1 and 22 times on Librispeech corpus. Meanwhile, the model can achieve better recognition accuracy and faster inference speed than recent baseline models. Our code is open-sourced and available online.