 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvolutional-neural-operator-based transfer learning for solving PDEs
Dec 19, 2025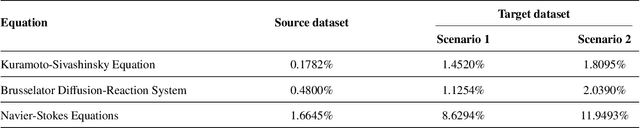
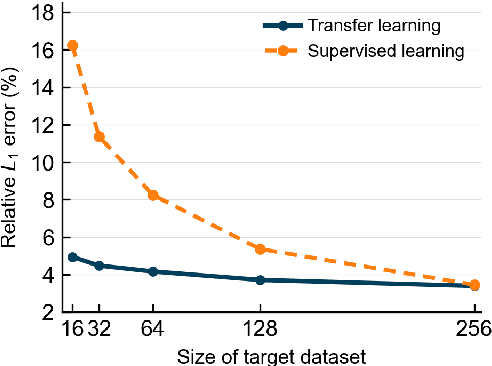
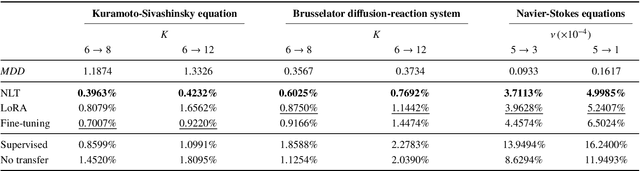
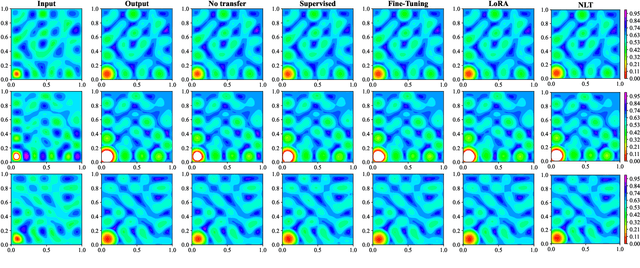
Convolutional neural operator is a CNN-based architecture recently proposed to enforce structure-preserving continuous-discrete equivalence and enable the genuine, alias-free learning of solution operators of PDEs. This neural operator was demonstrated to outperform for certain cases some baseline models such as DeepONet, Fourier neural operator, and Galerkin transformer in terms of surrogate accuracy. The convolutional neural operator, however, seems not to be validated for few-shot learning. We extend the model to few-shot learning scenarios by first pre-training a convolutional neural operator using a source dataset and then adjusting the parameters of the trained neural operator using only a small target dataset. We investigate three strategies for adjusting the parameters of a trained neural operator, including fine-tuning, low-rank adaption, and neuron linear transformation, and find that the neuron linear transformation strategy enjoys the highest surrogate accuracy in solving PDEs such as Kuramoto-Sivashinsky equation, Brusselator diffusion-reaction system, and Navier-Stokes equations.
Skipformer: A Skip-and-Recover Strategy for Efficient Speech Recognition
Mar 13, 2024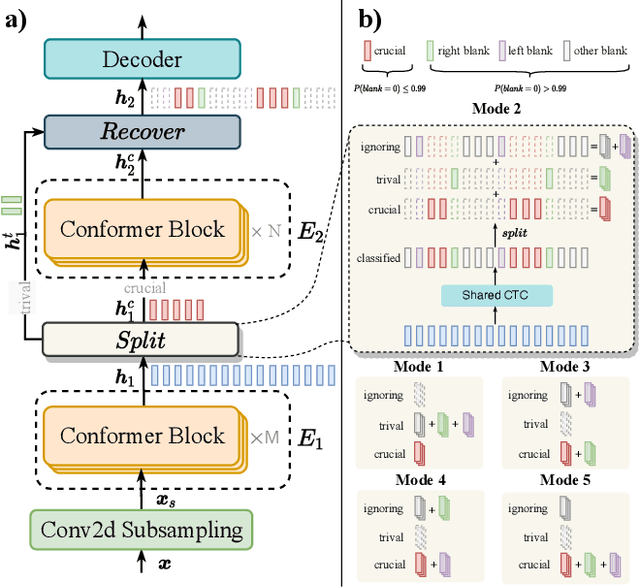
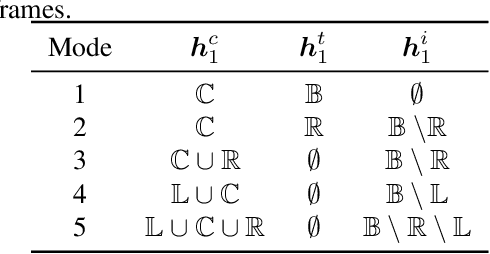
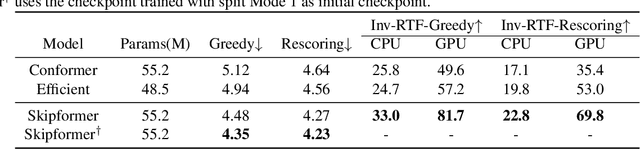
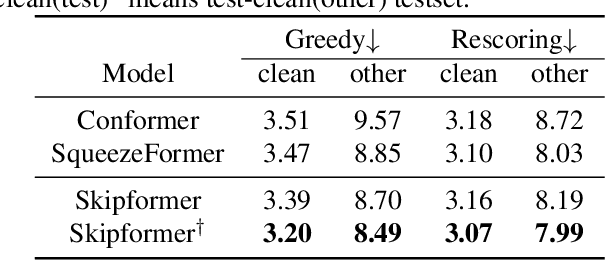
Conformer-based attention models have become the de facto backbone model for Automatic Speech Recognition tasks. A blank symbol is usually introduced to align the input and output sequences for CTC or RNN-T models. Unfortunately, the long input length overloads computational budget and memory consumption quadratically by attention mechanism. In this work, we propose a "Skip-and-Recover" Conformer architecture, named Skipformer, to squeeze sequence input length dynamically and inhomogeneously. Skipformer uses an intermediate CTC output as criteria to split frames into three groups: crucial, skipping and ignoring. The crucial group feeds into next conformer blocks and its output joint with skipping group by original temporal order as the final encoder output. Experiments show that our model reduces the input sequence length by 31 times on Aishell-1 and 22 times on Librispeech corpus. Meanwhile, the model can achieve better recognition accuracy and faster inference speed than recent baseline models. Our code is open-sourced and available online.
Key Frame Mechanism For Efficient Conformer Based End-to-end Speech Recognition
Oct 28, 2023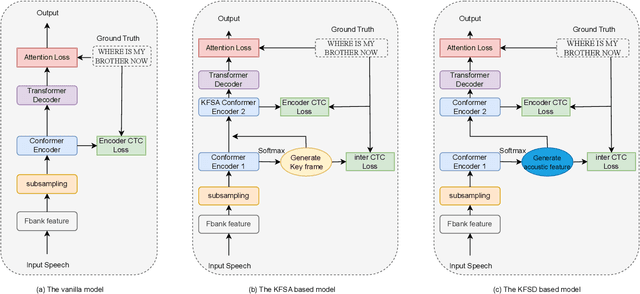
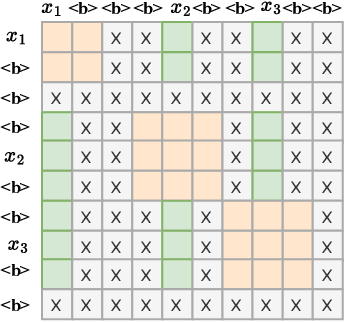
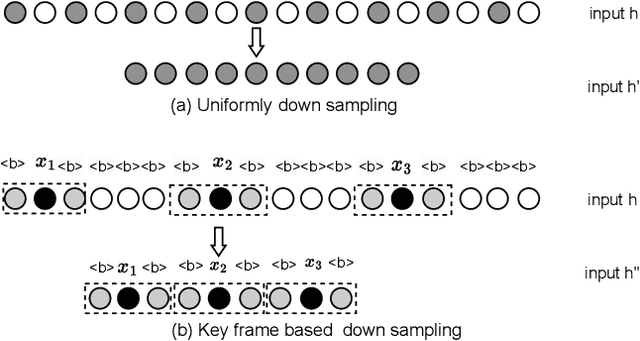
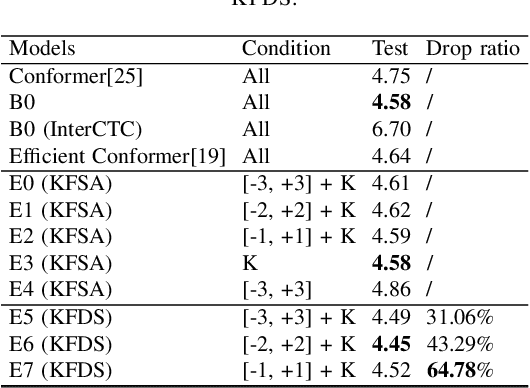
Recently, Conformer as a backbone network for end-to-end automatic speech recognition achieved state-of-the-art performance. The Conformer block leverages a self-attention mechanism to capture global information, along with a convolutional neural network to capture local information, resulting in improved performance. However, the Conformer-based model encounters an issue with the self-attention mechanism, as computational complexity grows quadratically with the length of the input sequence. Inspired by previous Connectionist Temporal Classification (CTC) guided blank skipping during decoding, we introduce intermediate CTC outputs as guidance into the downsampling procedure of the Conformer encoder. We define the frame with non-blank output as key frame. Specifically, we introduce the key frame-based self-attention (KFSA) mechanism, a novel method to reduce the computation of the self-attention mechanism using key frames. The structure of our proposed approach comprises two encoders. Following the initial encoder, we introduce an intermediate CTC loss function to compute the label frame, enabling us to extract the key frames and blank frames for KFSA. Furthermore, we introduce the key frame-based downsampling (KFDS) mechanism to operate on high-dimensional acoustic features directly and drop the frames corresponding to blank labels, which results in new acoustic feature sequences as input to the second encoder. By using the proposed method, which achieves comparable or higher performance than vanilla Conformer and other similar work such as Efficient Conformer. Meantime, our proposed method can discard more than 60\% useless frames during model training and inference, which will accelerate the inference speed significantly. This work code is available in {https://github.com/scufan1990/Key-Frame-Mechanism-For-Efficient-Conformer}
Enhancing multilingual speech recognition in air traffic control by sentence-level language identification
Apr 29, 2023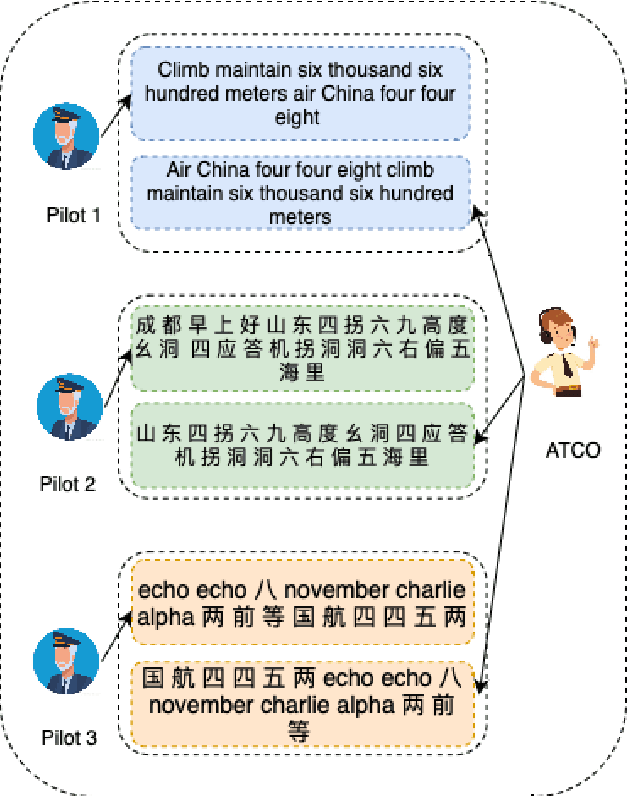
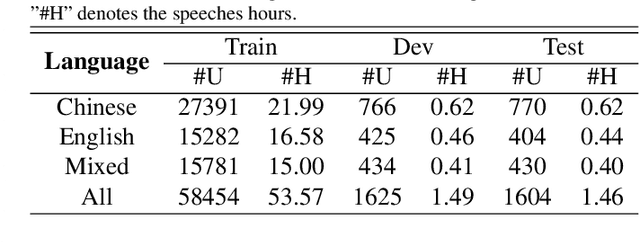
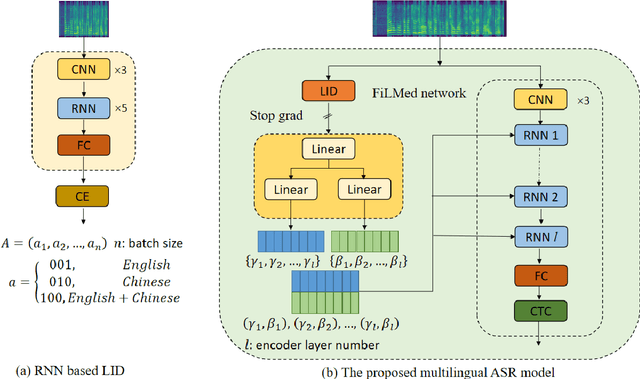
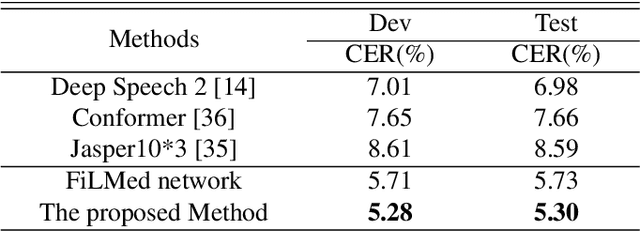
Automatic speech recognition (ASR) technique is becoming increasingly popular to improve the efficiency and safety of air traffic control (ATC) operations. However, the conversation between ATC controllers and pilots using multilingual speech brings a great challenge to building high-accuracy ASR systems. In this work, we present a two-stage multilingual ASR framework. The first stage is to train a language identifier (LID), that based on a recurrent neural network (RNN) to obtain sentence language identification in the form of one-hot encoding. The second stage aims to train an RNN-based end-to-end multilingual recognition model that utilizes sentence language features generated by LID to enhance input features. In this work, We introduce Featurewise Linear Modulation (FiLM) to improve the performance of multilingual ASR by utilizing sentence language identification. Furthermore, we introduce a new sentence language identification learning module called SLIL, which consists of a FiLM layer and a Squeeze-and-Excitation Networks layer. Extensive experiments on the ATCSpeech dataset show that our proposed method outperforms the baseline model. Compared to the vanilla FiLMed backbone model, the proposed multilingual ASR model obtains about 7.50% character error rate relative performance improvement.
Speech recognition for air traffic control via feature learning and end-to-end training
Nov 04, 2021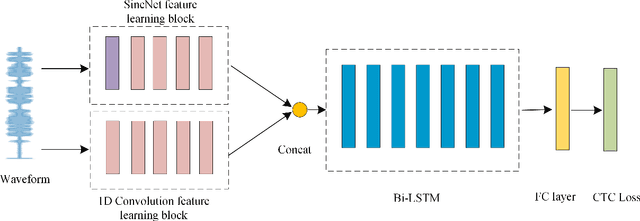
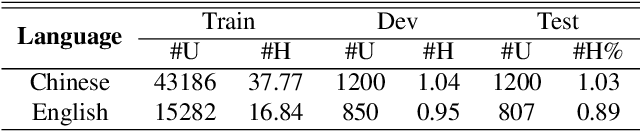
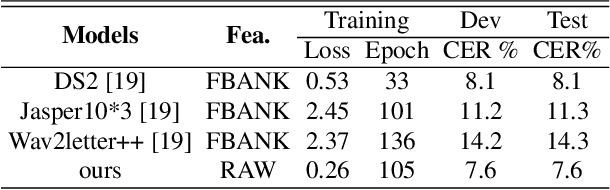
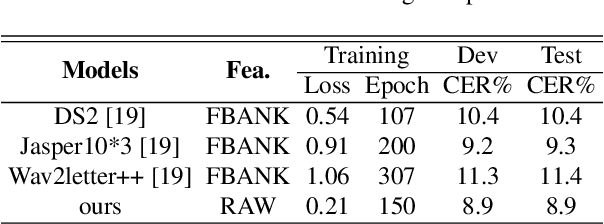
In this work, we propose a new automatic speech recognition (ASR) system based on feature learning and an end-to-end training procedure for air traffic control (ATC) systems. The proposed model integrates the feature learning block, recurrent neural network (RNN), and connectionist temporal classification loss to build an end-to-end ASR model. Facing the complex environments of ATC speech, instead of the handcrafted features, a learning block is designed to extract informative features from raw waveforms for acoustic modeling. Both the SincNet and 1D convolution blocks are applied to process the raw waveforms, whose outputs are concatenated to the RNN layers for the temporal modeling. Thanks to the ability to learn representations from raw waveforms, the proposed model can be optimized in a complete end-to-end manner, i.e., from waveform to text. Finally, the multilingual issue in the ATC domain is also considered to achieve the ASR task by constructing a combined vocabulary of Chinese characters and English letters. The proposed approach is validated on a multilingual real-world corpus (ATCSpeech), and the experimental results demonstrate that the proposed approach outperforms other baselines, achieving a 6.9\% character error rate.