 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreaming Decoder-Only Automatic Speech Recognition with Discrete Speech Units: A Pilot Study
Jun 27, 2024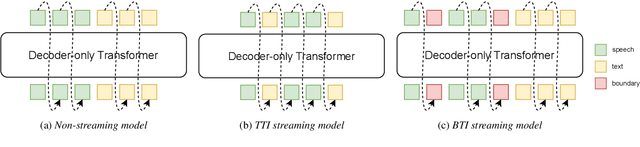
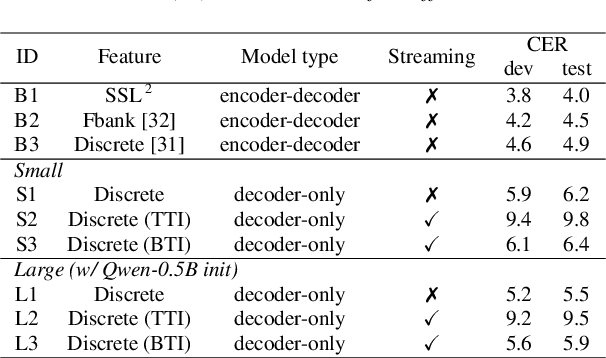
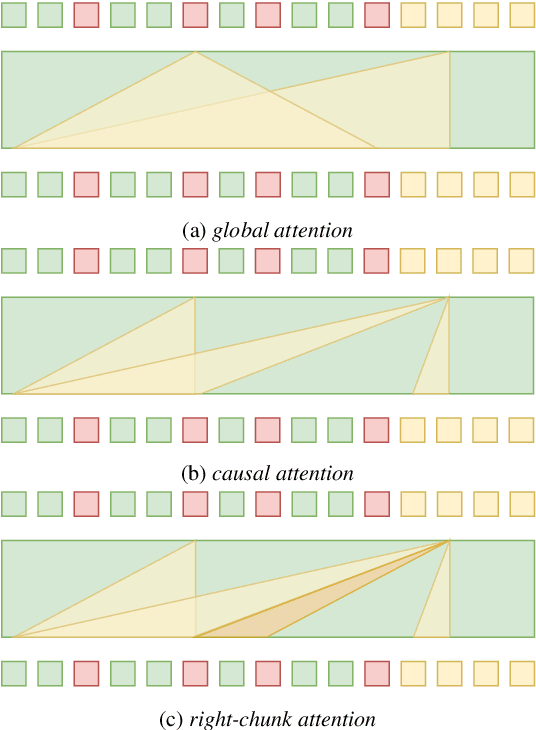

Unified speech-text models like SpeechGPT, VioLA, and AudioPaLM have shown impressive performance across various speech-related tasks, especially in Automatic Speech Recognition (ASR). These models typically adopt a unified method to model discrete speech and text tokens, followed by training a decoder-only transformer. However, they are all designed for non-streaming ASR tasks, where the entire speech utterance is needed during decoding. Hence, we introduce a decoder-only model exclusively designed for streaming recognition, incorporating a dedicated boundary token to facilitate streaming recognition and employing causal attention masking during the training phase. Furthermore, we introduce right-chunk attention and various data augmentation techniques to improve the model's contextual modeling abilities. While achieving streaming speech recognition, experiments on the AISHELL-1 and -2 datasets demonstrate the competitive performance of our streaming approach with non-streaming decoder-only counterparts.
Skipformer: A Skip-and-Recover Strategy for Efficient Speech Recognition
Mar 13, 2024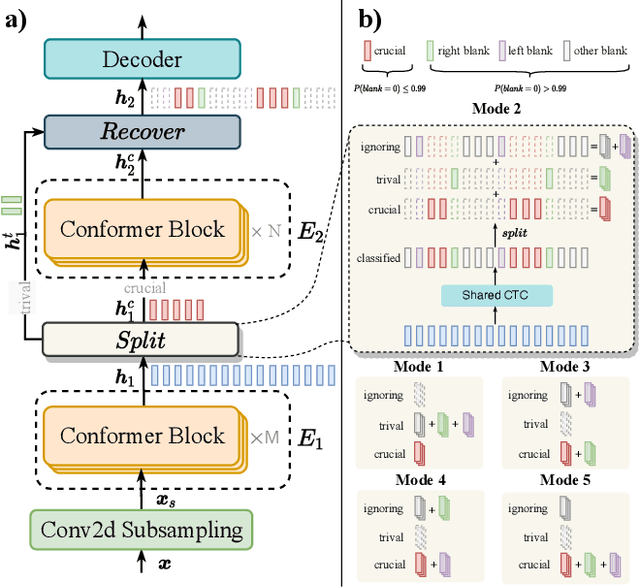
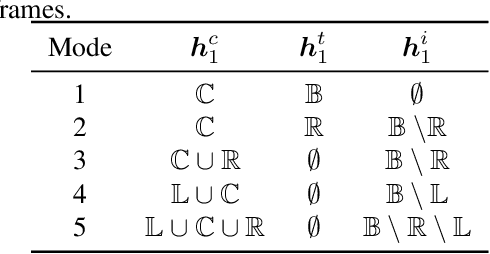
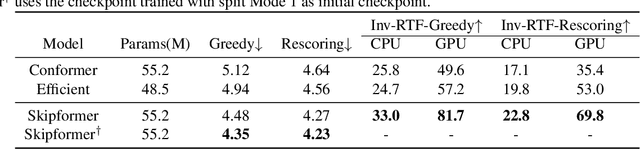
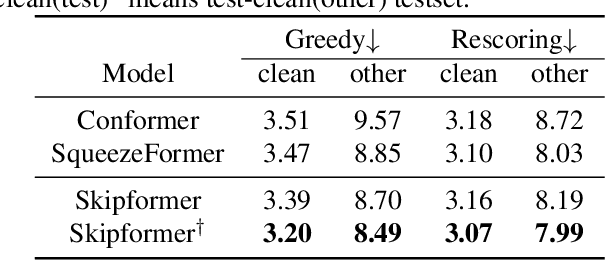
Conformer-based attention models have become the de facto backbone model for Automatic Speech Recognition tasks. A blank symbol is usually introduced to align the input and output sequences for CTC or RNN-T models. Unfortunately, the long input length overloads computational budget and memory consumption quadratically by attention mechanism. In this work, we propose a "Skip-and-Recover" Conformer architecture, named Skipformer, to squeeze sequence input length dynamically and inhomogeneously. Skipformer uses an intermediate CTC output as criteria to split frames into three groups: crucial, skipping and ignoring. The crucial group feeds into next conformer blocks and its output joint with skipping group by original temporal order as the final encoder output. Experiments show that our model reduces the input sequence length by 31 times on Aishell-1 and 22 times on Librispeech corpus. Meanwhile, the model can achieve better recognition accuracy and faster inference speed than recent baseline models. Our code is open-sourced and available online.
Key Frame Mechanism For Efficient Conformer Based End-to-end Speech Recognition
Oct 28, 2023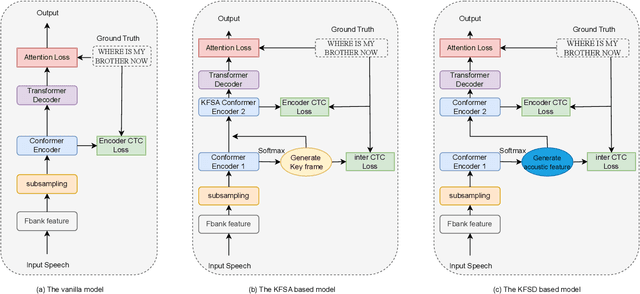
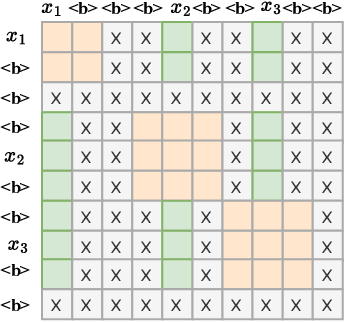
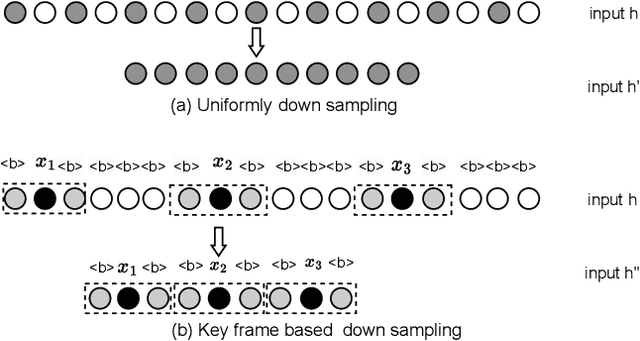
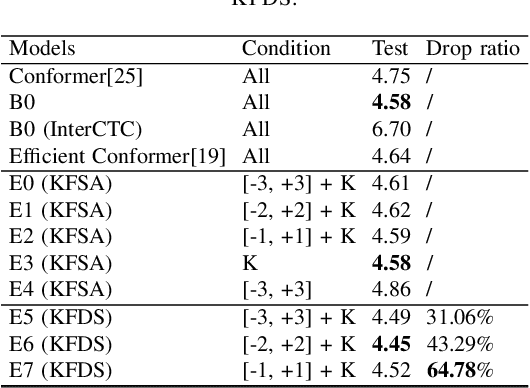
Recently, Conformer as a backbone network for end-to-end automatic speech recognition achieved state-of-the-art performance. The Conformer block leverages a self-attention mechanism to capture global information, along with a convolutional neural network to capture local information, resulting in improved performance. However, the Conformer-based model encounters an issue with the self-attention mechanism, as computational complexity grows quadratically with the length of the input sequence. Inspired by previous Connectionist Temporal Classification (CTC) guided blank skipping during decoding, we introduce intermediate CTC outputs as guidance into the downsampling procedure of the Conformer encoder. We define the frame with non-blank output as key frame. Specifically, we introduce the key frame-based self-attention (KFSA) mechanism, a novel method to reduce the computation of the self-attention mechanism using key frames. The structure of our proposed approach comprises two encoders. Following the initial encoder, we introduce an intermediate CTC loss function to compute the label frame, enabling us to extract the key frames and blank frames for KFSA. Furthermore, we introduce the key frame-based downsampling (KFDS) mechanism to operate on high-dimensional acoustic features directly and drop the frames corresponding to blank labels, which results in new acoustic feature sequences as input to the second encoder. By using the proposed method, which achieves comparable or higher performance than vanilla Conformer and other similar work such as Efficient Conformer. Meantime, our proposed method can discard more than 60\% useless frames during model training and inference, which will accelerate the inference speed significantly. This work code is available in {https://github.com/scufan1990/Key-Frame-Mechanism-For-Efficient-Conformer}
A meta learning scheme for fast accent domain expansion in Mandarin speech recognition
Jul 23, 2023Spoken languages show significant variation across mandarin and accent. Despite the high performance of mandarin automatic speech recognition (ASR), accent ASR is still a challenge task. In this paper, we introduce meta-learning techniques for fast accent domain expansion in mandarin speech recognition, which expands the field of accents without deteriorating the performance of mandarin ASR. Meta-learning or learn-to-learn can learn general relation in multi domains not only for over-fitting a specific domain. So we select meta-learning in the domain expansion task. This more essential learning will cause improved performance on accent domain extension tasks. We combine the methods of meta learning and freeze of model parameters, which makes the recognition performance more stable in different cases and the training faster about 20%. Our approach significantly outperforms other methods about 3% relatively in the accent domain expansion task. Compared to the baseline model, it improves relatively 37% under the condition that the mandarin test set remains unchanged. In addition, it also proved this method to be effective on a large amount of data with a relative performance improvement of 4% on the accent test set.
Attention-based End-to-End Models for Small-Footprint Keyword Spotting
Mar 29, 2018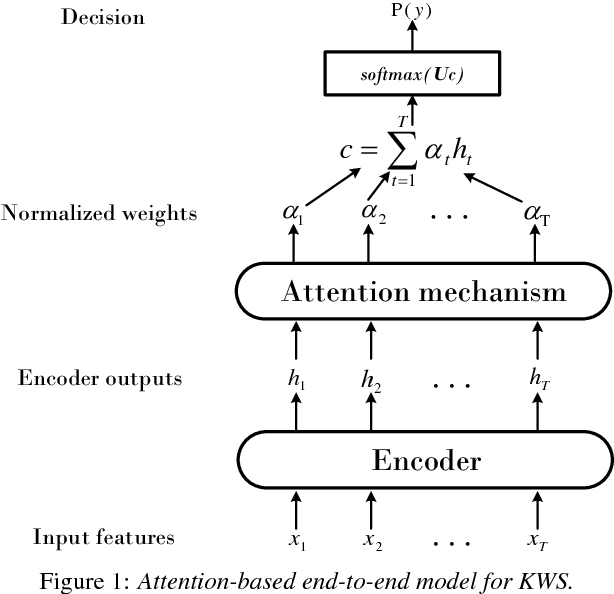


In this paper, we propose an attention-based end-to-end neural approach for small-footprint keyword spotting (KWS), which aims to simplify the pipelines of building a production-quality KWS system. Our model consists of an encoder and an attention mechanism. The encoder transforms the input signal into a high level representation using RNNs. Then the attention mechanism weights the encoder features and generates a fixed-length vector. Finally, by linear transformation and softmax function, the vector becomes a score used for keyword detection. We also evaluate the performance of different encoder architectures, including LSTM, GRU and CRNN. Experiments on real-world wake-up data show that our approach outperforms the recent Deep KWS approach by a large margin and the best performance is achieved by CRNN. To be more specific, with ~84K parameters, our attention-based model achieves 1.02% false rejection rate (FRR) at 1.0 false alarm (FA) per hour.
Attention-Based End-to-End Speech Recognition on Voice Search
Feb 13, 2018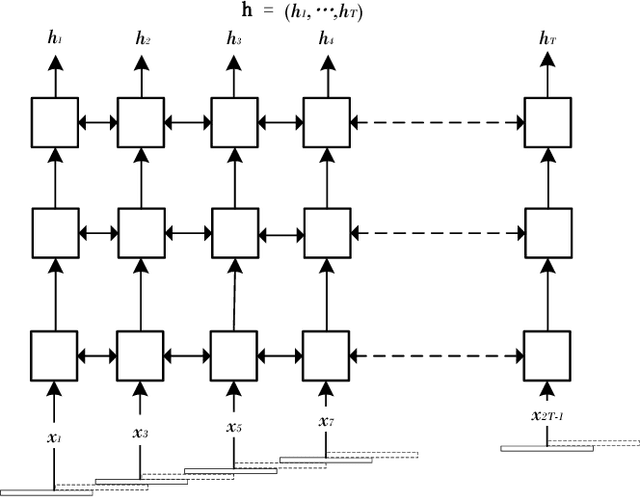
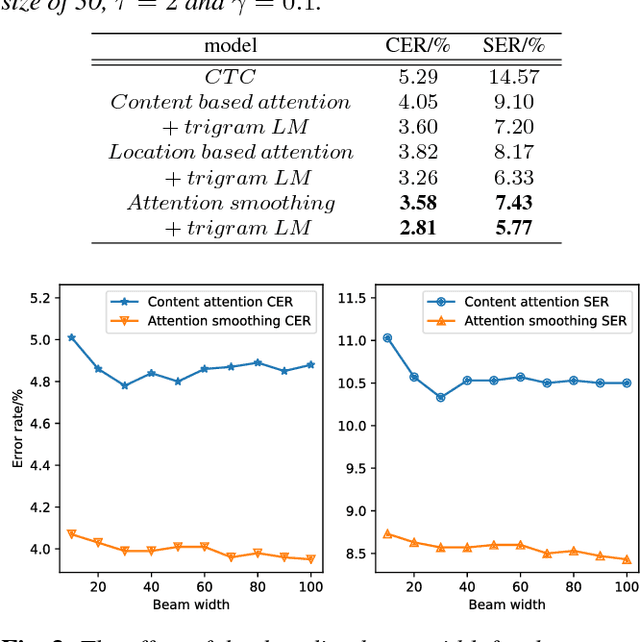
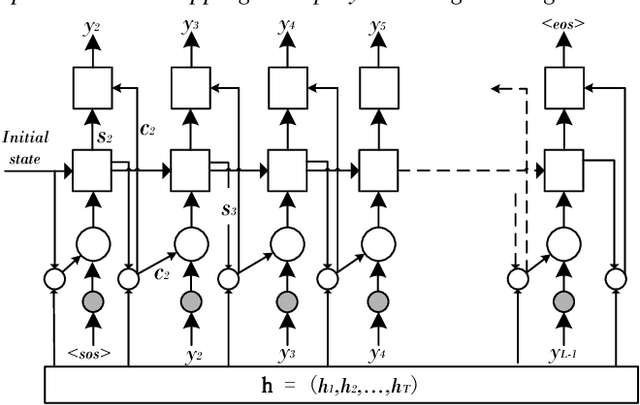
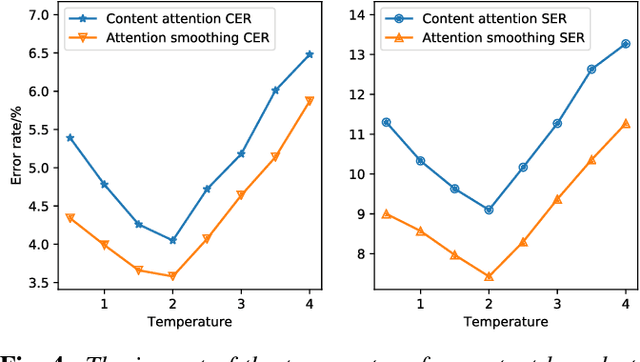
Recently, there has been a growing interest in end-to-end speech recognition that directly transcribes speech to text without any predefined alignments. In this paper, we explore the use of attention-based encoder-decoder model for Mandarin speech recognition on a voice search task. Previous attempts have shown that applying attention-based encoder-decoder to Mandarin speech recognition was quite difficult due to the logographic orthography of Mandarin, the large vocabulary and the conditional dependency of the attention model. In this paper, we use character embedding to deal with the large vocabulary. Several tricks are used for effective model training, including L2 regularization, Gaussian weight noise and frame skipping. We compare two attention mechanisms and use attention smoothing to cover long context in the attention model. Taken together, these tricks allow us to finally achieve a character error rate (CER) of 3.58% and a sentence error rate (SER) of 7.43% on the MiTV voice search dataset. While together with a trigram language model, CER and SER reach 2.81% and 5.77%, respectively.