 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Accuracy: Community Perspectives on Machine Translation
Jun 08, 2026Despite remarkable progress in machine translation (MT), non-AI communities have raised growing concerns about MT systems, suggesting a noticeable gap between technical advancement and the needs of real-world users. For instance, while NLP researchers focus on benchmark performance, end users care about ethical concerns, trust, reliability, costs, and more. We argue that listening to various user communities is essential so that research efforts would be directed towards the problems that the communities care about. To this end, we present a large-scale analysis, for the first time, that investigates what four stakeholder communities (AI developers, professional translators, language learners, and language service providers) post about MT technology on social media. To do so, we construct a dataset of 79,286 posts and comments from Reddit, Facebook, Bluesky, and Mastodon from 2019 to 2025, and analyse where these communities disagree, and how and why. Overall, we find that communities often disagree, and even show strong conflicts due to polarised sentiments on topics such as translation quality, efficiency, and reliability. This is because these communities approach these topics differently: the AI community frames them as technical and computational problems, while non-AI (user) communities care more about quality nuances, time savings, user trust, and broader social issues.
EchoRL: Reinforcement Learning via Rollout Echoing
May 29, 2026Reinforcement Learning with Verifiable Rewards is an effective route for post-training to strengthen the reasoning capability of large language models. However, as training proceeds, the learning signal can collapse thus makes the training gain become marginal and ineffective. Specifically, a growing fraction of prompts' rollouts become advantage-degenerated: all the self-generated rollouts show verified-success, making the standard deviation over their rewards be zero; accordingly each rollout's advantage becomes degenerated (zero) as well. Given such rollouts' advantages, the policy-gradient for model optimization eventually vanishes, capping the training performance. We argue that some of these rollouts still contain valuable learning signals but unfortunately omitted with the existing RLVR methods. In this paper, inspired through analyzing the entropy pattern behind golden trajectories produced by external expert models, we propose EchoRL for better exploiting the advantage-degenerated rollouts to further improve the training performance. EchoRL is a lightweight module that first identifies an EchoClip from verified-success rollouts based on their step-level entropy values, and then feeds this clip back as an auxiliary supervision signal in the RL objective. Extensive experiments across 10 benchmarks, 5 LLM backbones, and 4 popular RLVR post-training methods demonstrate that EchoRL consistently improves RLVR post-training with minimal overhead.
ASCD: Attention-Steerable Contrastive Decoding for Reducing Hallucination in MLLM
Jun 17, 2025Multimodal Large Language Model (MLLM) often suffer from hallucinations. They over-rely on partial cues and generate incorrect responses. Recently, methods like Visual Contrastive Decoding (VCD) and Instruction Contrastive Decoding (ICD) have been proposed to mitigate hallucinations by contrasting predictions from perturbed or negatively prefixed inputs against original outputs. In this work, we uncover that methods like VCD and ICD fundamentally influence internal attention dynamics of the model. This observation suggests that their effectiveness may not stem merely from surface-level modifications to logits but from deeper shifts in attention distribution. Inspired by this insight, we propose an attention-steerable contrastive decoding framework that directly intervenes in attention mechanisms of the model to offer a more principled approach to mitigating hallucinations. Our experiments across multiple MLLM architectures and diverse decoding methods demonstrate that our approach significantly reduces hallucinations and improves the performance on benchmarks such as POPE, CHAIR, and MMHal-Bench, while simultaneously enhancing performance on standard VQA benchmarks.
The ICME 2025 Audio Encoder Capability Challenge
Jan 25, 2025This challenge aims to evaluate the capabilities of audio encoders, especially in the context of multi-task learning and real-world applications. Participants are invited to submit pre-trained audio encoders that map raw waveforms to continuous embeddings. These encoders will be tested across diverse tasks including speech, environmental sounds, and music, with a focus on real-world usability. The challenge features two tracks: Track A for parameterized evaluation, and Track B for parameter-free evaluation. This challenge provides a platform for evaluating and advancing the state-of-the-art in audio encoder design.
Visual Instruction Tuning with 500x Fewer Parameters through Modality Linear Representation-Steering
Dec 16, 2024



Multimodal Large Language Models (MLLMs) have significantly advanced visual tasks by integrating visual representations into large language models (LLMs). The textual modality, inherited from LLMs, equips MLLMs with abilities like instruction following and in-context learning. In contrast, the visual modality enhances performance in downstream tasks by leveraging rich semantic content, spatial information, and grounding capabilities. These intrinsic modalities work synergistically across various visual tasks. Our research initially reveals a persistent imbalance between these modalities, with text often dominating output generation during visual instruction tuning. This imbalance occurs when using both full fine-tuning and parameter-efficient fine-tuning (PEFT) methods. We then found that re-balancing these modalities can significantly reduce the number of trainable parameters required, inspiring a direction for further optimizing visual instruction tuning. We introduce Modality Linear Representation-Steering (MoReS) to achieve the goal. MoReS effectively re-balances the intrinsic modalities throughout the model, where the key idea is to steer visual representations through linear transformations in the visual subspace across each model layer. To validate our solution, we composed LLaVA Steering, a suite of models integrated with the proposed MoReS method. Evaluation results show that the composed LLaVA Steering models require, on average, 500 times fewer trainable parameters than LoRA needs while still achieving comparable performance across three visual benchmarks and eight visual question-answering tasks. Last, we present the LLaVA Steering Factory, an in-house developed platform that enables researchers to quickly customize various MLLMs with component-based architecture for seamlessly integrating state-of-the-art models, and evaluate their intrinsic modality imbalance.
Optimizing Dysarthria Wake-Up Word Spotting: An End-to-End Approach for SLT 2024 LRDWWS Challenge
Sep 16, 2024Speech has emerged as a widely embraced user interface across diverse applications. However, for individuals with dysarthria, the inherent variability in their speech poses significant challenges. This paper presents an end-to-end Pretrain-based Dual-filter Dysarthria Wake-up word Spotting (PD-DWS) system for the SLT 2024 Low-Resource Dysarthria Wake-Up Word Spotting Challenge. Specifically, our system improves performance from two key perspectives: audio modeling and dual-filter strategy. For audio modeling, we propose an innovative 2branch-d2v2 model based on the pre-trained data2vec2 (d2v2), which can simultaneously model automatic speech recognition (ASR) and wake-up word spotting (WWS) tasks through a unified multi-task finetuning paradigm. Additionally, a dual-filter strategy is introduced to reduce the false accept rate (FAR) while maintaining the same false reject rate (FRR). Experimental results demonstrate that our PD-DWS system achieves an FAR of 0.00321 and an FRR of 0.005, with a total score of 0.00821 on the test-B eval set, securing first place in the challenge.
Efficient Extraction of Noise-Robust Discrete Units from Self-Supervised Speech Models
Sep 04, 2024



Continuous speech can be converted into a discrete sequence by deriving discrete units from the hidden features of self-supervised learned (SSL) speech models. Although SSL models are becoming larger and trained on more data, they are often sensitive to real-life distortions like additive noise or reverberation, which translates to a shift in discrete units. We propose a parameter-efficient approach to generate noise-robust discrete units from pre-trained SSL models by training a small encoder-decoder model, with or without adapters, to simultaneously denoise and discretise the hidden features of the SSL model. The model learns to generate a clean discrete sequence for a noisy utterance, conditioned on the SSL features. The proposed denoiser outperforms several pre-training methods on the tasks of noisy discretisation and noisy speech recognition, and can be finetuned to the target environment with a few recordings of unlabeled target data.
Enhancing Automated Audio Captioning via Large Language Models with Optimized Audio Encoding
Jun 19, 2024Automated audio captioning (AAC) is an audio-to-text task to describe audio contents in natural language. Recently, the advancements in large language models (LLMs), with improvements in training approaches for audio encoders, have opened up possibilities for improving AAC. Thus, we explore enhancing AAC from three aspects: 1) a pre-trained audio encoder via consistent ensemble distillation (CED) is used to improve the effectivity of acoustic tokens, with a querying transformer (Q-Former) bridging the modality gap to LLM and compress acoustic tokens; 2) we investigate the advantages of using a Llama 2 with 7B parameters as the decoder; 3) another pre-trained LLM corrects text errors caused by insufficient training data and annotation ambiguities. Both the audio encoder and text decoder are optimized by -Base (LoRA). Experiments show that each of these enhancements is effective. Our method obtains a 33.0 SPIDEr-FL score, outperforming the winner of DCASE 2023 Task 6A.
Towards Expressive Zero-Shot Speech Synthesis with Hierarchical Prosody Modeling
Jun 11, 2024



Recent research in zero-shot speech synthesis has made significant progress in speaker similarity. However, current efforts focus on timbre generalization rather than prosody modeling, which results in limited naturalness and expressiveness. To address this, we introduce a novel speech synthesis model trained on large-scale datasets, including both timbre and hierarchical prosody modeling. As timbre is a global attribute closely linked to expressiveness, we adopt a global vector to model speaker timbre while guiding prosody modeling. Besides, given that prosody contains both global consistency and local variations, we introduce a diffusion model as the pitch predictor and employ a prosody adaptor to model prosody hierarchically, further enhancing the prosody quality of the synthesized speech. Experimental results show that our model not only maintains comparable timbre quality to the baseline but also exhibits better naturalness and expressiveness.
Bridging Language Gaps in Audio-Text Retrieval
Jun 11, 2024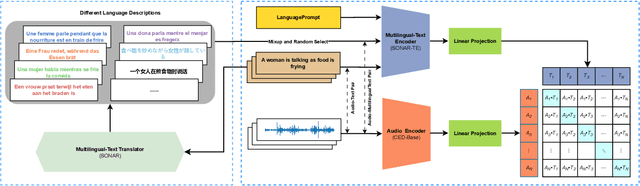
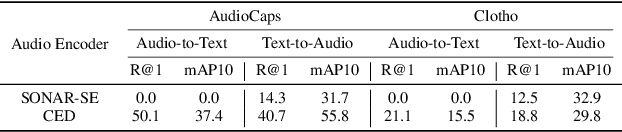
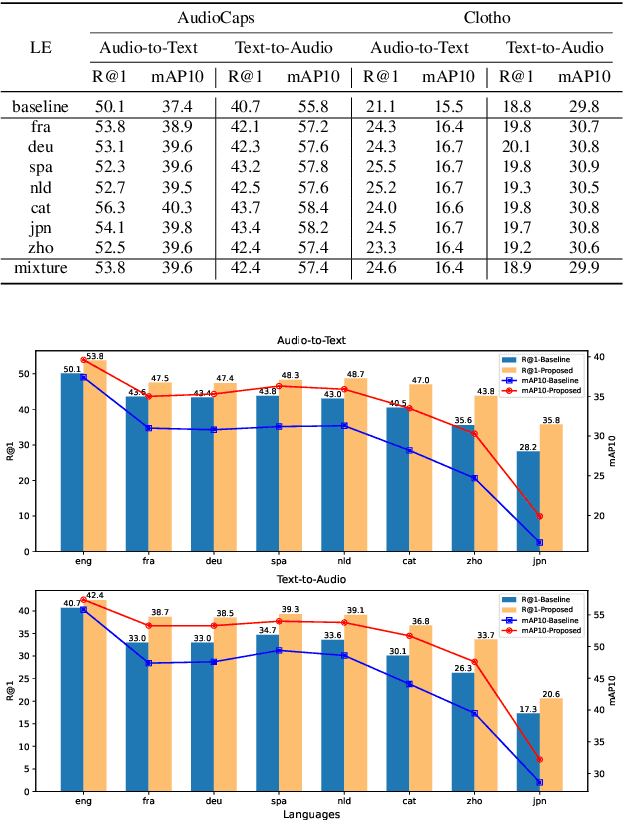
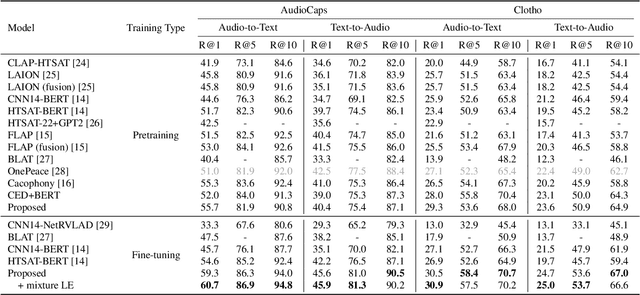
Audio-text retrieval is a challenging task, requiring the search for an audio clip or a text caption within a database. The predominant focus of existing research on English descriptions poses a limitation on the applicability of such models, given the abundance of non-English content in real-world data. To address these linguistic disparities, we propose a language enhancement (LE), using a multilingual text encoder (SONAR) to encode the text data with language-specific information. Additionally, we optimize the audio encoder through the application of consistent ensemble distillation (CED), enhancing support for variable-length audio-text retrieval. Our methodology excels in English audio-text retrieval, demonstrating state-of-the-art (SOTA) performance on commonly used datasets such as AudioCaps and Clotho. Simultaneously, the approach exhibits proficiency in retrieving content in seven other languages with only 10% of additional language-enhanced training data, yielding promising results. The source code is publicly available https://github.com/zyyan4/ml-clap.