 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLAP: General contrastive audio-text pretraining across domains and languages
Jun 12, 2025



Contrastive Language Audio Pretraining (CLAP) is a widely-used method to bridge the gap between audio and text domains. Current CLAP methods enable sound and music retrieval in English, ignoring multilingual spoken content. To address this, we introduce general language audio pretraining (GLAP), which expands CLAP with multilingual and multi-domain abilities. GLAP demonstrates its versatility by achieving competitive performance on standard audio-text retrieval benchmarks like Clotho and AudioCaps, while significantly surpassing existing methods in speech retrieval and classification tasks. Additionally, GLAP achieves strong results on widely used sound-event zero-shot benchmarks, while simultaneously outperforming previous methods on speech content benchmarks. Further keyword spotting evaluations across 50 languages emphasize GLAP's advanced multilingual capabilities. Finally, multilingual sound and music understanding is evaluated across four languages. Checkpoints and Source: https://github.com/xiaomi-research/dasheng-glap.
Structured Tensor Decomposition Based Channel Estimation and Double Refinements for Active RIS Empowered Broadband Systems
Nov 25, 2024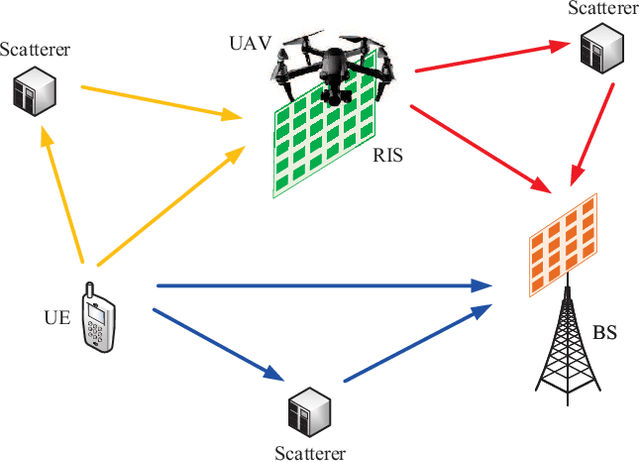
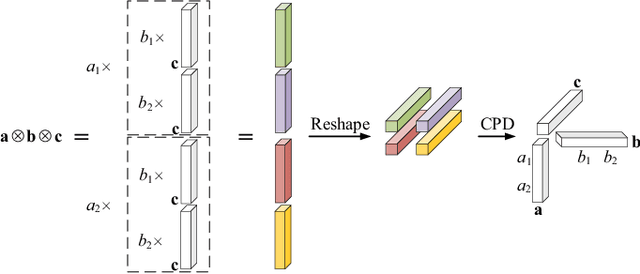
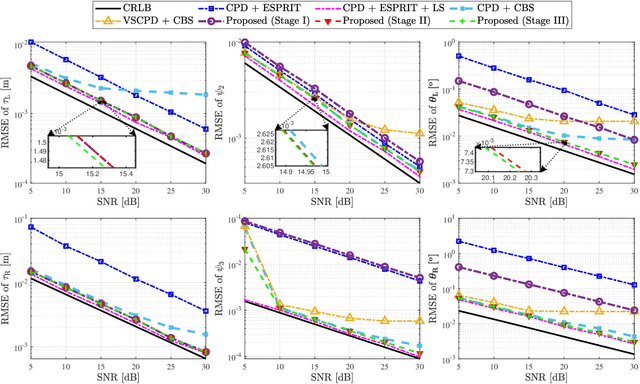
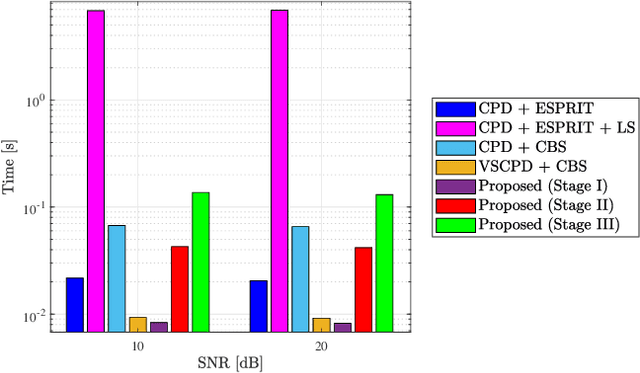
Channel parameter estimation is crucial for optimal designs of next-generation reconfigurable intelligent surface (RIS)-empowered communications and sensing. Tensor-based mechanisms are particularly effective, capturing the multi-dimensional nature of wireless channels, especially in scenarios where RIS integrates with multiple-antenna devices. However, existing studies assume either a line-of-sight (LOS) scenario or a blocked condition for non-RIS channel. This paper solves a novel problem: tensor-based channel parameter recovery for active RIS-aided multiple-antenna wideband connections in a multipath environment with non-RIS paths. System settings are customized to construct the received signals as a fifth-order canonical polyadic (CP) tensor. Four of the five-factor matrices unfortunately contain redundant columns, and the remaining one is a Vandermonde matrix, which fails to satisfy the Kruskal condition for tensor decomposition uniqueness. To address this issue, spatial smoothing and Vandermonde structured CP decomposition (VSCPD) are applied, making the tensor factorization problem solvable and providing a relaxed general uniqueness condition. A sequential triple-stage channel estimation framework is proposed based on the factor estimates. The first stage enables multipath identification and algebraic coarse estimation, while the following two stages offer optional successive refinements at the cost of increased complexity. The closed-form Cramer-Rao lower bound (CRLB) is derived to assess the estimation performance. Herein, the noise covariance matrix depends on multipath parameters in our active-RIS scenario. Finally, numerical results are provided to verify the effectiveness of proposed algorithms under various evaluation metrics.
Enhancing Automated Audio Captioning via Large Language Models with Optimized Audio Encoding
Jun 19, 2024Automated audio captioning (AAC) is an audio-to-text task to describe audio contents in natural language. Recently, the advancements in large language models (LLMs), with improvements in training approaches for audio encoders, have opened up possibilities for improving AAC. Thus, we explore enhancing AAC from three aspects: 1) a pre-trained audio encoder via consistent ensemble distillation (CED) is used to improve the effectivity of acoustic tokens, with a querying transformer (Q-Former) bridging the modality gap to LLM and compress acoustic tokens; 2) we investigate the advantages of using a Llama 2 with 7B parameters as the decoder; 3) another pre-trained LLM corrects text errors caused by insufficient training data and annotation ambiguities. Both the audio encoder and text decoder are optimized by -Base (LoRA). Experiments show that each of these enhancements is effective. Our method obtains a 33.0 SPIDEr-FL score, outperforming the winner of DCASE 2023 Task 6A.
Scaling up masked audio encoder learning for general audio classification
Jun 11, 2024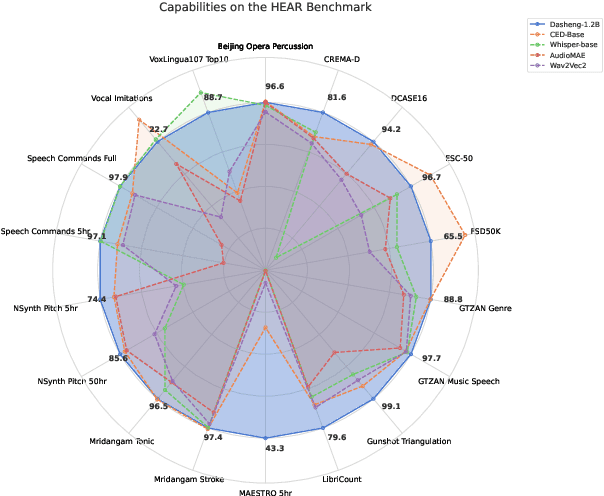
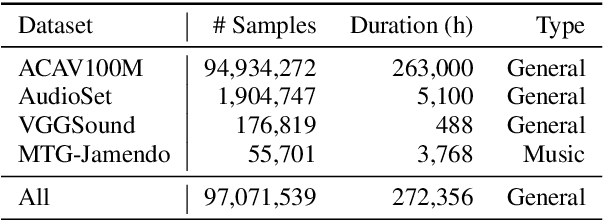
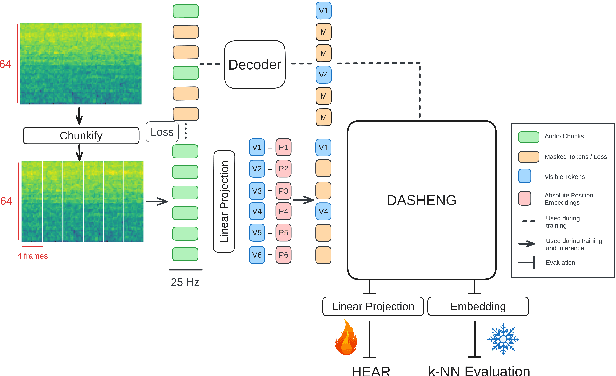
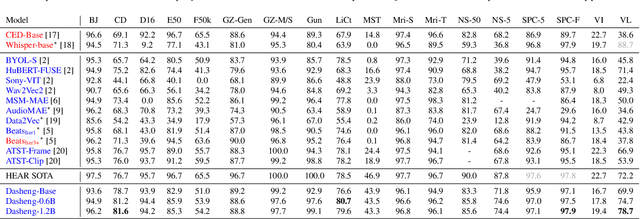
Despite progress in audio classification, a generalization gap remains between speech and other sound domains, such as environmental sounds and music. Models trained for speech tasks often fail to perform well on environmental or musical audio tasks, and vice versa. While self-supervised (SSL) audio representations offer an alternative, there has been limited exploration of scaling both model and dataset sizes for SSL-based general audio classification. We introduce Dasheng, a simple SSL audio encoder, based on the efficient masked autoencoder framework. Trained with 1.2 billion parameters on 272,356 hours of diverse audio, Dasheng obtains significant performance gains on the HEAR benchmark. It outperforms previous works on CREMA-D, LibriCount, Speech Commands, VoxLingua, and competes well in music and environment classification. Dasheng features inherently contain rich speech, music, and environmental information, as shown in nearest-neighbor classification experiments. Code is available https://github.com/richermans/dasheng/.
Bridging Language Gaps in Audio-Text Retrieval
Jun 11, 2024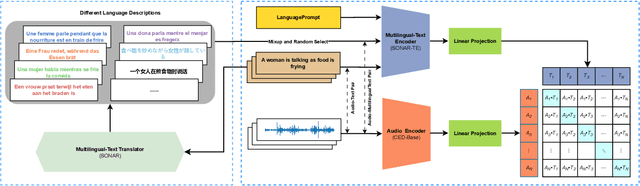
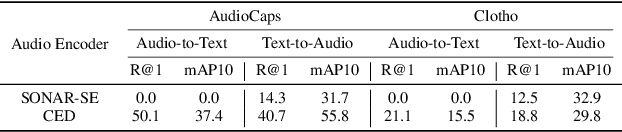
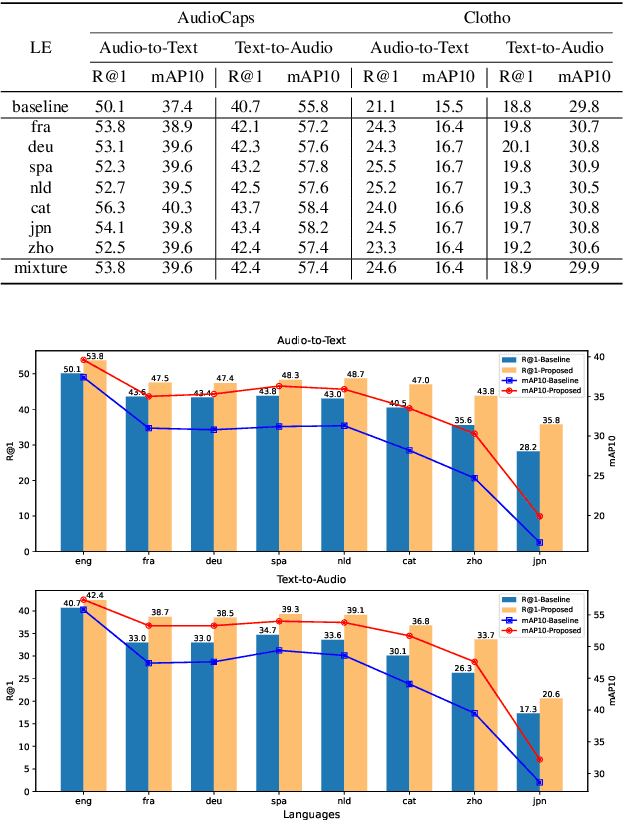
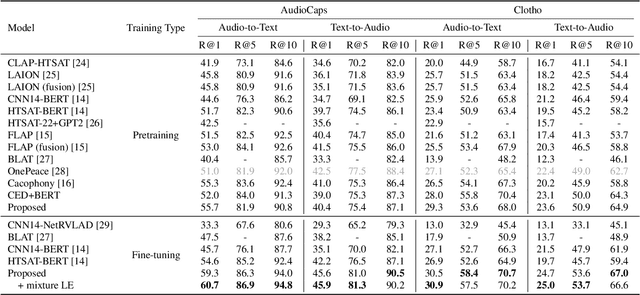
Audio-text retrieval is a challenging task, requiring the search for an audio clip or a text caption within a database. The predominant focus of existing research on English descriptions poses a limitation on the applicability of such models, given the abundance of non-English content in real-world data. To address these linguistic disparities, we propose a language enhancement (LE), using a multilingual text encoder (SONAR) to encode the text data with language-specific information. Additionally, we optimize the audio encoder through the application of consistent ensemble distillation (CED), enhancing support for variable-length audio-text retrieval. Our methodology excels in English audio-text retrieval, demonstrating state-of-the-art (SOTA) performance on commonly used datasets such as AudioCaps and Clotho. Simultaneously, the approach exhibits proficiency in retrieving content in seven other languages with only 10% of additional language-enhanced training data, yielding promising results. The source code is publicly available https://github.com/zyyan4/ml-clap.
Graph Domain Adaptation: Challenges, Progress and Prospects
Feb 01, 2024As graph representation learning often suffers from label scarcity problems in real-world applications, researchers have proposed graph domain adaptation (GDA) as an effective knowledge-transfer paradigm across graphs. In particular, to enhance model performance on target graphs with specific tasks, GDA introduces a bunch of task-related graphs as source graphs and adapts the knowledge learnt from source graphs to the target graphs. Since GDA combines the advantages of graph representation learning and domain adaptation, it has become a promising direction of transfer learning on graphs and has attracted an increasing amount of research interest in recent years. In this paper, we comprehensively overview the studies of GDA and present a detailed survey of recent advances. Specifically, we outline the research status and challenges, propose a taxonomy, introduce the details of representative works, and discuss the prospects. To the best of our knowledge, this paper is the first survey for graph domain adaptation. A detailed paper list is available at https://github.com/Skyorca/Awesome-Graph-Domain-Adaptation-Papers.
Causality and Independence Enhancement for Biased Node Classification
Oct 14, 2023



Most existing methods that address out-of-distribution (OOD) generalization for node classification on graphs primarily focus on a specific type of data biases, such as label selection bias or structural bias. However, anticipating the type of bias in advance is extremely challenging, and designing models solely for one specific type may not necessarily improve overall generalization performance. Moreover, limited research has focused on the impact of mixed biases, which are more prevalent and demanding in real-world scenarios. To address these limitations, we propose a novel Causality and Independence Enhancement (CIE) framework, applicable to various graph neural networks (GNNs). Our approach estimates causal and spurious features at the node representation level and mitigates the influence of spurious correlations through the backdoor adjustment. Meanwhile, independence constraint is introduced to improve the discriminability and stability of causal and spurious features in complex biased environments. Essentially, CIE eliminates different types of data biases from a unified perspective, without the need to design separate methods for each bias as before. To evaluate the performance under specific types of data biases, mixed biases, and low-resource scenarios, we conducted comprehensive experiments on five publicly available datasets. Experimental results demonstrate that our approach CIE not only significantly enhances the performance of GNNs but outperforms state-of-the-art debiased node classification methods.
CED: Consistent ensemble distillation for audio tagging
Sep 08, 2023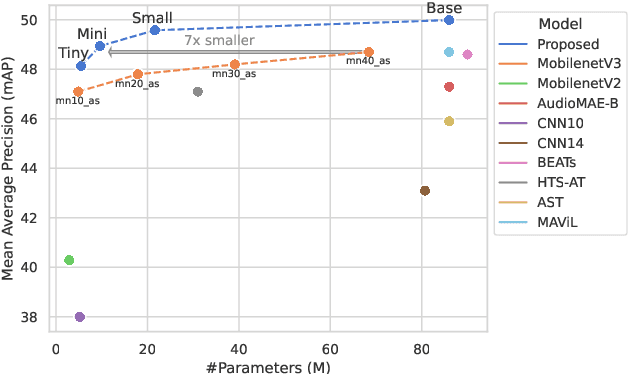
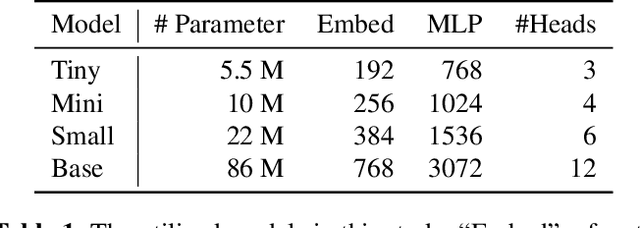
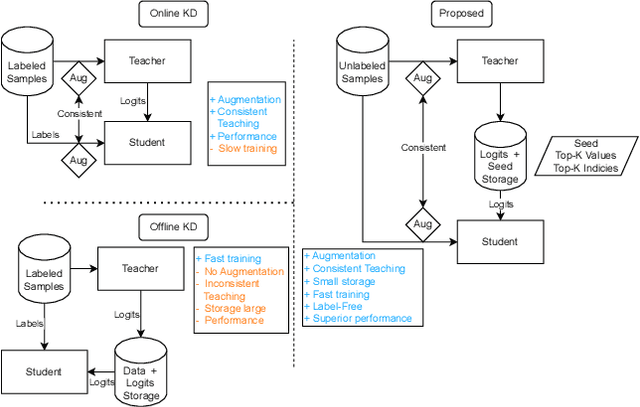

Augmentation and knowledge distillation (KD) are well-established techniques employed in audio classification tasks, aimed at enhancing performance and reducing model sizes on the widely recognized Audioset (AS) benchmark. Although both techniques are effective individually, their combined use, called consistent teaching, hasn't been explored before. This paper proposes CED, a simple training framework that distils student models from large teacher ensembles with consistent teaching. To achieve this, CED efficiently stores logits as well as the augmentation methods on disk, making it scalable to large-scale datasets. Central to CED's efficacy is its label-free nature, meaning that only the stored logits are used for the optimization of a student model only requiring 0.3\% additional disk space for AS. The study trains various transformer-based models, including a 10M parameter model achieving a 49.0 mean average precision (mAP) on AS. Pretrained models and code are available at https://github.com/RicherMans/CED.
OpenGDA: Graph Domain Adaptation Benchmark for Cross-network Learning
Jul 21, 2023



Graph domain adaptation models are widely adopted in cross-network learning tasks, with the aim of transferring labeling or structural knowledge. Currently, there mainly exist two limitations in evaluating graph domain adaptation models. On one side, they are primarily tested for the specific cross-network node classification task, leaving tasks at edge-level and graph-level largely under-explored. Moreover, they are primarily tested in limited scenarios, such as social networks or citation networks, lacking validation of model's capability in richer scenarios. As comprehensively assessing models could enhance model practicality in real-world applications, we propose a benchmark, known as OpenGDA. It provides abundant pre-processed and unified datasets for different types of tasks (node, edge, graph). They originate from diverse scenarios, covering web information systems, urban systems and natural systems. Furthermore, it integrates state-of-the-art models with standardized and end-to-end pipelines. Overall, OpenGDA provides a user-friendly, scalable and reproducible benchmark for evaluating graph domain adaptation models. The benchmark experiments highlight the challenges of applying GDA models to real-world applications with consistent good performance, and potentially provide insights to future research. As an emerging project, OpenGDA will be regularly updated with new datasets and models. It could be accessed from https://github.com/Skyorca/OpenGDA.
Focus on the Sound around You: Monaural Target Speaker Extraction via Distance and Speaker Information
Jun 28, 2023



Previously, Target Speaker Extraction (TSE) has yielded outstanding performance in certain application scenarios for speech enhancement and source separation. However, obtaining auxiliary speaker-related information is still challenging in noisy environments with significant reverberation. inspired by the recently proposed distance-based sound separation, we propose the near sound (NS) extractor, which leverages distance information for TSE to reliably extract speaker information without requiring previous speaker enrolment, called speaker embedding self-enrollment (SESE). Full- & sub-band modeling is introduced to enhance our NS-Extractor's adaptability towards environments with significant reverberation. Experimental results on several cross-datasets demonstrate the effectiveness of our improvements and the excellent performance of our proposed NS-Extractor in different application scenarios.