 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLAP: General contrastive audio-text pretraining across domains and languages
Jun 12, 2025



Contrastive Language Audio Pretraining (CLAP) is a widely-used method to bridge the gap between audio and text domains. Current CLAP methods enable sound and music retrieval in English, ignoring multilingual spoken content. To address this, we introduce general language audio pretraining (GLAP), which expands CLAP with multilingual and multi-domain abilities. GLAP demonstrates its versatility by achieving competitive performance on standard audio-text retrieval benchmarks like Clotho and AudioCaps, while significantly surpassing existing methods in speech retrieval and classification tasks. Additionally, GLAP achieves strong results on widely used sound-event zero-shot benchmarks, while simultaneously outperforming previous methods on speech content benchmarks. Further keyword spotting evaluations across 50 languages emphasize GLAP's advanced multilingual capabilities. Finally, multilingual sound and music understanding is evaluated across four languages. Checkpoints and Source: https://github.com/xiaomi-research/dasheng-glap.
Enhancing Automated Audio Captioning via Large Language Models with Optimized Audio Encoding
Jun 19, 2024Automated audio captioning (AAC) is an audio-to-text task to describe audio contents in natural language. Recently, the advancements in large language models (LLMs), with improvements in training approaches for audio encoders, have opened up possibilities for improving AAC. Thus, we explore enhancing AAC from three aspects: 1) a pre-trained audio encoder via consistent ensemble distillation (CED) is used to improve the effectivity of acoustic tokens, with a querying transformer (Q-Former) bridging the modality gap to LLM and compress acoustic tokens; 2) we investigate the advantages of using a Llama 2 with 7B parameters as the decoder; 3) another pre-trained LLM corrects text errors caused by insufficient training data and annotation ambiguities. Both the audio encoder and text decoder are optimized by -Base (LoRA). Experiments show that each of these enhancements is effective. Our method obtains a 33.0 SPIDEr-FL score, outperforming the winner of DCASE 2023 Task 6A.
Bridging Language Gaps in Audio-Text Retrieval
Jun 11, 2024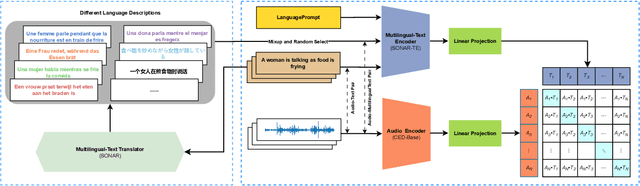
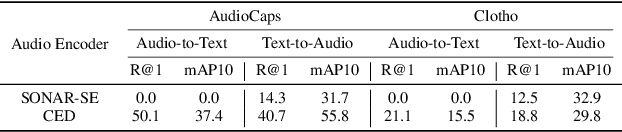
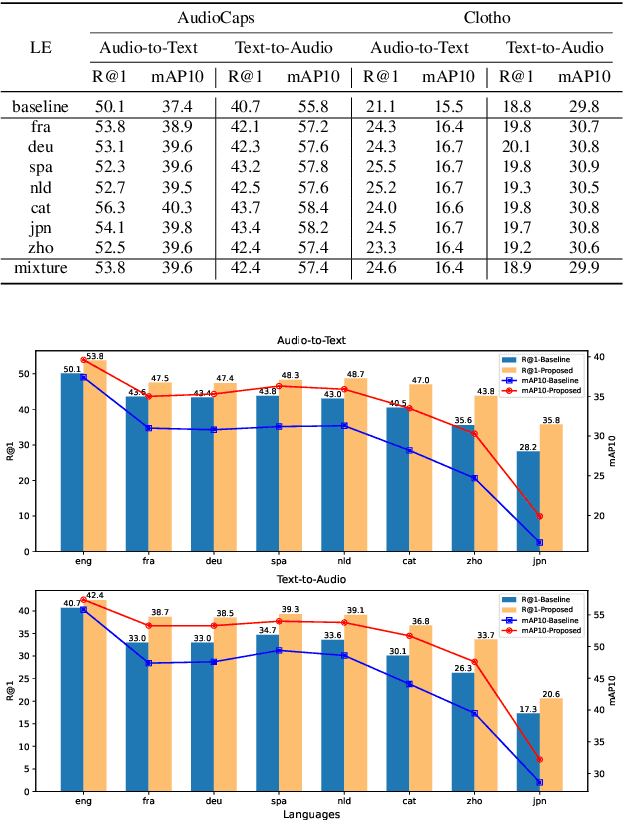
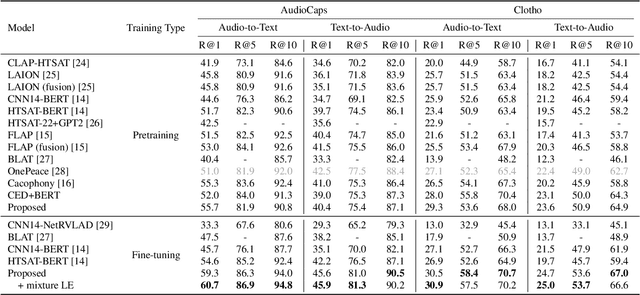
Audio-text retrieval is a challenging task, requiring the search for an audio clip or a text caption within a database. The predominant focus of existing research on English descriptions poses a limitation on the applicability of such models, given the abundance of non-English content in real-world data. To address these linguistic disparities, we propose a language enhancement (LE), using a multilingual text encoder (SONAR) to encode the text data with language-specific information. Additionally, we optimize the audio encoder through the application of consistent ensemble distillation (CED), enhancing support for variable-length audio-text retrieval. Our methodology excels in English audio-text retrieval, demonstrating state-of-the-art (SOTA) performance on commonly used datasets such as AudioCaps and Clotho. Simultaneously, the approach exhibits proficiency in retrieving content in seven other languages with only 10% of additional language-enhanced training data, yielding promising results. The source code is publicly available https://github.com/zyyan4/ml-clap.
Scaling up masked audio encoder learning for general audio classification
Jun 11, 2024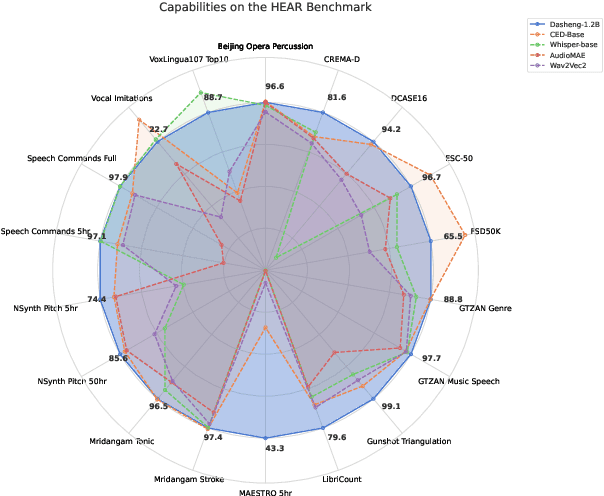
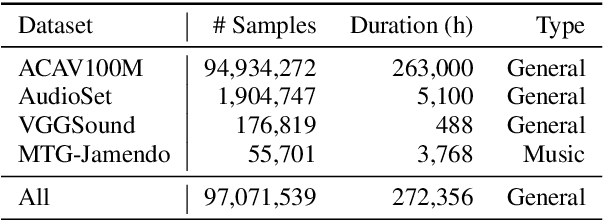
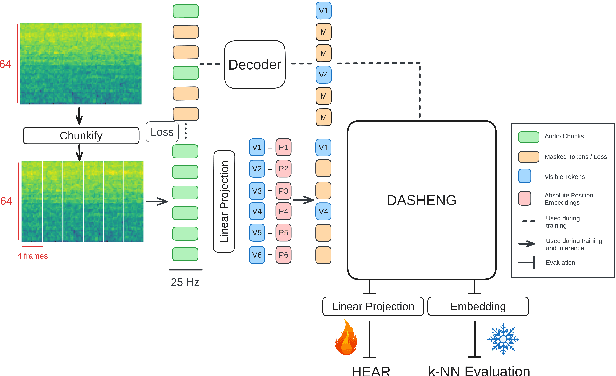
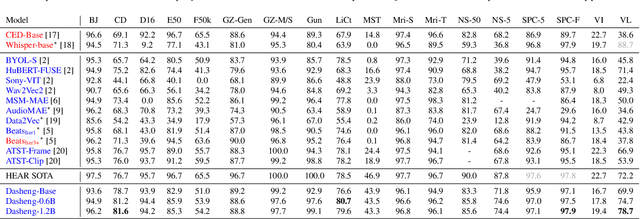
Despite progress in audio classification, a generalization gap remains between speech and other sound domains, such as environmental sounds and music. Models trained for speech tasks often fail to perform well on environmental or musical audio tasks, and vice versa. While self-supervised (SSL) audio representations offer an alternative, there has been limited exploration of scaling both model and dataset sizes for SSL-based general audio classification. We introduce Dasheng, a simple SSL audio encoder, based on the efficient masked autoencoder framework. Trained with 1.2 billion parameters on 272,356 hours of diverse audio, Dasheng obtains significant performance gains on the HEAR benchmark. It outperforms previous works on CREMA-D, LibriCount, Speech Commands, VoxLingua, and competes well in music and environment classification. Dasheng features inherently contain rich speech, music, and environmental information, as shown in nearest-neighbor classification experiments. Code is available https://github.com/richermans/dasheng/.
CED: Consistent ensemble distillation for audio tagging
Sep 08, 2023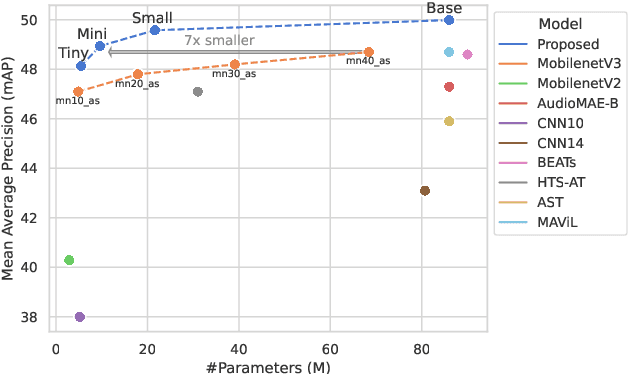
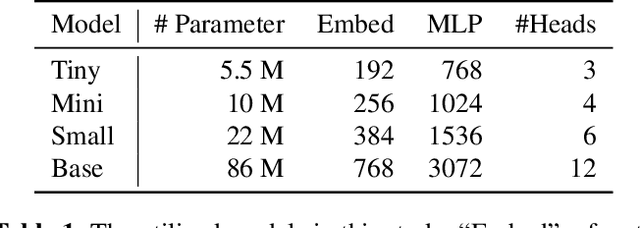
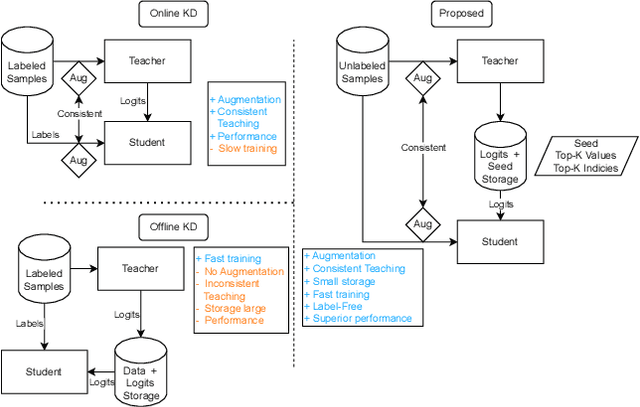

Augmentation and knowledge distillation (KD) are well-established techniques employed in audio classification tasks, aimed at enhancing performance and reducing model sizes on the widely recognized Audioset (AS) benchmark. Although both techniques are effective individually, their combined use, called consistent teaching, hasn't been explored before. This paper proposes CED, a simple training framework that distils student models from large teacher ensembles with consistent teaching. To achieve this, CED efficiently stores logits as well as the augmentation methods on disk, making it scalable to large-scale datasets. Central to CED's efficacy is its label-free nature, meaning that only the stored logits are used for the optimization of a student model only requiring 0.3\% additional disk space for AS. The study trains various transformer-based models, including a 10M parameter model achieving a 49.0 mean average precision (mAP) on AS. Pretrained models and code are available at https://github.com/RicherMans/CED.
Focus on the Sound around You: Monaural Target Speaker Extraction via Distance and Speaker Information
Jun 28, 2023



Previously, Target Speaker Extraction (TSE) has yielded outstanding performance in certain application scenarios for speech enhancement and source separation. However, obtaining auxiliary speaker-related information is still challenging in noisy environments with significant reverberation. inspired by the recently proposed distance-based sound separation, we propose the near sound (NS) extractor, which leverages distance information for TSE to reliably extract speaker information without requiring previous speaker enrolment, called speaker embedding self-enrollment (SESE). Full- & sub-band modeling is introduced to enhance our NS-Extractor's adaptability towards environments with significant reverberation. Experimental results on several cross-datasets demonstrate the effectiveness of our improvements and the excellent performance of our proposed NS-Extractor in different application scenarios.
AV-SepFormer: Cross-Attention SepFormer for Audio-Visual Target Speaker Extraction
Jun 25, 2023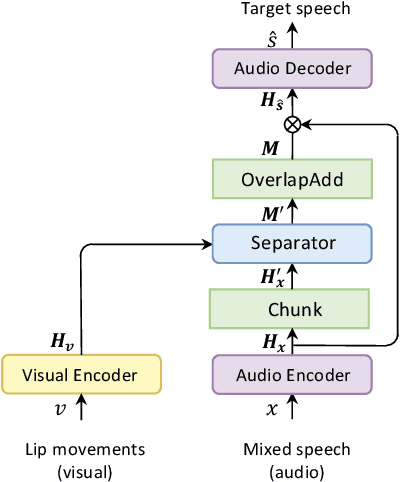



Visual information can serve as an effective cue for target speaker extraction (TSE) and is vital to improving extraction performance. In this paper, we propose AV-SepFormer, a SepFormer-based attention dual-scale model that utilizes cross- and self-attention to fuse and model features from audio and visual. AV-SepFormer splits the audio feature into a number of chunks, equivalent to the length of the visual feature. Then self- and cross-attention are employed to model and fuse the multi-modal features. Furthermore, we use a novel 2D positional encoding, that introduces the positional information between and within chunks and provides significant gains over the traditional positional encoding. Our model has two key advantages: the time granularity of audio chunked feature is synchronized to the visual feature, which alleviates the harm caused by the inconsistency of audio and video sampling rate; by combining self- and cross-attention, feature fusion and speech extraction processes are unified within an attention paradigm. The experimental results show that AV-SepFormer significantly outperforms other existing methods.
Understanding temporally weakly supervised training: A case study for keyword spotting
May 30, 2023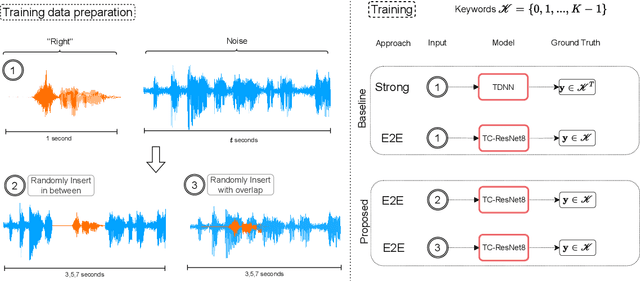



The currently most prominent algorithm to train keyword spotting (KWS) models with deep neural networks (DNNs) requires strong supervision i.e., precise knowledge of the spoken keyword location in time. Thus, most KWS approaches treat the presence of redundant data, such as noise, within their training set as an obstacle. A common training paradigm to deal with data redundancies is to use temporally weakly supervised learning, which only requires providing labels on a coarse scale. This study explores the limits of DNN training using temporally weak labeling with applications in KWS. We train a simple end-to-end classifier on the common Google Speech Commands dataset with increased difficulty by randomly appending and adding noise to the training dataset. Our results indicate that temporally weak labeling can achieve comparable results to strongly supervised baselines while having a less stringent labeling requirement. In the presence of noise, weakly supervised models are capable to localize and extract target keywords without explicit supervision, leading to a performance increase compared to strongly supervised approaches.
Streaming Audio Transformers for Online Audio Tagging
May 29, 2023



Transformers have emerged as a prominent model framework for audio tagging (AT), boasting state-of-the-art (SOTA) performance on the widely-used Audioset dataset. However, their impressive performance often comes at the cost of high memory usage, slow inference speed, and considerable model delay, rendering them impractical for real-world AT applications. In this study, we introduce streaming audio transformers (SAT) that combine the vision transformer (ViT) architecture with Transformer-Xl-like chunk processing, enabling efficient processing of long-range audio signals. Our proposed SAT is benchmarked against other transformer-based SOTA methods, achieving significant improvements in terms of mean average precision (mAP) at a delay of 2s and 1s, while also exhibiting significantly lower memory usage and computational overhead. Checkpoints are publicly available https://github.com/RicherMans/SAT.
Unified Keyword Spotting and Audio Tagging on Mobile Devices with Transformers
Mar 03, 2023



Keyword spotting (KWS) is a core human-machine-interaction front-end task for most modern intelligent assistants. Recently, a unified (UniKW-AT) framework has been proposed that adds additional capabilities in the form of audio tagging (AT) to a KWS model. However, previous work did not consider the real-world deployment of a UniKW-AT model, where factors such as model size and inference speed are more important than performance alone. This work introduces three mobile-device deployable models named Unified Transformers (UiT). Our best model achieves an mAP of 34.09 on Audioset, and an accuracy of 97.76 on the public Google Speech Commands V1 dataset. Further, we benchmark our proposed approaches on four mobile platforms, revealing that the proposed UiT models can achieve a speedup of 2 - 6 times against a competitive MobileNetV2.