 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAV-SepFormer: Cross-Attention SepFormer for Audio-Visual Target Speaker Extraction
Paper and Code
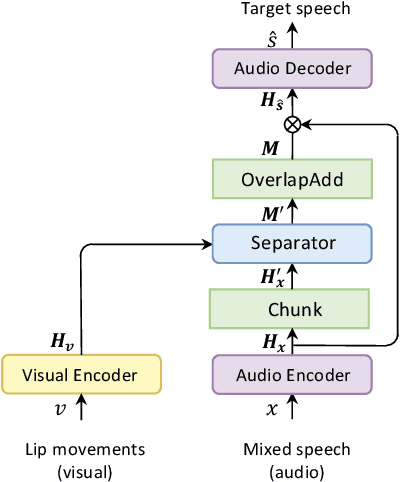



Visual information can serve as an effective cue for target speaker extraction (TSE) and is vital to improving extraction performance. In this paper, we propose AV-SepFormer, a SepFormer-based attention dual-scale model that utilizes cross- and self-attention to fuse and model features from audio and visual. AV-SepFormer splits the audio feature into a number of chunks, equivalent to the length of the visual feature. Then self- and cross-attention are employed to model and fuse the multi-modal features. Furthermore, we use a novel 2D positional encoding, that introduces the positional information between and within chunks and provides significant gains over the traditional positional encoding. Our model has two key advantages: the time granularity of audio chunked feature is synchronized to the visual feature, which alleviates the harm caused by the inconsistency of audio and video sampling rate; by combining self- and cross-attention, feature fusion and speech extraction processes are unified within an attention paradigm. The experimental results show that AV-SepFormer significantly outperforms other existing methods.