 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACAVCaps: Enabling large-scale training for fine-grained and diverse audio understanding
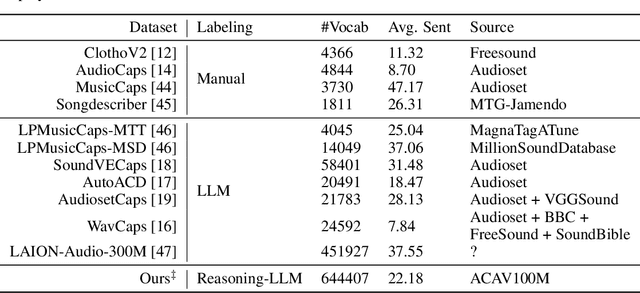
Mar 25, 2026General audio understanding is a fundamental goal for large audio-language models, with audio captioning serving as a cornerstone task for their development. However, progress in this domain is hindered by existing datasets, which lack the scale and descriptive granularity required to train truly versatile models. To address this gap, we introduce ACAVCaps, a new large-scale, fine-grained, and multi-faceted audio captioning dataset. Derived from the ACAV100M collection, ACAVCaps is constructed using a multi-expert pipeline that analyzes audio from diverse perspectives-including speech, music, and acoustic properties-which are then synthesized into rich, detailed descriptions by a large language model. Experimental results demonstrate that models pre-trained on ACAVCaps exhibit substantially stronger generalization capabilities on various downstream tasks compared to those trained on other leading captioning datasets. The dataset is available at https://github.com/xiaomi-research/acavcaps.
The Interspeech 2026 Audio Encoder Capability Challenge for Large Audio Language Models
Mar 24, 2026This paper presents the Interspeech 2026 Audio Encoder Capability Challenge, a benchmark specifically designed to evaluate and advance the performance of pre-trained audio encoders as front-end modules for Large Audio Language Models (LALMs). While LALMs have shown remarkable understanding of complex acoustic scenes, their performance depends on the semantic richness of the underlying audio encoder representations. This challenge addresses the integration gap by providing a unified generative evaluation framework, XARES-LLM, which assesses submitted encoders across a diverse suite of downstream classification and generation tasks. By decoupling encoder development from LLM fine-tuning, the challenge establishes a standardized protocol for general-purpose audio representations that can effectively be used for the next generation of multimodal language models.
DashengTokenizer: One layer is enough for unified audio understanding and generation
Feb 27, 2026This paper introduces DashengTokenizer, a continuous audio tokenizer engineered for joint use in both understanding and generation tasks. Unlike conventional approaches, which train acoustic tokenizers and subsequently integrate frozen semantic knowledge, our method inverts this paradigm: we leverage frozen semantic features and inject acoustic information. In linear evaluation across 22 diverse tasks, our method outperforms previous audio codec and audio encoder baselines by a significant margin while maintaining competitive audio reconstruction quality. Notably, we demonstrate that this acoustic injection improves performance for tasks such as speech emotion recognition, music understanding, and acoustic scene classification. We further evaluate the tokenizer's generative performance on text-to-audio (TTA), text-to-music (TTM), and speech enhancement (SE). Our approach surpasses standard variational autoencoder (VAE)-based methods on TTA and TTM tasks, while its effectiveness on SE underscores its capabilities as a general-purpose audio encoder. Finally, our results challenge the prevailing assumption that VAE-based architectures are a prerequisite for audio synthesis. Checkpoints are available at https://huggingface.co/mispeech/dashengtokenizer.
MiDashengLM: Efficient Audio Understanding with General Audio Captions
Aug 06, 2025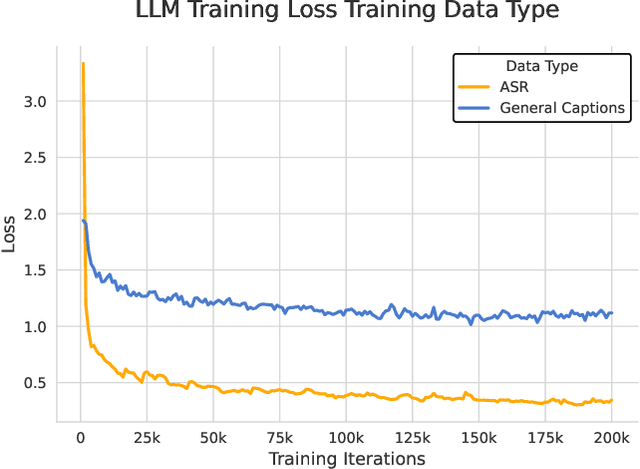

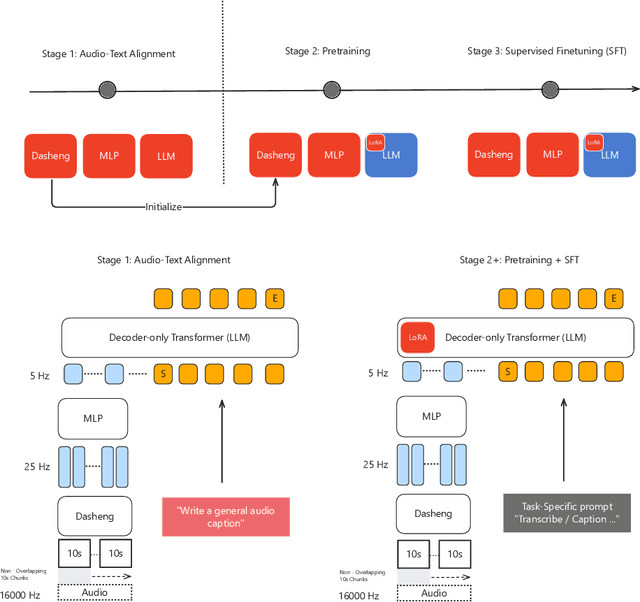
Current approaches for large audio language models (LALMs) often rely on closed data sources or proprietary models, limiting their generalization and accessibility. This paper introduces MiDashengLM, a novel open audio-language model designed for efficient and comprehensive audio understanding through the use of general audio captions using our novel ACAVCaps training dataset. MiDashengLM exclusively relies on publicly available pretraining and supervised fine-tuning (SFT) datasets, ensuring full transparency and reproducibility. At its core, MiDashengLM integrates Dasheng, an open-source audio encoder, specifically engineered to process diverse auditory information effectively. Unlike previous works primarily focused on Automatic Speech Recognition (ASR) based audio-text alignment, our strategy centers on general audio captions, fusing speech, sound and music information into one textual representation, enabling a holistic textual representation of complex audio scenes. Lastly, MiDashengLM provides an up to 4x speedup in terms of time-to-first-token (TTFT) and up to 20x higher throughput than comparable models. Checkpoints are available online at https://huggingface.co/mispeech/midashenglm-7b and https://github.com/xiaomi-research/dasheng-lm.
Efficient Speech Enhancement via Embeddings from Pre-trained Generative Audioencoders
Jun 13, 2025Recent research has delved into speech enhancement (SE) approaches that leverage audio embeddings from pre-trained models, diverging from time-frequency masking or signal prediction techniques. This paper introduces an efficient and extensible SE method. Our approach involves initially extracting audio embeddings from noisy speech using a pre-trained audioencoder, which are then denoised by a compact encoder network. Subsequently, a vocoder synthesizes the clean speech from denoised embeddings. An ablation study substantiates the parameter efficiency of the denoise encoder with a pre-trained audioencoder and vocoder. Experimental results on both speech enhancement and speaker fidelity demonstrate that our generative audioencoder-based SE system outperforms models utilizing discriminative audioencoders. Furthermore, subjective listening tests validate that our proposed system surpasses an existing state-of-the-art SE model in terms of perceptual quality.
GLAP: General contrastive audio-text pretraining across domains and languages
Jun 12, 2025



Contrastive Language Audio Pretraining (CLAP) is a widely-used method to bridge the gap between audio and text domains. Current CLAP methods enable sound and music retrieval in English, ignoring multilingual spoken content. To address this, we introduce general language audio pretraining (GLAP), which expands CLAP with multilingual and multi-domain abilities. GLAP demonstrates its versatility by achieving competitive performance on standard audio-text retrieval benchmarks like Clotho and AudioCaps, while significantly surpassing existing methods in speech retrieval and classification tasks. Additionally, GLAP achieves strong results on widely used sound-event zero-shot benchmarks, while simultaneously outperforming previous methods on speech content benchmarks. Further keyword spotting evaluations across 50 languages emphasize GLAP's advanced multilingual capabilities. Finally, multilingual sound and music understanding is evaluated across four languages. Checkpoints and Source: https://github.com/xiaomi-research/dasheng-glap.
X-ARES: A Comprehensive Framework for Assessing Audio Encoder Performance
May 22, 2025We introduces X-ARES (eXtensive Audio Representation and Evaluation Suite), a novel open-source benchmark designed to systematically assess audio encoder performance across diverse domains. By encompassing tasks spanning speech, environmental sounds, and music, X-ARES provides two evaluation approaches for evaluating audio representations: linear fine-tuning and unparameterized evaluation. The framework includes 22 distinct tasks that cover essential aspects of audio processing, from speech recognition and emotion detection to sound event classification and music genre identification. Our extensive evaluation of state-of-the-art audio encoders reveals significant performance variations across different tasks and domains, highlighting the complexity of general audio representation learning.
Reinforcement Learning Outperforms Supervised Fine-Tuning: A Case Study on Audio Question Answering
Mar 17, 2025


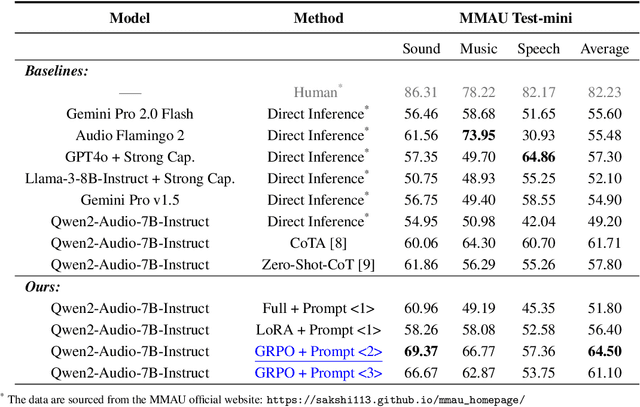
Recently, reinforcement learning (RL) has been shown to greatly enhance the reasoning capabilities of large language models (LLMs), and RL-based approaches have been progressively applied to visual multimodal tasks. However, the audio modality has largely been overlooked in these developments. Thus, we conduct a series of RL explorations in audio understanding and reasoning, specifically focusing on the audio question answering (AQA) task. We leverage the group relative policy optimization (GRPO) algorithm to Qwen2-Audio-7B-Instruct, and our experiments demonstrated state-of-the-art performance on the MMAU Test-mini benchmark, achieving an accuracy rate of 64.5%. The main findings in this technical report are as follows: 1) The GRPO algorithm can be effectively applied to large audio language models (LALMs), even when the model has only 8.2B parameters; 2) With only 38k post-training samples, RL significantly outperforms supervised fine-tuning (SFT), indicating that RL-based approaches can be effective without large datasets; 3) The explicit reasoning process has not shown significant benefits for AQA tasks, and how to efficiently utilize deep thinking remains an open question for further research; 4) LALMs still lag far behind humans auditory-language reasoning, suggesting that the RL-based approaches warrant further exploration. Our project is available at https://github.com/xiaomi-research/r1-aqa and https://huggingface.co/mispeech/r1-aqa.
The ICME 2025 Audio Encoder Capability Challenge
Jan 25, 2025This challenge aims to evaluate the capabilities of audio encoders, especially in the context of multi-task learning and real-world applications. Participants are invited to submit pre-trained audio encoders that map raw waveforms to continuous embeddings. These encoders will be tested across diverse tasks including speech, environmental sounds, and music, with a focus on real-world usability. The challenge features two tracks: Track A for parameterized evaluation, and Track B for parameter-free evaluation. This challenge provides a platform for evaluating and advancing the state-of-the-art in audio encoder design.
Enhancing Automated Audio Captioning via Large Language Models with Optimized Audio Encoding
Jun 19, 2024Automated audio captioning (AAC) is an audio-to-text task to describe audio contents in natural language. Recently, the advancements in large language models (LLMs), with improvements in training approaches for audio encoders, have opened up possibilities for improving AAC. Thus, we explore enhancing AAC from three aspects: 1) a pre-trained audio encoder via consistent ensemble distillation (CED) is used to improve the effectivity of acoustic tokens, with a querying transformer (Q-Former) bridging the modality gap to LLM and compress acoustic tokens; 2) we investigate the advantages of using a Llama 2 with 7B parameters as the decoder; 3) another pre-trained LLM corrects text errors caused by insufficient training data and annotation ambiguities. Both the audio encoder and text decoder are optimized by -Base (LoRA). Experiments show that each of these enhancements is effective. Our method obtains a 33.0 SPIDEr-FL score, outperforming the winner of DCASE 2023 Task 6A.