 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiDashengLM: Efficient Audio Understanding with General Audio Captions
Aug 06, 2025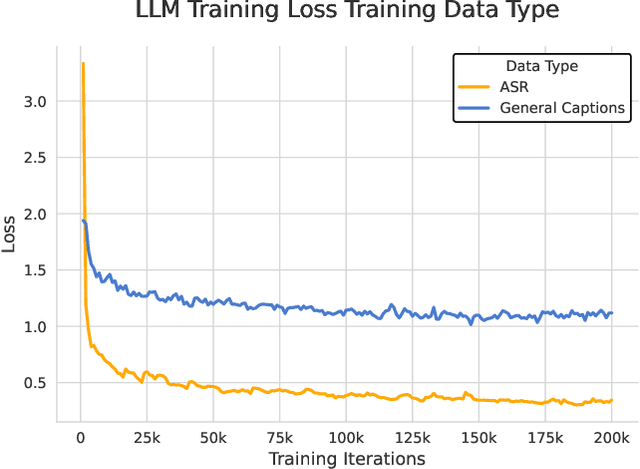

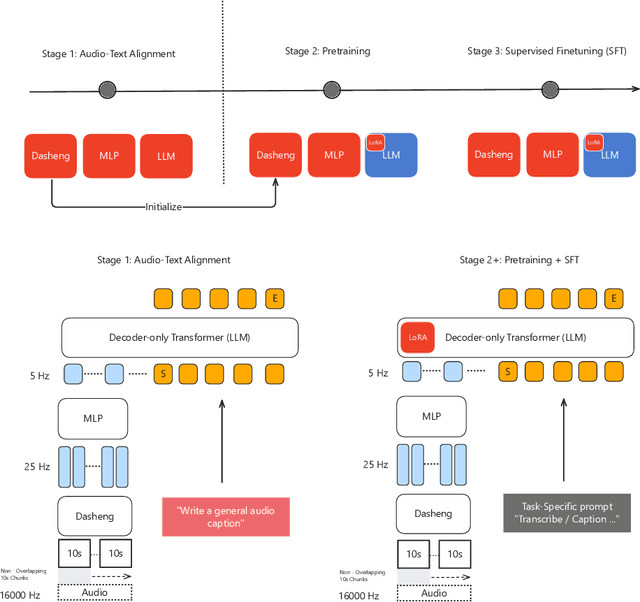
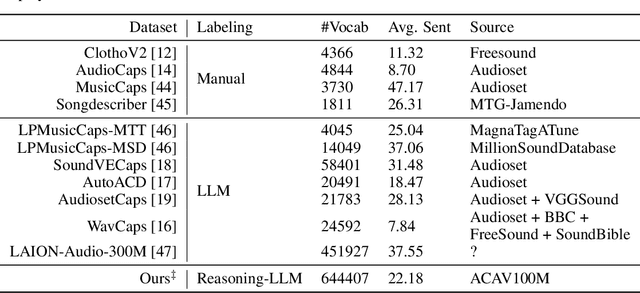
Current approaches for large audio language models (LALMs) often rely on closed data sources or proprietary models, limiting their generalization and accessibility. This paper introduces MiDashengLM, a novel open audio-language model designed for efficient and comprehensive audio understanding through the use of general audio captions using our novel ACAVCaps training dataset. MiDashengLM exclusively relies on publicly available pretraining and supervised fine-tuning (SFT) datasets, ensuring full transparency and reproducibility. At its core, MiDashengLM integrates Dasheng, an open-source audio encoder, specifically engineered to process diverse auditory information effectively. Unlike previous works primarily focused on Automatic Speech Recognition (ASR) based audio-text alignment, our strategy centers on general audio captions, fusing speech, sound and music information into one textual representation, enabling a holistic textual representation of complex audio scenes. Lastly, MiDashengLM provides an up to 4x speedup in terms of time-to-first-token (TTFT) and up to 20x higher throughput than comparable models. Checkpoints are available online at https://huggingface.co/mispeech/midashenglm-7b and https://github.com/xiaomi-research/dasheng-lm.
Efficient Speech Enhancement via Embeddings from Pre-trained Generative Audioencoders
Jun 13, 2025Recent research has delved into speech enhancement (SE) approaches that leverage audio embeddings from pre-trained models, diverging from time-frequency masking or signal prediction techniques. This paper introduces an efficient and extensible SE method. Our approach involves initially extracting audio embeddings from noisy speech using a pre-trained audioencoder, which are then denoised by a compact encoder network. Subsequently, a vocoder synthesizes the clean speech from denoised embeddings. An ablation study substantiates the parameter efficiency of the denoise encoder with a pre-trained audioencoder and vocoder. Experimental results on both speech enhancement and speaker fidelity demonstrate that our generative audioencoder-based SE system outperforms models utilizing discriminative audioencoders. Furthermore, subjective listening tests validate that our proposed system surpasses an existing state-of-the-art SE model in terms of perceptual quality.
GLAP: General contrastive audio-text pretraining across domains and languages
Jun 12, 2025



Contrastive Language Audio Pretraining (CLAP) is a widely-used method to bridge the gap between audio and text domains. Current CLAP methods enable sound and music retrieval in English, ignoring multilingual spoken content. To address this, we introduce general language audio pretraining (GLAP), which expands CLAP with multilingual and multi-domain abilities. GLAP demonstrates its versatility by achieving competitive performance on standard audio-text retrieval benchmarks like Clotho and AudioCaps, while significantly surpassing existing methods in speech retrieval and classification tasks. Additionally, GLAP achieves strong results on widely used sound-event zero-shot benchmarks, while simultaneously outperforming previous methods on speech content benchmarks. Further keyword spotting evaluations across 50 languages emphasize GLAP's advanced multilingual capabilities. Finally, multilingual sound and music understanding is evaluated across four languages. Checkpoints and Source: https://github.com/xiaomi-research/dasheng-glap.
A Model Compression Method with Matrix Product Operators for Speech Enhancement
Oct 10, 2020

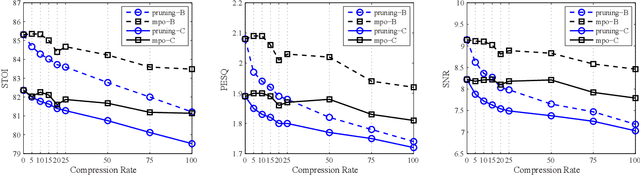

The deep neural network (DNN) based speech enhancement approaches have achieved promising performance. However, the number of parameters involved in these methods is usually enormous for the real applications of speech enhancement on the device with the limited resources. This seriously restricts the applications. To deal with this issue, model compression techniques are being widely studied. In this paper, we propose a model compression method based on matrix product operators (MPO) to substantially reduce the number of parameters in DNN models for speech enhancement. In this method, the weight matrices in the linear transformations of neural network model are replaced by the MPO decomposition format before training. In experiment, this process is applied to the causal neural network models, such as the feedforward multilayer perceptron (MLP) and long short-term memory (LSTM) models. Both MLP and LSTM models with/without compression are then utilized to estimate the ideal ratio mask for monaural speech enhancement. The experimental results show that our proposed MPO-based method outperforms the widely-used pruning method for speech enhancement under various compression rates, and further improvement can be achieved with respect to low compression rates. Our proposal provides an effective model compression method for speech enhancement, especially in cloud-free application.
* 11 pages, 6 figures, 7 tables