 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACAVCaps: Enabling large-scale training for fine-grained and diverse audio understanding
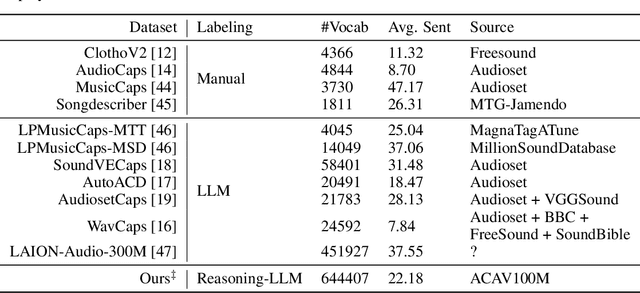
Mar 25, 2026General audio understanding is a fundamental goal for large audio-language models, with audio captioning serving as a cornerstone task for their development. However, progress in this domain is hindered by existing datasets, which lack the scale and descriptive granularity required to train truly versatile models. To address this gap, we introduce ACAVCaps, a new large-scale, fine-grained, and multi-faceted audio captioning dataset. Derived from the ACAV100M collection, ACAVCaps is constructed using a multi-expert pipeline that analyzes audio from diverse perspectives-including speech, music, and acoustic properties-which are then synthesized into rich, detailed descriptions by a large language model. Experimental results demonstrate that models pre-trained on ACAVCaps exhibit substantially stronger generalization capabilities on various downstream tasks compared to those trained on other leading captioning datasets. The dataset is available at https://github.com/xiaomi-research/acavcaps.
The Interspeech 2026 Audio Encoder Capability Challenge for Large Audio Language Models
Mar 24, 2026This paper presents the Interspeech 2026 Audio Encoder Capability Challenge, a benchmark specifically designed to evaluate and advance the performance of pre-trained audio encoders as front-end modules for Large Audio Language Models (LALMs). While LALMs have shown remarkable understanding of complex acoustic scenes, their performance depends on the semantic richness of the underlying audio encoder representations. This challenge addresses the integration gap by providing a unified generative evaluation framework, XARES-LLM, which assesses submitted encoders across a diverse suite of downstream classification and generation tasks. By decoupling encoder development from LLM fine-tuning, the challenge establishes a standardized protocol for general-purpose audio representations that can effectively be used for the next generation of multimodal language models.
DashengTokenizer: One layer is enough for unified audio understanding and generation
Feb 27, 2026This paper introduces DashengTokenizer, a continuous audio tokenizer engineered for joint use in both understanding and generation tasks. Unlike conventional approaches, which train acoustic tokenizers and subsequently integrate frozen semantic knowledge, our method inverts this paradigm: we leverage frozen semantic features and inject acoustic information. In linear evaluation across 22 diverse tasks, our method outperforms previous audio codec and audio encoder baselines by a significant margin while maintaining competitive audio reconstruction quality. Notably, we demonstrate that this acoustic injection improves performance for tasks such as speech emotion recognition, music understanding, and acoustic scene classification. We further evaluate the tokenizer's generative performance on text-to-audio (TTA), text-to-music (TTM), and speech enhancement (SE). Our approach surpasses standard variational autoencoder (VAE)-based methods on TTA and TTM tasks, while its effectiveness on SE underscores its capabilities as a general-purpose audio encoder. Finally, our results challenge the prevailing assumption that VAE-based architectures are a prerequisite for audio synthesis. Checkpoints are available at https://huggingface.co/mispeech/dashengtokenizer.
MiDashengLM: Efficient Audio Understanding with General Audio Captions
Aug 06, 2025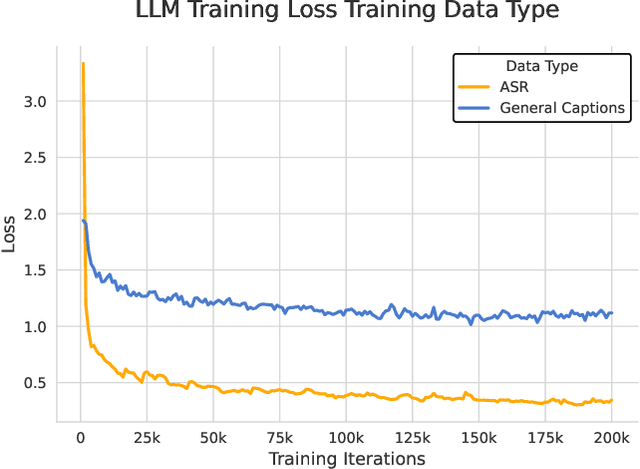

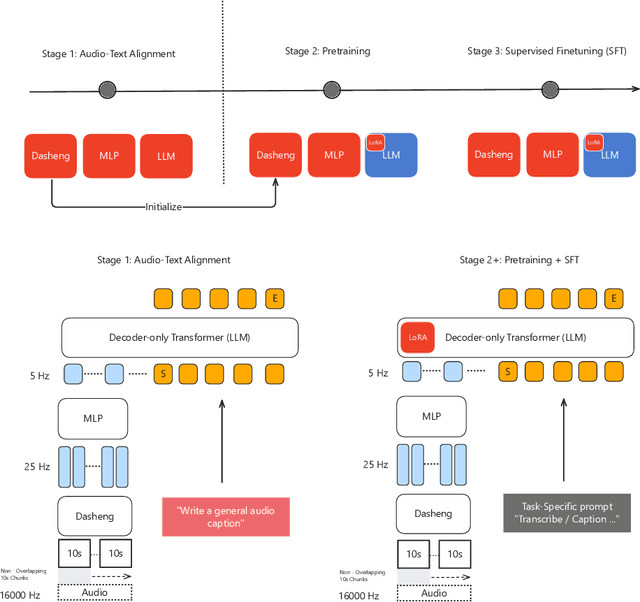
Current approaches for large audio language models (LALMs) often rely on closed data sources or proprietary models, limiting their generalization and accessibility. This paper introduces MiDashengLM, a novel open audio-language model designed for efficient and comprehensive audio understanding through the use of general audio captions using our novel ACAVCaps training dataset. MiDashengLM exclusively relies on publicly available pretraining and supervised fine-tuning (SFT) datasets, ensuring full transparency and reproducibility. At its core, MiDashengLM integrates Dasheng, an open-source audio encoder, specifically engineered to process diverse auditory information effectively. Unlike previous works primarily focused on Automatic Speech Recognition (ASR) based audio-text alignment, our strategy centers on general audio captions, fusing speech, sound and music information into one textual representation, enabling a holistic textual representation of complex audio scenes. Lastly, MiDashengLM provides an up to 4x speedup in terms of time-to-first-token (TTFT) and up to 20x higher throughput than comparable models. Checkpoints are available online at https://huggingface.co/mispeech/midashenglm-7b and https://github.com/xiaomi-research/dasheng-lm.
VEnvision3D: A Synthetic Perception Dataset for 3D Multi-Task Model Research
Mar 05, 2024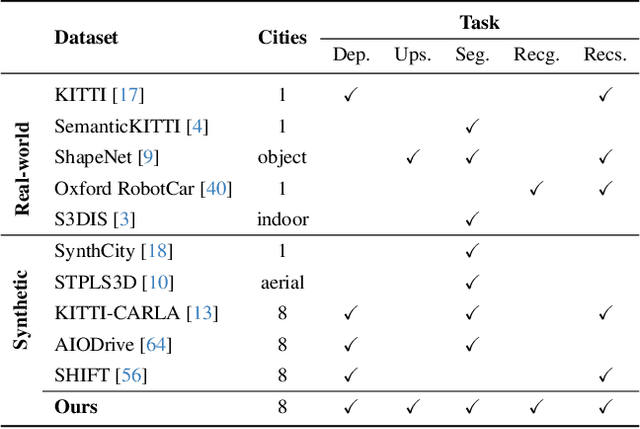
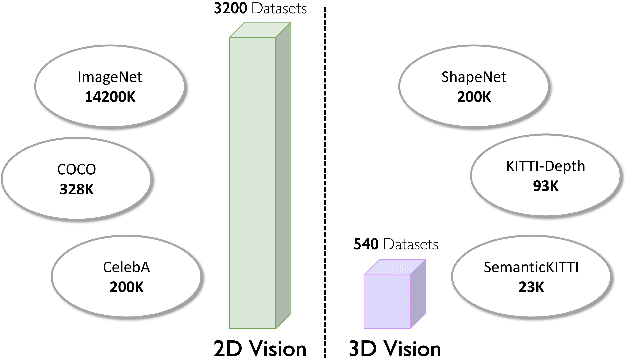


Developing a unified multi-task foundation model has become a critical challenge in computer vision research. In the current field of 3D computer vision, most datasets only focus on single task, which complicates the concurrent training requirements of various downstream tasks. In this paper, we introduce VEnvision3D, a large 3D synthetic perception dataset for multi-task learning, including depth completion, segmentation, upsampling, place recognition, and 3D reconstruction. Since the data for each task is collected in the same environmental domain, sub-tasks are inherently aligned in terms of the utilized data. Therefore, such a unique attribute can assist in exploring the potential for the multi-task model and even the foundation model without separate training methods. Meanwhile, capitalizing on the advantage of virtual environments being freely editable, we implement some novel settings such as simulating temporal changes in the environment and sampling point clouds on model surfaces. These characteristics enable us to present several new benchmarks. We also perform extensive studies on multi-task end-to-end models, revealing new observations, challenges, and opportunities for future research. Our dataset and code will be open-sourced upon acceptance.
Optimized Design Method for Satellite Constellation Configuration Based on Real-time Coverage Area Evaluation
Sep 16, 2022
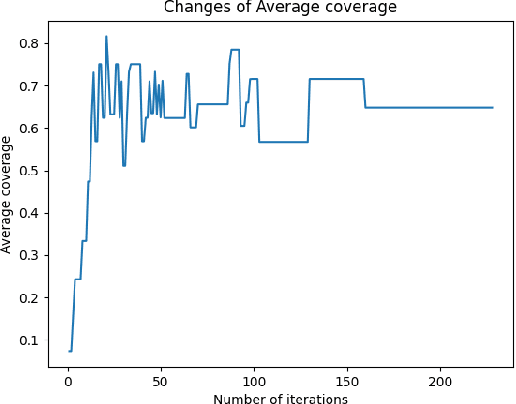
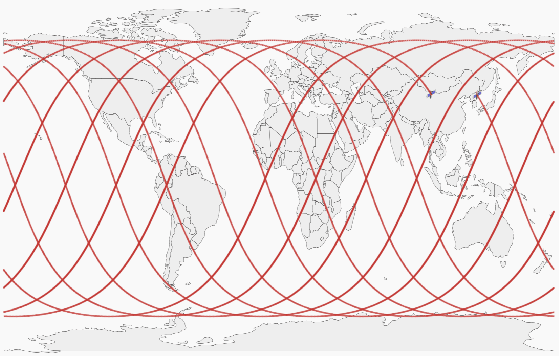
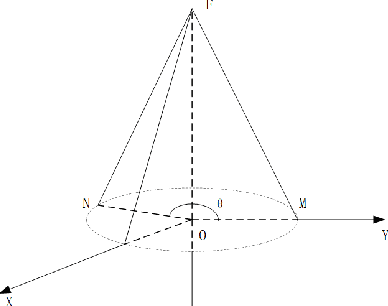
When using constellation synergy to image large areas for reconnaissance, it is required to achieve the coverage capability requirements with minimal consumption of observation resources to obtain the most optimal constellation observation scheme. With the minimum number of satellites and meeting the real-time ground coverage requirements as the optimization objectives, this paper proposes an optimized design of satellite constellation configuration for full coverage of large-scale regional imaging by using an improved simulated annealing algorithm combined with the real-time coverage evaluation method of hexagonal discretization. The algorithm can adapt to experimental conditions, has good efficiency, and can meet industrial accuracy requirements. The effectiveness and adaptability of the algorithm are tested in simulation applications.
Joint Matrix Decomposition for Deep Convolutional Neural Networks Compression
Jul 12, 2021
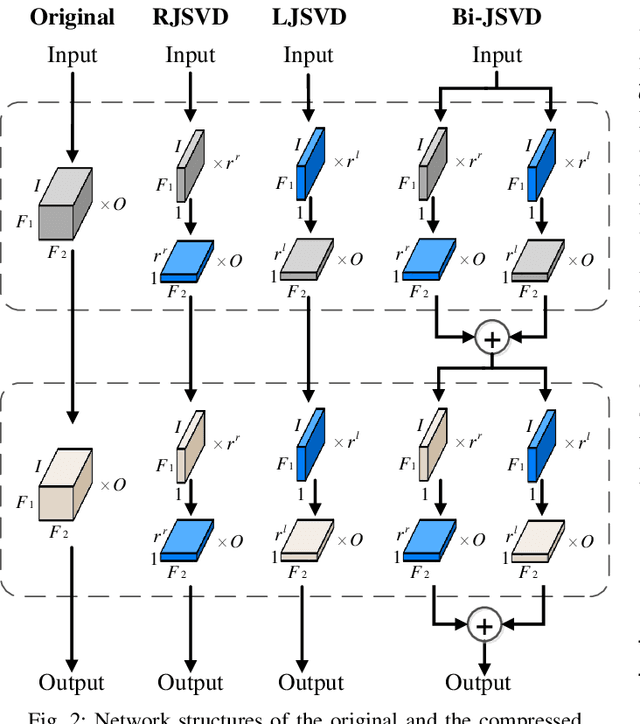
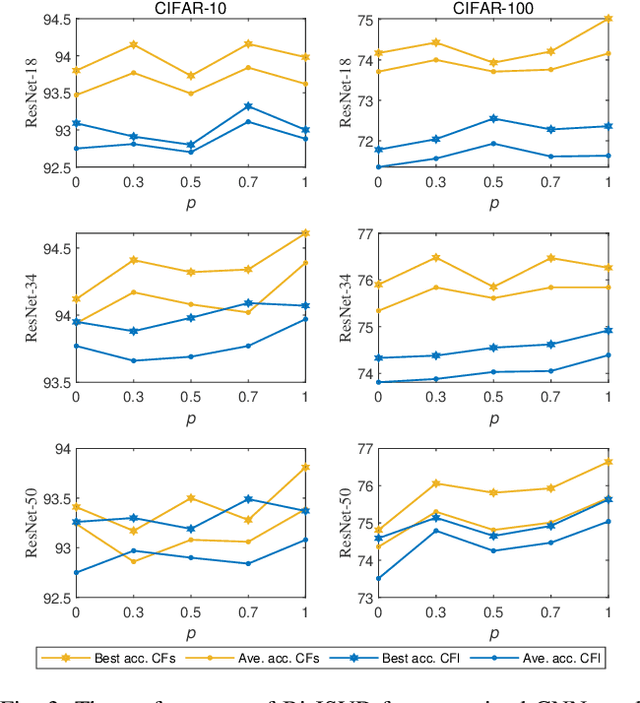
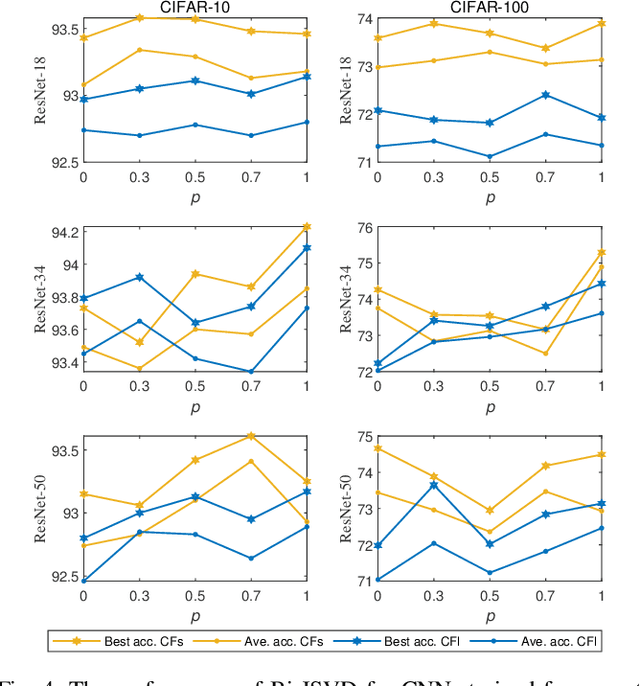
Deep convolutional neural networks (CNNs) with a large number of parameters requires huge computational resources, which has limited the application of CNNs on resources constrained appliances. Decomposition-based methods, therefore, have been utilized to compress CNNs in recent years. However, since the compression factor and performance are negatively correlated, the state-of-the-art works either suffer from severe performance degradation or have limited low compression factors. To overcome these problems, unlike previous works compressing layers separately, we propose to compress CNNs and alleviate performance degradation via joint matrix decomposition. The idea is inspired by the fact that there are lots of repeated modules in CNNs, and by projecting weights with the same structures into the same subspace, networks can be further compressed and even accelerated. In particular, three joint matrix decomposition schemes are developed, and the corresponding optimization approaches based on Singular Values Decomposition are proposed. Extensive experiments are conducted across three challenging compact CNNs and 3 benchmark data sets to demonstrate the superior performance of our proposed algorithms. As a result, our methods can compress the size of ResNet-34 by 22x with slighter accuracy degradation compared with several state-of-the-art methods.