 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVEnvision3D: A Synthetic Perception Dataset for 3D Multi-Task Model Research
Paper and Code
Mar 05, 2024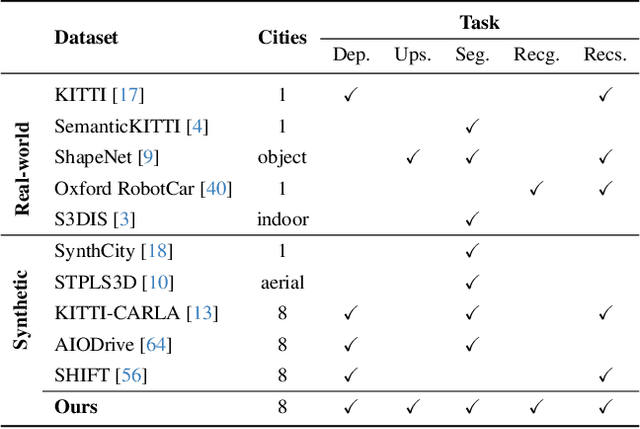
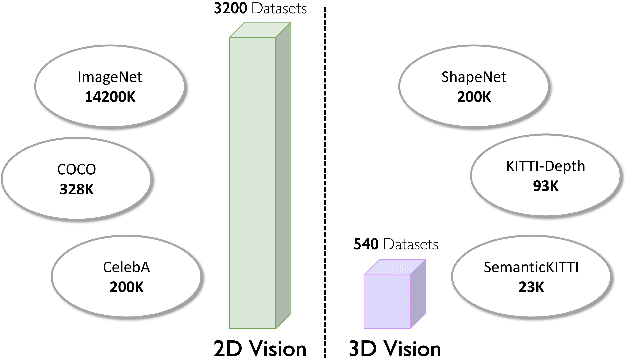


Developing a unified multi-task foundation model has become a critical challenge in computer vision research. In the current field of 3D computer vision, most datasets only focus on single task, which complicates the concurrent training requirements of various downstream tasks. In this paper, we introduce VEnvision3D, a large 3D synthetic perception dataset for multi-task learning, including depth completion, segmentation, upsampling, place recognition, and 3D reconstruction. Since the data for each task is collected in the same environmental domain, sub-tasks are inherently aligned in terms of the utilized data. Therefore, such a unique attribute can assist in exploring the potential for the multi-task model and even the foundation model without separate training methods. Meanwhile, capitalizing on the advantage of virtual environments being freely editable, we implement some novel settings such as simulating temporal changes in the environment and sampling point clouds on model surfaces. These characteristics enable us to present several new benchmarks. We also perform extensive studies on multi-task end-to-end models, revealing new observations, challenges, and opportunities for future research. Our dataset and code will be open-sourced upon acceptance.