 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRALLY: Role-Adaptive LLM-Driven Yoked Navigation for Agentic UAV Swarms
Jul 02, 2025Intelligent control of Unmanned Aerial Vehicles (UAVs) swarms has emerged as a critical research focus, and it typically requires the swarm to navigate effectively while avoiding obstacles and achieving continuous coverage over multiple mission targets. Although traditional Multi-Agent Reinforcement Learning (MARL) approaches offer dynamic adaptability, they are hindered by the semantic gap in numerical communication and the rigidity of homogeneous role structures, resulting in poor generalization and limited task scalability. Recent advances in Large Language Model (LLM)-based control frameworks demonstrate strong semantic reasoning capabilities by leveraging extensive prior knowledge. However, due to the lack of online learning and over-reliance on static priors, these works often struggle with effective exploration, leading to reduced individual potential and overall system performance. To address these limitations, we propose a Role-Adaptive LLM-Driven Yoked navigation algorithm RALLY. Specifically, we first develop an LLM-driven semantic decision framework that uses structured natural language for efficient semantic communication and collaborative reasoning. Afterward, we introduce a dynamic role-heterogeneity mechanism for adaptive role switching and personalized decision-making. Furthermore, we propose a Role-value Mixing Network (RMIX)-based assignment strategy that integrates LLM offline priors with MARL online policies to enable semi-offline training of role selection strategies. Experiments in the Multi-Agent Particle Environment (MPE) environment and a Software-In-The-Loop (SITL) platform demonstrate that RALLY outperforms conventional approaches in terms of task coverage, convergence speed, and generalization, highlighting its strong potential for collaborative navigation in agentic multi-UAV systems.
SpatialLLM: From Multi-modality Data to Urban Spatial Intelligence
May 19, 2025We propose SpatialLLM, a novel approach advancing spatial intelligence tasks in complex urban scenes. Unlike previous methods requiring geographic analysis tools or domain expertise, SpatialLLM is a unified language model directly addressing various spatial intelligence tasks without any training, fine-tuning, or expert intervention. The core of SpatialLLM lies in constructing detailed and structured scene descriptions from raw spatial data to prompt pre-trained LLMs for scene-based analysis. Extensive experiments show that, with our designs, pretrained LLMs can accurately perceive spatial distribution information and enable zero-shot execution of advanced spatial intelligence tasks, including urban planning, ecological analysis, traffic management, etc. We argue that multi-field knowledge, context length, and reasoning ability are key factors influencing LLM performances in urban analysis. We hope that SpatialLLM will provide a novel viable perspective for urban intelligent analysis and management. The code and dataset are available at https://github.com/WHU-USI3DV/SpatialLLM.
ME-CPT: Multi-Task Enhanced Cross-Temporal Point Transformer for Urban 3D Change Detection
Jan 23, 2025



The point clouds collected by the Airborne Laser Scanning (ALS) system provide accurate 3D information of urban land covers. By utilizing multi-temporal ALS point clouds, semantic changes in urban area can be captured, demonstrating significant potential in urban planning, emergency management, and infrastructure maintenance. Existing 3D change detection methods struggle to efficiently extract multi-class semantic information and change features, still facing the following challenges: (1) the difficulty of accurately modeling cross-temporal point clouds spatial relationships for effective change feature extraction; (2) class imbalance of change samples which hinders distinguishability of semantic features; (3) the lack of real-world datasets for 3D semantic change detection. To resolve these challenges, we propose the Multi-task Enhanced Cross-temporal Point Transformer (ME-CPT) network. ME-CPT establishes spatiotemporal correspondences between point cloud across different epochs and employs attention mechanisms to jointly extract semantic change features, facilitating information exchange and change comparison. Additionally, we incorporate a semantic segmentation task and through the multi-task training strategy, further enhance the distinguishability of semantic features, reducing the impact of class imbalance in change types. Moreover, we release a 22.5 $km^2$ 3D semantic change detection dataset, offering diverse scenes for comprehensive evaluation. Experiments on multiple datasets show that the proposed MT-CPT achieves superior performance compared to existing state-of-the-art methods. The source code and dataset will be released upon acceptance at \url{https://github.com/zhangluqi0209/ME-CPT}.
GAGS: Granularity-Aware Feature Distillation for Language Gaussian Splatting
Dec 18, 20243D open-vocabulary scene understanding, which accurately perceives complex semantic properties of objects in space, has gained significant attention in recent years. In this paper, we propose GAGS, a framework that distills 2D CLIP features into 3D Gaussian splatting, enabling open-vocabulary queries for renderings on arbitrary viewpoints. The main challenge of distilling 2D features for 3D fields lies in the multiview inconsistency of extracted 2D features, which provides unstable supervision for the 3D feature field. GAGS addresses this challenge with two novel strategies. First, GAGS associates the prompt point density of SAM with the camera distances, which significantly improves the multiview consistency of segmentation results. Second, GAGS further decodes a granularity factor to guide the distillation process and this granularity factor can be learned in a unsupervised manner to only select the multiview consistent 2D features in the distillation process. Experimental results on two datasets demonstrate significant performance and stability improvements of GAGS in visual grounding and semantic segmentation, with an inference speed 2$\times$ faster than baseline methods. The code and additional results are available at https://pz0826.github.io/GAGS-Webpage/ .
ONION: Physics-Informed Deep Learning Model for Line Integral Diagnostics Across Fusion Devices
Nov 27, 2024This paper introduces a Physics-Informed model architecture that can be adapted to various backbone networks. The model incorporates physical information as additional input and is constrained by a Physics-Informed loss function. Experimental results demonstrate that the additional input of physical information substantially improve the model's ability with a increase in performance observed. Besides, the adoption of the Softplus activation function in the final two fully connected layers significantly enhances model performance. The incorporation of a Physics-Informed loss function has been shown to correct the model's predictions, bringing the back-projections closer to the actual inputs and reducing the errors associated with inversion algorithms. In this work, we have developed a Phantom Data Model to generate customized line integral diagnostic datasets and have also collected SXR diagnostic datasets from EAST and HL-2A. The code, models, and some datasets are publicly available at https://github.com/calledice/onion.
VistaDream: Sampling multiview consistent images for single-view scene reconstruction
Oct 22, 2024



In this paper, we propose VistaDream a novel framework to reconstruct a 3D scene from a single-view image. Recent diffusion models enable generating high-quality novel-view images from a single-view input image. Most existing methods only concentrate on building the consistency between the input image and the generated images while losing the consistency between the generated images. VistaDream addresses this problem by a two-stage pipeline. In the first stage, VistaDream begins with building a global coarse 3D scaffold by zooming out a little step with inpainted boundaries and an estimated depth map. Then, on this global scaffold, we use iterative diffusion-based RGB-D inpainting to generate novel-view images to inpaint the holes of the scaffold. In the second stage, we further enhance the consistency between the generated novel-view images by a novel training-free Multiview Consistency Sampling (MCS) that introduces multi-view consistency constraints in the reverse sampling process of diffusion models. Experimental results demonstrate that without training or fine-tuning existing diffusion models, VistaDream achieves consistent and high-quality novel view synthesis using just single-view images and outperforms baseline methods by a large margin. The code, videos, and interactive demos are available at https://vistadream-project-page.github.io/.
Exploiting Motion Prior for Accurate Pose Estimation of Dashboard Cameras
Sep 27, 2024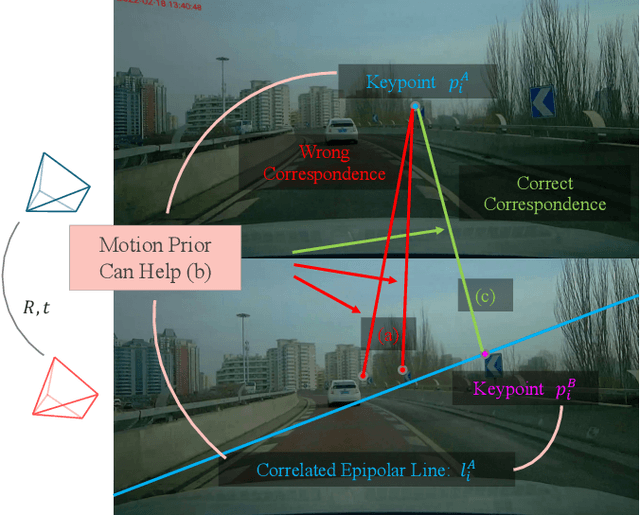

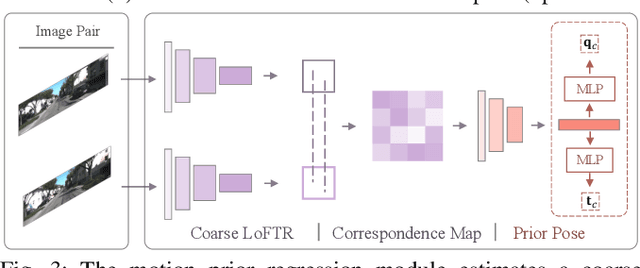
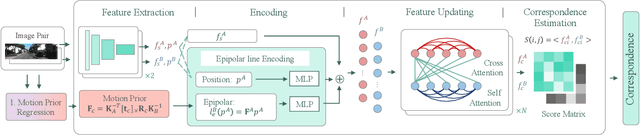
Dashboard cameras (dashcams) record millions of driving videos daily, offering a valuable potential data source for various applications, including driving map production and updates. A necessary step for utilizing these dashcam data involves the estimation of camera poses. However, the low-quality images captured by dashcams, characterized by motion blurs and dynamic objects, pose challenges for existing image-matching methods in accurately estimating camera poses. In this study, we propose a precise pose estimation method for dashcam images, leveraging the inherent camera motion prior. Typically, image sequences captured by dash cameras exhibit pronounced motion prior, such as forward movement or lateral turns, which serve as essential cues for correspondence estimation. Building upon this observation, we devise a pose regression module aimed at learning camera motion prior, subsequently integrating these prior into both correspondences and pose estimation processes. The experiment shows that, in real dashcams dataset, our method is 22% better than the baseline for pose estimation in AUC5\textdegree, and it can estimate poses for 19% more images with less reprojection error in Structure from Motion (SfM).
VEnvision3D: A Synthetic Perception Dataset for 3D Multi-Task Model Research
Mar 05, 2024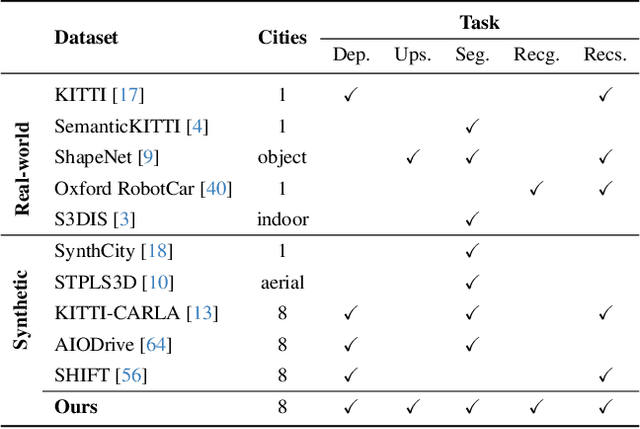
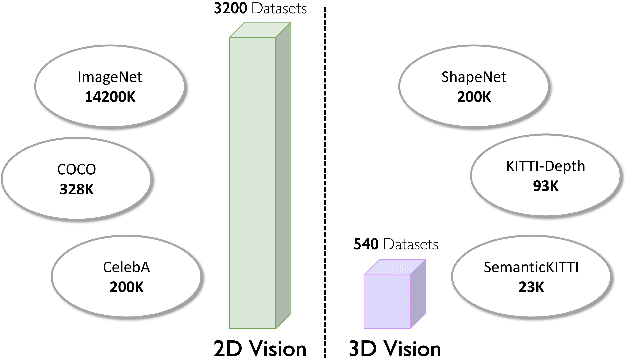


Developing a unified multi-task foundation model has become a critical challenge in computer vision research. In the current field of 3D computer vision, most datasets only focus on single task, which complicates the concurrent training requirements of various downstream tasks. In this paper, we introduce VEnvision3D, a large 3D synthetic perception dataset for multi-task learning, including depth completion, segmentation, upsampling, place recognition, and 3D reconstruction. Since the data for each task is collected in the same environmental domain, sub-tasks are inherently aligned in terms of the utilized data. Therefore, such a unique attribute can assist in exploring the potential for the multi-task model and even the foundation model without separate training methods. Meanwhile, capitalizing on the advantage of virtual environments being freely editable, we implement some novel settings such as simulating temporal changes in the environment and sampling point clouds on model surfaces. These characteristics enable us to present several new benchmarks. We also perform extensive studies on multi-task end-to-end models, revealing new observations, challenges, and opportunities for future research. Our dataset and code will be open-sourced upon acceptance.
SparseDC: Depth Completion from sparse and non-uniform inputs
Nov 30, 2023We propose SparseDC, a model for Depth Completion of Sparse and non-uniform depth inputs. Unlike previous methods focusing on completing fixed distributions on benchmark datasets (e.g., NYU with 500 points, KITTI with 64 lines), SparseDC is specifically designed to handle depth maps with poor quality in real usage. The key contributions of SparseDC are two-fold. First, we design a simple strategy, called SFFM, to improve the robustness under sparse input by explicitly filling the unstable depth features with stable image features. Second, we propose a two-branch feature embedder to predict both the precise local geometry of regions with available depth values and accurate structures in regions with no depth. The key of the embedder is an uncertainty-based fusion module called UFFM to balance the local and long-term information extracted by CNNs and ViTs. Extensive indoor and outdoor experiments demonstrate the robustness of our framework when facing sparse and non-uniform input depths. The pre-trained model and code are available at https://github.com/WHU-USI3DV/SparseDC.
FreeReg: Image-to-Point Cloud Registration Leveraging Pretrained Diffusion Models and Monocular Depth Estimators
Oct 05, 2023



Matching cross-modality features between images and point clouds is a fundamental problem for image-to-point cloud registration. However, due to the modality difference between images and points, it is difficult to learn robust and discriminative cross-modality features by existing metric learning methods for feature matching. Instead of applying metric learning on cross-modality data, we propose to unify the modality between images and point clouds by pretrained large-scale models first, and then establish robust correspondence within the same modality. We show that the intermediate features, called diffusion features, extracted by depth-to-image diffusion models are semantically consistent between images and point clouds, which enables the building of coarse but robust cross-modality correspondences. We further extract geometric features on depth maps produced by the monocular depth estimator. By matching such geometric features, we significantly improve the accuracy of the coarse correspondences produced by diffusion features. Extensive experiments demonstrate that without any task-specific training, direct utilization of both features produces accurate image-to-point cloud registration. On three public indoor and outdoor benchmarks, the proposed method averagely achieves a 20.6 percent improvement in Inlier Ratio, a three-fold higher Inlier Number, and a 48.6 percent improvement in Registration Recall than existing state-of-the-arts.