 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised MR-US Multimodal Image Registration with Multilevel Correlation Pyramidal Optimization
Feb 16, 2026Surgical navigation based on multimodal image registration has played a significant role in providing intraoperative guidance to surgeons by showing the relative position of the target area to critical anatomical structures during surgery. However, due to the differences between multimodal images and intraoperative image deformation caused by tissue displacement and removal during the surgery, effective registration of preoperative and intraoperative multimodal images faces significant challenges. To address the multimodal image registration challenges in Learn2Reg 2025, an unsupervised multimodal medical image registration method based on Multilevel Correlation Pyramidal Optimization (MCPO) is designed to solve these problems. First, the features of each modality are extracted based on the modality independent neighborhood descriptor, and the multimodal images is mapped to the feature space. Second, a multilevel pyramidal fusion optimization mechanism is designed to achieve global optimization and local detail complementation of the displacement field through dense correlation analysis and weight-balanced coupled convex optimization for input features at different scales. Our method focuses on the ReMIND2Reg task in Learn2Reg 2025. Based on the results, our method achieved the first place in the validation phase and test phase of ReMIND2Reg. The MCPO is also validated on the Resect dataset, achieving an average TRE of 1.798 mm. This demonstrates the broad applicability of our method in preoperative-to-intraoperative image registration. The code is available at https://github.com/wjiazheng/MCPO.
EPIC: Efficient Prompt Interaction for Text-Image Classification
Jul 10, 2025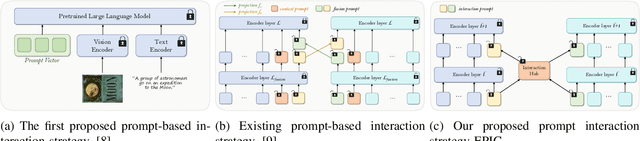
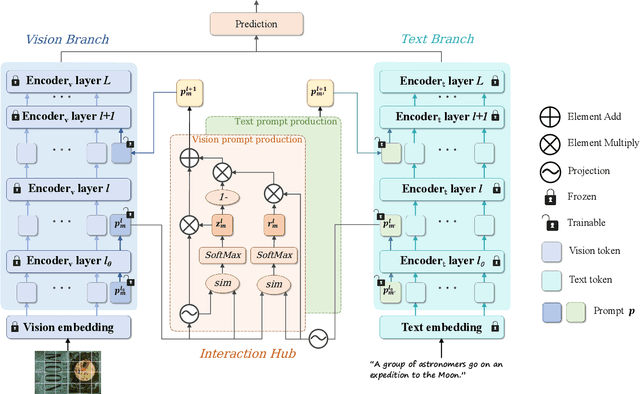
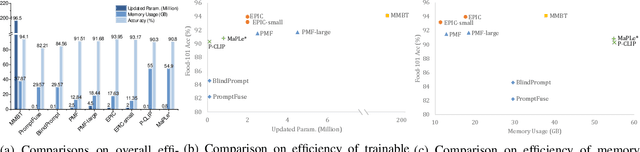

In recent years, large-scale pre-trained multimodal models (LMMs) generally emerge to integrate the vision and language modalities, achieving considerable success in multimodal tasks, such as text-image classification. The growing size of LMMs, however, results in a significant computational cost for fine-tuning these models for downstream tasks. Hence, prompt-based interaction strategy is studied to align modalities more efficiently. In this context, we propose a novel efficient prompt-based multimodal interaction strategy, namely Efficient Prompt Interaction for text-image Classification (EPIC). Specifically, we utilize temporal prompts on intermediate layers, and integrate different modalities with similarity-based prompt interaction, to leverage sufficient information exchange between modalities. Utilizing this approach, our method achieves reduced computational resource consumption and fewer trainable parameters (about 1\% of the foundation model) compared to other fine-tuning strategies. Furthermore, it demonstrates superior performance on the UPMC-Food101 and SNLI-VE datasets, while achieving comparable performance on the MM-IMDB dataset.
ONION: Physics-Informed Deep Learning Model for Line Integral Diagnostics Across Fusion Devices
Nov 27, 2024This paper introduces a Physics-Informed model architecture that can be adapted to various backbone networks. The model incorporates physical information as additional input and is constrained by a Physics-Informed loss function. Experimental results demonstrate that the additional input of physical information substantially improve the model's ability with a increase in performance observed. Besides, the adoption of the Softplus activation function in the final two fully connected layers significantly enhances model performance. The incorporation of a Physics-Informed loss function has been shown to correct the model's predictions, bringing the back-projections closer to the actual inputs and reducing the errors associated with inversion algorithms. In this work, we have developed a Phantom Data Model to generate customized line integral diagnostic datasets and have also collected SXR diagnostic datasets from EAST and HL-2A. The code, models, and some datasets are publicly available at https://github.com/calledice/onion.
Memory-Inspired Temporal Prompt Interaction for Text-Image Classification
Jan 26, 2024In recent years, large-scale pre-trained multimodal models (LMM) generally emerge to integrate the vision and language modalities, achieving considerable success in various natural language processing and computer vision tasks. The growing size of LMMs, however, results in a significant computational cost for fine-tuning these models for downstream tasks. Hence, prompt-based interaction strategy is studied to align modalities more efficiently. In this contex, we propose a novel prompt-based multimodal interaction strategy inspired by human memory strategy, namely Memory-Inspired Temporal Prompt Interaction (MITP). Our proposed method involves in two stages as in human memory strategy: the acquiring stage, and the consolidation and activation stage. We utilize temporal prompts on intermediate layers to imitate the acquiring stage, leverage similarity-based prompt interaction to imitate memory consolidation, and employ prompt generation strategy to imitate memory activation. The main strength of our paper is that we interact the prompt vectors on intermediate layers to leverage sufficient information exchange between modalities, with compressed trainable parameters and memory usage. We achieve competitive results on several datasets with relatively small memory usage and 2.0M of trainable parameters (about 1% of the pre-trained foundation model).
COVID-19 Fake News Detection Using Bidirectional Encoder Representations from Transformers Based Models
Oct 01, 2021

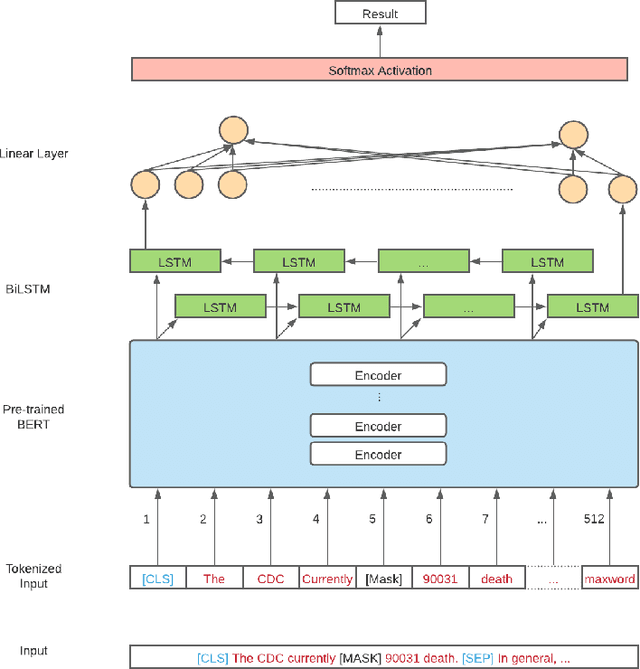
Nowadays, the development of social media allows people to access the latest news easily. During the COVID-19 pandemic, it is important for people to access the news so that they can take corresponding protective measures. However, the fake news is flooding and is a serious issue especially under the global pandemic. The misleading fake news can cause significant loss in terms of the individuals and the society. COVID-19 fake news detection has become a novel and important task in the NLP field. However, fake news always contain the correct portion and the incorrect portion. This fact increases the difficulty of the classification task. In this paper, we fine tune the pre-trained Bidirectional Encoder Representations from Transformers (BERT) model as our base model. We add BiLSTM layers and CNN layers on the top of the finetuned BERT model with frozen parameters or not frozen parameters methods respectively. The model performance evaluation results showcase that our best model (BERT finetuned model with frozen parameters plus BiLSTM layers) achieves state-of-the-art results towards COVID-19 fake news detection task. We also explore keywords evaluation methods using our best model and evaluate the model performance after removing keywords.