 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking the accuracy-resource dilemma: a lightweight adaptive video inference enhancement
Jan 21, 2026Existing video inference (VI) enhancement methods typically aim to improve performance by scaling up model sizes and employing sophisticated network architectures. While these approaches demonstrated state-of-the-art performance, they often overlooked the trade-off of resource efficiency and inference effectiveness, leading to inefficient resource utilization and suboptimal inference performance. To address this problem, a fuzzy controller (FC-r) is developed based on key system parameters and inference-related metrics. Guided by the FC-r, a VI enhancement framework is proposed, where the spatiotemporal correlation of targets across adjacent video frames is leveraged. Given the real-time resource conditions of the target device, the framework can dynamically switch between models of varying scales during VI. Experimental results demonstrate that the proposed method effectively achieves a balance between resource utilization and inference performance.
CF-Net: A Cross-Feature Reconstruction Network for High-Accuracy 1-Bit Target Classification
Dec 17, 2025



Target classification is a fundamental task in radar systems, and its performance critically depends on the quantization precision of the signal. While high-precision quantization (e.g. 16-bit) is well established, 1-bit quantization offers distinct advantages by enabling direct sampling at high frequencies and eliminating complex intermediate stages. However, its extreme quantization leads to significant information loss. Although higher sampling rates can compensate for this loss, such oversampling is impractical at the high frequencies targeted for direct sampling. To achieve high-accuracy classification directly from 1-bit radar data under the same sampling rate, this paper proposes a novel two-stage deep learning framework, CF-Net. First, we introduce a self-supervised pre-training strategy based on a dual-branch U-Net architecture. This network learns to restore high-fidelity 16-bit images from their 1-bit counterparts via a cross-feature reconstruction task, forcing the 1-bit encoder to learn robust features despite extreme quantization. Subsequently, this pre-trained encoder is repurposed and fine-tuned for the downstream multi-class target classification task. Experiments on two radar target datasets demonstrate that CF-Net can effectively extract discriminative features from 1-bit imagery, achieving comparable and even superior accuracy to some 16-bit methods without oversampling.
TinyDrop: Tiny Model Guided Token Dropping for Vision Transformers
Sep 03, 2025Vision Transformers (ViTs) achieve strong performance in image classification but incur high computational costs from processing all image tokens. To reduce inference costs in large ViTs without compromising accuracy, we propose TinyDrop, a training-free token dropping framework guided by a lightweight vision model. The guidance model estimates the importance of tokens while performing inference, thereby selectively discarding low-importance tokens if large vit models need to perform attention calculations. The framework operates plug-and-play, requires no architectural modifications, and is compatible with diverse ViT architectures. Evaluations on standard image classification benchmarks demonstrate that our framework reduces FLOPs by up to 80% for ViTs with minimal accuracy degradation, highlighting its generalization capability and practical utility for efficient ViT-based classification.
Optimal Brain Connection: Towards Efficient Structural Pruning
Aug 07, 2025Structural pruning has been widely studied for its effectiveness in compressing neural networks. However, existing methods often neglect the interconnections among parameters. To address this limitation, this paper proposes a structural pruning framework termed Optimal Brain Connection. First, we introduce the Jacobian Criterion, a first-order metric for evaluating the saliency of structural parameters. Unlike existing first-order methods that assess parameters in isolation, our criterion explicitly captures both intra-component interactions and inter-layer dependencies. Second, we propose the Equivalent Pruning mechanism, which utilizes autoencoders to retain the contributions of all original connection--including pruned ones--during fine-tuning. Experimental results demonstrate that the Jacobian Criterion outperforms several popular metrics in preserving model performance, while the Equivalent Pruning mechanism effectively mitigates performance degradation after fine-tuning. Code: https://github.com/ShaowuChen/Optimal_Brain_Connection
P-ROCKET: Pruning Random Convolution Kernels for Time Series Classification
Sep 15, 2023In recent years, two time series classification models, ROCKET and MINIROCKET, have attracted much attention for their low training cost and state-of-the-art accuracy. Utilizing random 1-D convolutional kernels without training, ROCKET and MINIROCKET can rapidly extract features from time series data, allowing for the efficient fitting of linear classifiers. However, to comprehensively capture useful features, a large number of random kernels are required, which is incompatible for resource-constrained devices. Therefore, a heuristic evolutionary algorithm named S-ROCKET is devised to recognize and prune redundant kernels. Nevertheless, the inherent nature of evolutionary algorithms renders the evaluation of kernels within S-ROCKET an unacceptable time-consuming process. In this paper, diverging from S-ROCKET, which directly evaluates random kernels with nonsignificant differences, we remove kernels from a feature selection perspective by eliminating associating connections in the sequential classification layer. To this end, we start by formulating the pruning challenge as a Group Elastic Net classification problem and employ the ADMM method to arrive at a solution. Sequentially, we accelerate the aforementioned time-consuming solving process by bifurcating the $l_{2,1}$ and $l_2$ regularizations into two sequential stages and solve them separately, which ultimately forms our core algorithm, named P-ROCKET. Stage 1 of P-ROCKET employs group-wise regularization similarly to our initial ADMM-based Algorithm, but introduces dynamically varying penalties to greatly accelerate the process. To mitigate overfitting, Stage 2 of P-ROCKET implements element-wise regularization to refit a linear classifier, utilizing the retained features.
WHC: Weighted Hybrid Criterion for Filter Pruning on Convolutional Neural Networks
Feb 16, 2023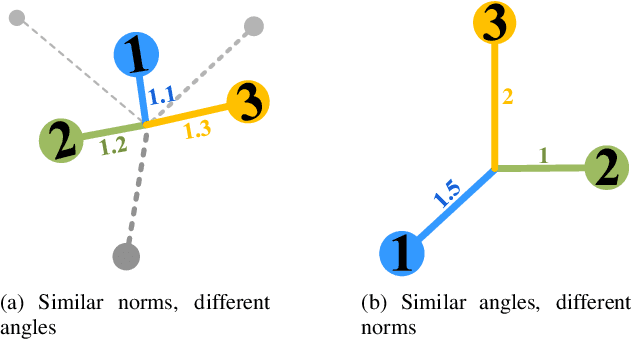


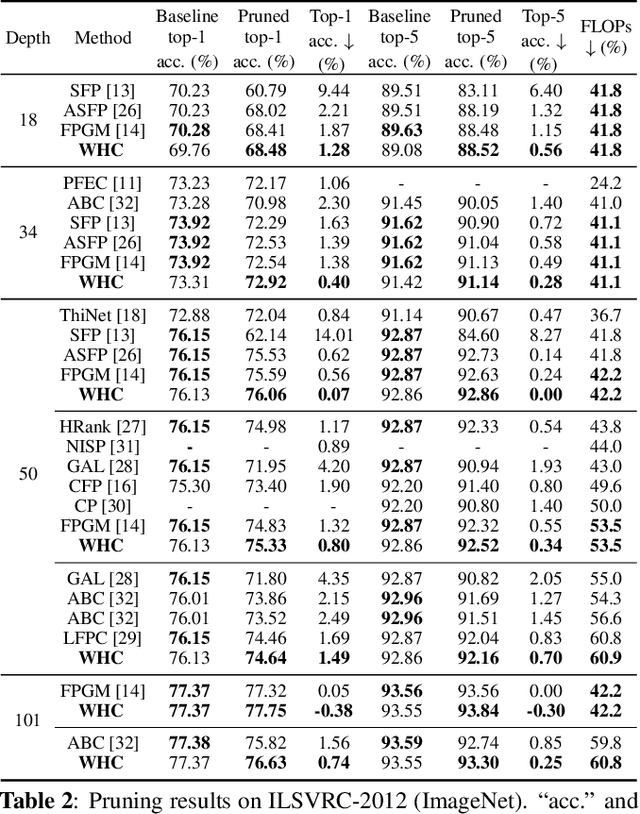
Filter pruning has attracted increasing attention in recent years for its capacity in compressing and accelerating convolutional neural networks. Various data-independent criteria, including norm-based and relationship-based ones, were proposed to prune the most unimportant filters. However, these state-of-the-art criteria fail to fully consider the dissimilarity of filters, and thus might lead to performance degradation. In this paper, we first analyze the limitation of relationship-based criteria with examples, and then introduce a new data-independent criterion, Weighted Hybrid Criterion (WHC), to tackle the problems of both norm-based and relationship-based criteria. By taking the magnitude of each filter and the linear dependence between filters into consideration, WHC can robustly recognize the most redundant filters, which can be safely pruned without introducing severe performance degradation to networks. Extensive pruning experiments in a simple one-shot manner demonstrate the effectiveness of the proposed WHC. In particular, WHC can prune ResNet-50 on ImageNet with more than 42% of floating point operations reduced without any performance loss in top-5 accuracy.
Joint Matrix Decomposition for Deep Convolutional Neural Networks Compression
Jul 12, 2021
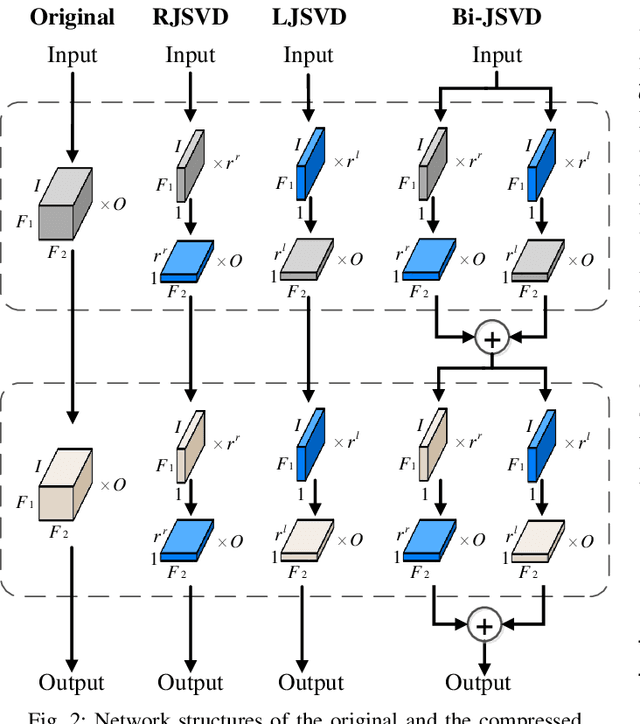
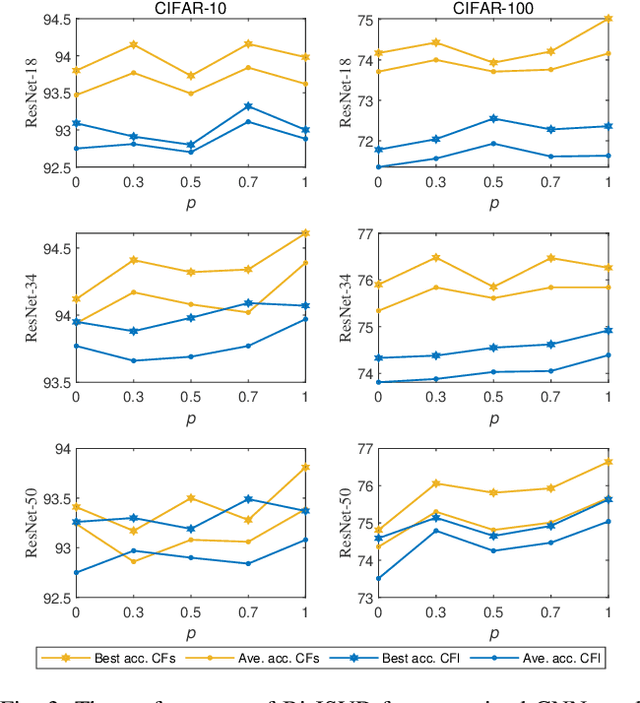
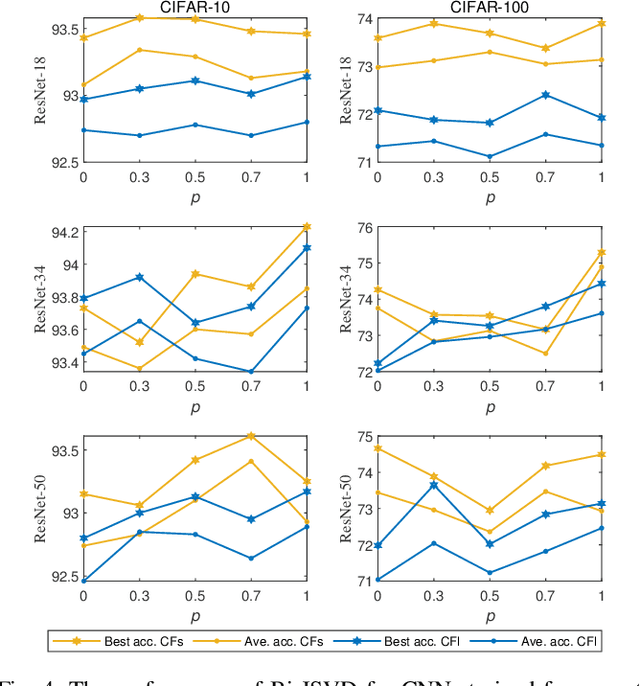
Deep convolutional neural networks (CNNs) with a large number of parameters requires huge computational resources, which has limited the application of CNNs on resources constrained appliances. Decomposition-based methods, therefore, have been utilized to compress CNNs in recent years. However, since the compression factor and performance are negatively correlated, the state-of-the-art works either suffer from severe performance degradation or have limited low compression factors. To overcome these problems, unlike previous works compressing layers separately, we propose to compress CNNs and alleviate performance degradation via joint matrix decomposition. The idea is inspired by the fact that there are lots of repeated modules in CNNs, and by projecting weights with the same structures into the same subspace, networks can be further compressed and even accelerated. In particular, three joint matrix decomposition schemes are developed, and the corresponding optimization approaches based on Singular Values Decomposition are proposed. Extensive experiments are conducted across three challenging compact CNNs and 3 benchmark data sets to demonstrate the superior performance of our proposed algorithms. As a result, our methods can compress the size of ResNet-34 by 22x with slighter accuracy degradation compared with several state-of-the-art methods.