 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEEG-FuseFormer: A Transformer-Driven Feature Fusion Framework for Seizure Onset Prediction
Jun 01, 2026Epilepsy is one of the most common neurological disorders globally, characterized by recurring seizures and significantly impacting the quality of life. Despite advancements in diagnostic techniques, the mitigation of risks faced by epilepsy patients remains challenging due to the unpredictability of seizure events. An accurate forecast of seizure onset helps to reduce risks in epilepsy patients. In this paper, we propose EEG-FuseFormer, a transformer-based feature fusion framework for seizure-onset prediction that combines intermediate features extracted from Convolutional Neural Networks-Long Short-Term Memory (CNN-LSTM) and ResNet-18 networks. The CNN-LSTM architecture captures both spatial and temporal features directly from the raw signal, whereas the ResNet-18 extracts features from the Short-Time Fourier Transform (STFT) representation of the EEG signals. Fusion is carried out using a transformer encoder, and the final prediction is generated using fully connected dense layers. The CHB-MIT dataset was used to validate the proposed model. The results show that the proposed model achieves a mean recall of 98.85% and outperforms most of the state-of-the-art methods. This study evaluates the ability of the proposed feature fusion model to generalize in cross-patient testing scenarios. Fine-tuning pre-trained models on limited target patient data (target adaptation) within the cross-patient validation framework results in higher recall, precision, and F1-score metrics in comparison to the conventional cross-patient validation approach. Finally, the runtime-based computational complexity of the model is assessed across diverse hardware platforms to highlight the performance-complexity trade-off.
WISP: Waste- and Interference-Suppressed Distributed Speculative LLM Serving at the Edge via Dynamic Drafting and SLO-Aware Batching
Jan 15, 2026As Large Language Models (LLMs) become increasingly accessible to end users, an ever-growing number of inference requests are initiated from edge devices and computed on centralized GPU clusters. However, the resulting exponential growth in computation workload is placing significant strain on data centers, while edge devices remain largely underutilized, leading to imbalanced workloads and resource inefficiency across the network. Integrating edge devices into the LLM inference process via speculative decoding helps balance the workload between the edge and the cloud, while maintaining lossless prediction accuracy. In this paper, we identify and formalize two critical bottlenecks that limit the efficiency and scalability of distributed speculative LLM serving: Wasted Drafting Time and Verification Interference. To address these challenges, we propose WISP, an efficient and SLO-aware distributed LLM inference system that consists of an intelligent speculation controller, a verification time estimator, and a verification batch scheduler. These components collaboratively enhance drafting efficiency and optimize verification request scheduling on the server. Extensive numerical results show that WISP improves system capacity by up to 2.1x and 4.1x, and increases system goodput by up to 1.94x and 3.7x, compared to centralized serving and SLED, respectively.
TinyDrop: Tiny Model Guided Token Dropping for Vision Transformers
Sep 03, 2025Vision Transformers (ViTs) achieve strong performance in image classification but incur high computational costs from processing all image tokens. To reduce inference costs in large ViTs without compromising accuracy, we propose TinyDrop, a training-free token dropping framework guided by a lightweight vision model. The guidance model estimates the importance of tokens while performing inference, thereby selectively discarding low-importance tokens if large vit models need to perform attention calculations. The framework operates plug-and-play, requires no architectural modifications, and is compatible with diverse ViT architectures. Evaluations on standard image classification benchmarks demonstrate that our framework reduces FLOPs by up to 80% for ViTs with minimal accuracy degradation, highlighting its generalization capability and practical utility for efficient ViT-based classification.
Optimal Brain Connection: Towards Efficient Structural Pruning
Aug 07, 2025Structural pruning has been widely studied for its effectiveness in compressing neural networks. However, existing methods often neglect the interconnections among parameters. To address this limitation, this paper proposes a structural pruning framework termed Optimal Brain Connection. First, we introduce the Jacobian Criterion, a first-order metric for evaluating the saliency of structural parameters. Unlike existing first-order methods that assess parameters in isolation, our criterion explicitly captures both intra-component interactions and inter-layer dependencies. Second, we propose the Equivalent Pruning mechanism, which utilizes autoencoders to retain the contributions of all original connection--including pruned ones--during fine-tuning. Experimental results demonstrate that the Jacobian Criterion outperforms several popular metrics in preserving model performance, while the Equivalent Pruning mechanism effectively mitigates performance degradation after fine-tuning. Code: https://github.com/ShaowuChen/Optimal_Brain_Connection
ORXE: Orchestrating Experts for Dynamically Configurable Efficiency
May 07, 2025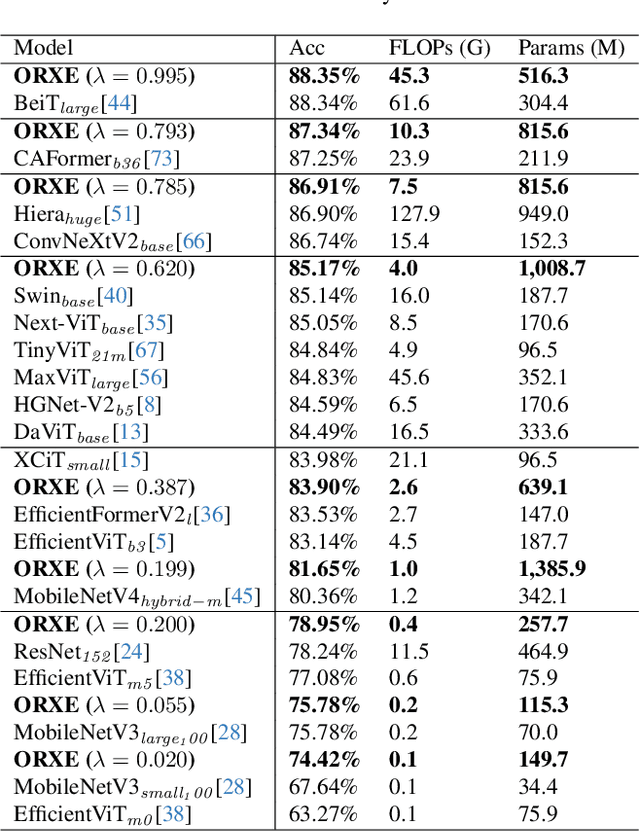
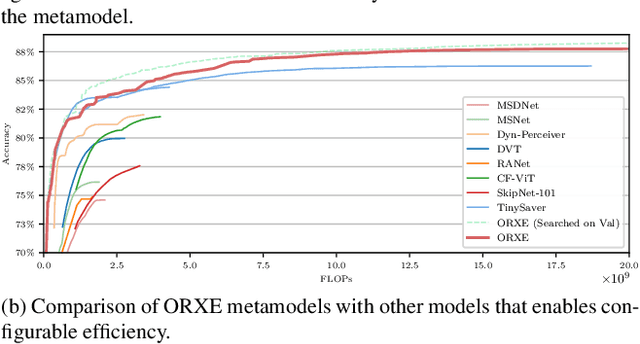
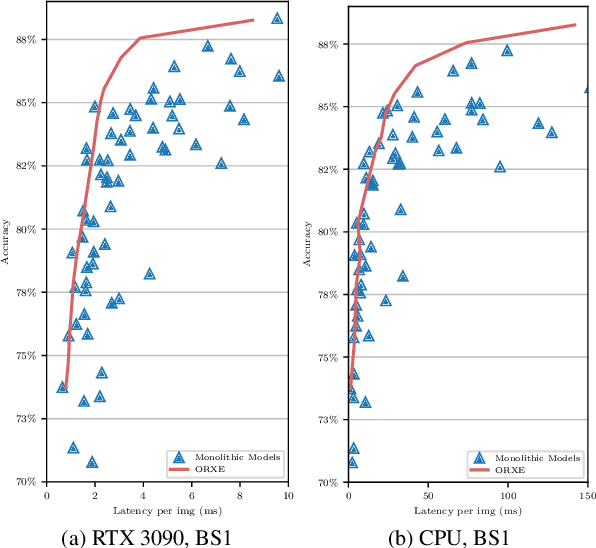
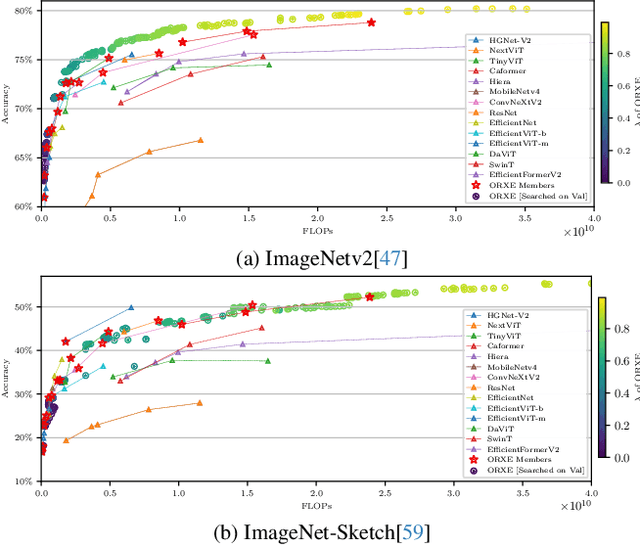
This paper presents ORXE, a modular and adaptable framework for achieving real-time configurable efficiency in AI models. By leveraging a collection of pre-trained experts with diverse computational costs and performance levels, ORXE dynamically adjusts inference pathways based on the complexity of input samples. Unlike conventional approaches that require complex metamodel training, ORXE achieves high efficiency and flexibility without complicating the development process. The proposed system utilizes a confidence-based gating mechanism to allocate appropriate computational resources for each input. ORXE also supports adjustments to the preference between inference cost and prediction performance across a wide range during runtime. We implemented a training-free ORXE system for image classification tasks, evaluating its efficiency and accuracy across various devices. The results demonstrate that ORXE achieves superior performance compared to individual experts and other dynamic models in most cases. This approach can be extended to other applications, providing a scalable solution for diverse real-world deployment scenarios.
A Review on Multisensor Data Fusion for Wearable Health Monitoring
Dec 08, 2024



The growing demand for accurate, continuous, and non-invasive health monitoring has propelled multi-sensor data fusion to the forefront of healthcare technology. This review aims to provide an overview of the development of fusion frameworks in the literature and common terminology used in fusion literature. The review introduces the fusion classification standards and methods that are most relevant from an algorithm development perspective. Applications of the reviewed fusion frameworks in fields such as defense, autonomous driving, robotics, and image fusion are also discussed to provide contextual information on the various fusion methodologies that have been developed in this field. This review provides a comprehensive analysis of multi-sensor data fusion methods applied to health monitoring systems, focusing on key algorithms, applications, challenges, and future directions. We examine commonly used fusion techniques, including Kalman filters, Bayesian networks, and machine learning models. By integrating data from various sources, these fusion approaches enhance the reliability, accuracy, and resilience of health monitoring systems. However, challenges such as data quality and differences in acquisition systems exist, calling for intelligent fusion algorithms in recent years. The review finally converges on applications of fusion algorithms in biomedical inference tasks like heartbeat detection, respiration rate estimation, sleep apnea detection, arrhythmia detection, and atrial fibrillation detection.
ECG Biometric Authentication Using Self-Supervised Learning for IoT Edge Sensors
Sep 09, 2024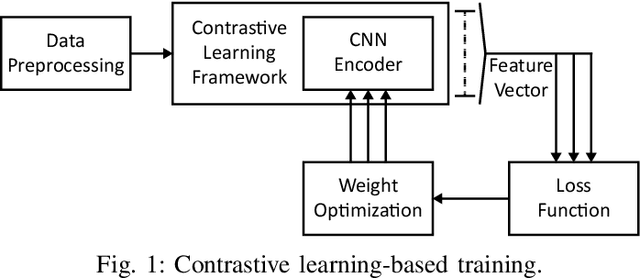
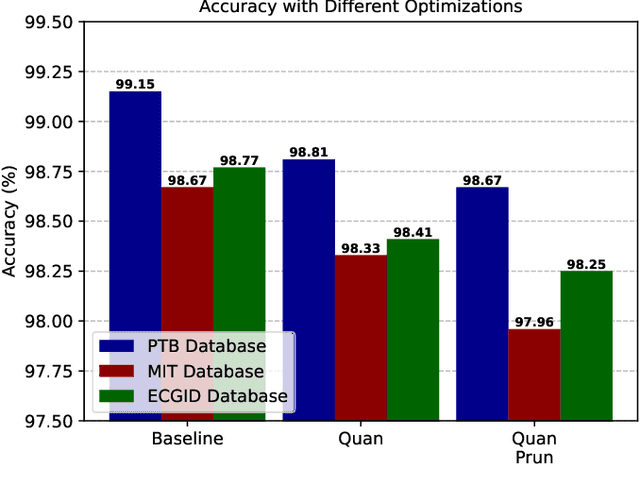
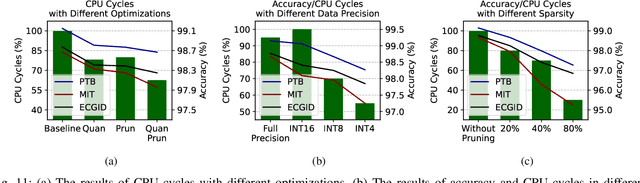
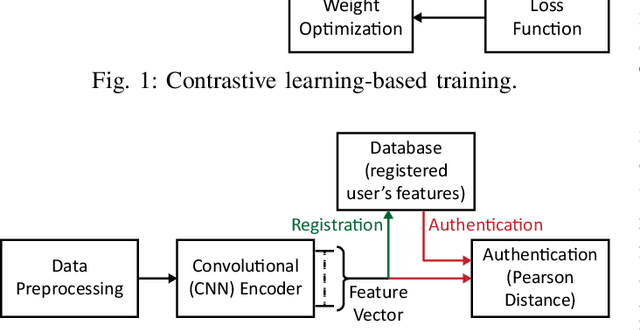
Wearable Internet of Things (IoT) devices are gaining ground for continuous physiological data acquisition and health monitoring. These physiological signals can be used for security applications to achieve continuous authentication and user convenience due to passive data acquisition. This paper investigates an electrocardiogram (ECG) based biometric user authentication system using features derived from the Convolutional Neural Network (CNN) and self-supervised contrastive learning. Contrastive learning enables us to use large unlabeled datasets to train the model and establish its generalizability. We propose approaches enabling the CNN encoder to extract appropriate features that distinguish the user from other subjects. When evaluated using the PTB ECG database with 290 subjects, the proposed technique achieved an authentication accuracy of 99.15%. To test its generalizability, we applied the model to two new datasets, the MIT-BIH Arrhythmia Database and the ECG-ID Database, achieving over 98.5% accuracy without any modifications. Furthermore, we show that repeating the authentication step three times can increase accuracy to nearly 100% for both PTBDB and ECGIDDB. This paper also presents model optimizations for embedded device deployment, which makes the system more relevant to real-world scenarios. To deploy our model in IoT edge sensors, we optimized the model complexity by applying quantization and pruning. The optimized model achieves 98.67% accuracy on PTBDB, with 0.48% accuracy loss and 62.6% CPU cycles compared to the unoptimized model. An accuracy-vs-time-complexity tradeoff analysis is performed, and results are presented for different optimization levels.
HiRED: Attention-Guided Token Dropping for Efficient Inference of High-Resolution Vision-Language Models in Resource-Constrained Environments
Aug 20, 2024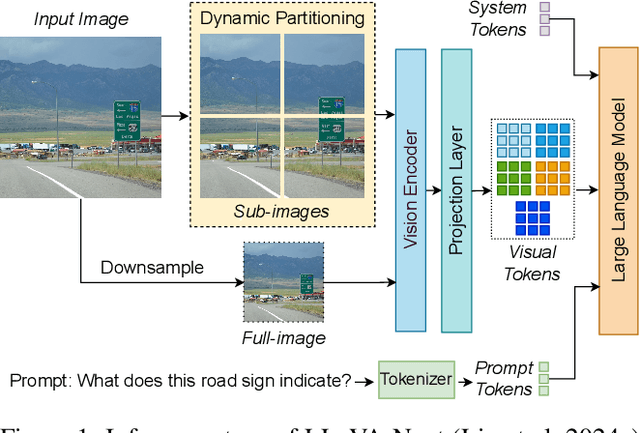

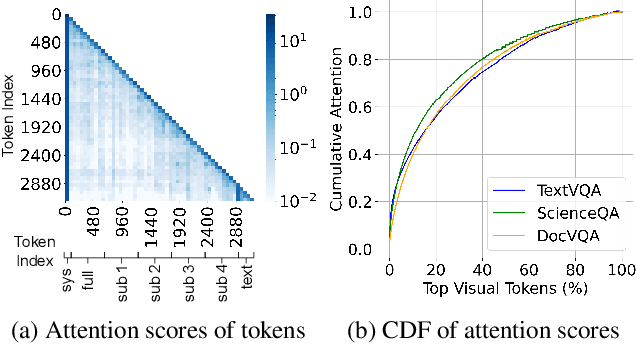

High-resolution Vision-Language Models (VLMs) have been widely used in multimodal tasks to enhance accuracy by preserving detailed image information. However, these models often generate excessive visual tokens due to encoding multiple partitions of the input image. Processing these excessive visual tokens is computationally challenging, especially in resource-constrained environments with commodity GPUs. To support high-resolution images while meeting resource constraints, we propose High-Resolution Early Dropping (HiRED), a token-dropping scheme that operates within a fixed token budget before the Large Language Model (LLM) stage. HiRED can be integrated with existing high-resolution VLMs in a plug-and-play manner, as it requires no additional training while still maintaining superior accuracy. We strategically use the vision encoder's attention in the initial layers to assess the visual content of each image partition and allocate the token budget accordingly. Then, using the attention in the final layer, we select the most important visual tokens from each partition within the allocated budget, dropping the rest. Empirically, when applied to LLaVA-Next-7B on NVIDIA TESLA P40 GPU, HiRED with a 20% token budget increases token generation throughput by 4.7, reduces first-token generation latency by 15 seconds, and saves 2.3 GB of GPU memory for a single inference.
KWT-Tiny: RISC-V Accelerated, Embedded Keyword Spotting Transformer
Jul 22, 2024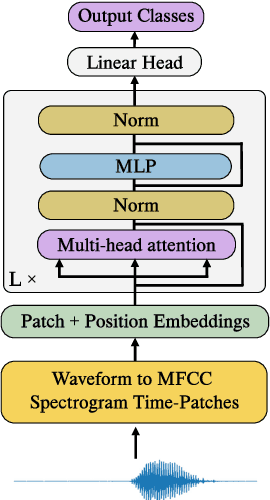
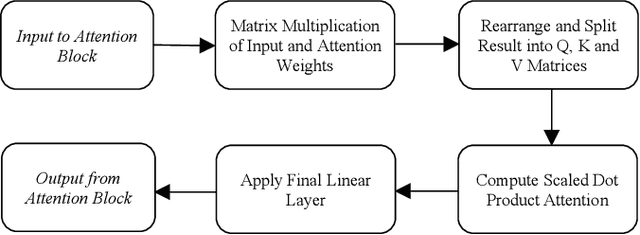
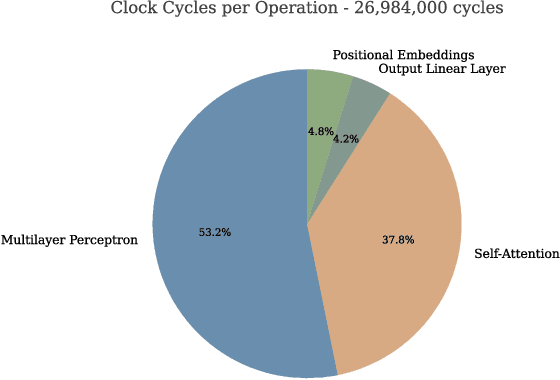
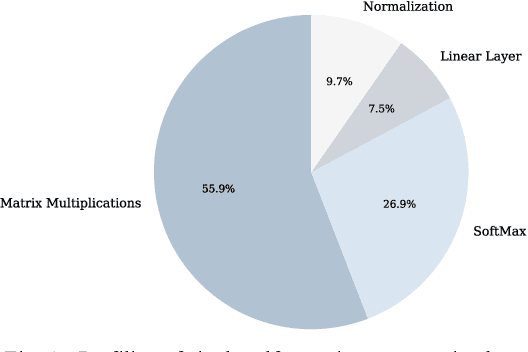
This paper explores the adaptation of Transformerbased models for edge devices through the quantisation and hardware acceleration of the ARM Keyword Transformer (KWT) model on a RISC-V platform. The model was targeted to run on 64kB RAM in bare-metal C using a custom-developed edge AI library. KWT-1 was retrained to be 369 times smaller, with only a 10% loss in accuracy through reducing output classes from 35 to 2. The retraining and quantisation reduced model size from 2.42 MB to 1.65 kB. The integration of custom RISC-V instructions that accelerated GELU and SoftMax operations enabled a 5x speedup and thus ~5x power reduction in inference, with inference clock cycle counts decreasing from 26 million to 5.5 million clock cycles while incurring a small area overhead of approximately 29%. The results demonstrate a viable method for porting and accelerating Transformer-based models in low-power IoT devices.
Tiny Models are the Computational Saver for Large Models
Mar 26, 2024This paper introduces TinySaver, an early-exit-like dynamic model compression approach which employs tiny models to substitute large models adaptively. Distinct from traditional compression techniques, dynamic methods like TinySaver can leverage the difficulty differences to allow certain inputs to complete their inference processes early, thereby conserving computational resources. Most existing early exit designs are implemented by attaching additional network branches to the model's backbone. Our study, however, reveals that completely independent tiny models can replace a substantial portion of the larger models' job with minimal impact on performance. Employing them as the first exit can remarkably enhance computational efficiency. By searching and employing the most appropriate tiny model as the computational saver for a given large model, the proposed approaches work as a novel and generic method to model compression. This finding will help the research community in exploring new compression methods to address the escalating computational demands posed by rapidly evolving AI models. Our evaluation of this approach in ImageNet-1k classification demonstrates its potential to reduce the number of compute operations by up to 90%, with only negligible losses in performance, across various modern vision models. The code of this work will be available.