 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWISP: Waste- and Interference-Suppressed Distributed Speculative LLM Serving at the Edge via Dynamic Drafting and SLO-Aware Batching
Jan 15, 2026As Large Language Models (LLMs) become increasingly accessible to end users, an ever-growing number of inference requests are initiated from edge devices and computed on centralized GPU clusters. However, the resulting exponential growth in computation workload is placing significant strain on data centers, while edge devices remain largely underutilized, leading to imbalanced workloads and resource inefficiency across the network. Integrating edge devices into the LLM inference process via speculative decoding helps balance the workload between the edge and the cloud, while maintaining lossless prediction accuracy. In this paper, we identify and formalize two critical bottlenecks that limit the efficiency and scalability of distributed speculative LLM serving: Wasted Drafting Time and Verification Interference. To address these challenges, we propose WISP, an efficient and SLO-aware distributed LLM inference system that consists of an intelligent speculation controller, a verification time estimator, and a verification batch scheduler. These components collaboratively enhance drafting efficiency and optimize verification request scheduling on the server. Extensive numerical results show that WISP improves system capacity by up to 2.1x and 4.1x, and increases system goodput by up to 1.94x and 3.7x, compared to centralized serving and SLED, respectively.
DiffPro: Joint Timestep and Layer-Wise Precision Optimization for Efficient Diffusion Inference
Nov 14, 2025Diffusion models produce high quality images but inference is costly due to many denoising steps and heavy matrix operations. We present DiffPro, a post-training, hardware-faithful framework that works with the exact integer kernels used in deployment and jointly tunes timesteps and per-layer precision in Diffusion Transformers (DiTs) to reduce latency and memory without any training. DiffPro combines three parts: a manifold-aware sensitivity metric to allocate weight bits, dynamic activation quantization to stabilize activations across timesteps, and a budgeted timestep selector guided by teacher-student drift. In experiments DiffPro achieves up to 6.25x model compression, fifty percent fewer timesteps, and 2.8x faster inference with Delta FID <= 10 on standard benchmarks, demonstrating practical efficiency gains. DiffPro unifies step reduction and precision planning into a single budgeted deployable plan for real-time energy-aware diffusion inference.
MARCO: A Multi-Agent System for Optimizing HPC Code Generation Using Large Language Models
May 06, 2025Large language models (LLMs) have transformed software development through code generation capabilities, yet their effectiveness for high-performance computing (HPC) remains limited. HPC code requires specialized optimizations for parallelism, memory efficiency, and architecture-specific considerations that general-purpose LLMs often overlook. We present MARCO (Multi-Agent Reactive Code Optimizer), a novel framework that enhances LLM-generated code for HPC through a specialized multi-agent architecture. MARCO employs separate agents for code generation and performance evaluation, connected by a feedback loop that progressively refines optimizations. A key innovation is MARCO's web-search component that retrieves real-time optimization techniques from recent conference proceedings and research publications, bridging the knowledge gap in pre-trained LLMs. Our extensive evaluation on the LeetCode 75 problem set demonstrates that MARCO achieves a 14.6% average runtime reduction compared to Claude 3.5 Sonnet alone, while the integration of the web-search component yields a 30.9% performance improvement over the base MARCO system. These results highlight the potential of multi-agent systems to address the specialized requirements of high-performance code generation, offering a cost-effective alternative to domain-specific model fine-tuning.
HiRED: Attention-Guided Token Dropping for Efficient Inference of High-Resolution Vision-Language Models in Resource-Constrained Environments
Aug 20, 2024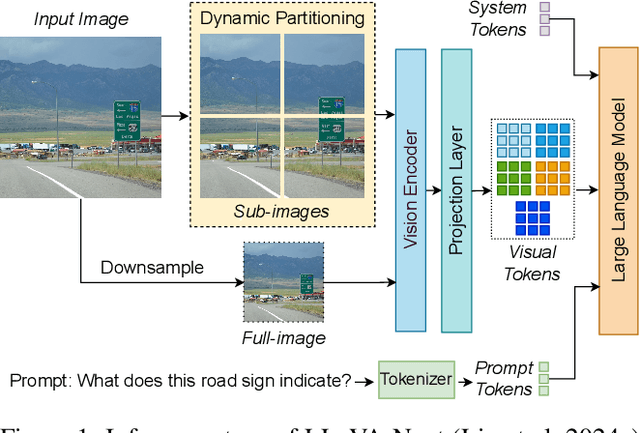

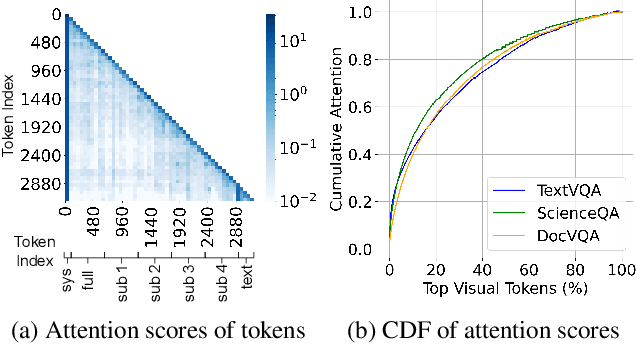

High-resolution Vision-Language Models (VLMs) have been widely used in multimodal tasks to enhance accuracy by preserving detailed image information. However, these models often generate excessive visual tokens due to encoding multiple partitions of the input image. Processing these excessive visual tokens is computationally challenging, especially in resource-constrained environments with commodity GPUs. To support high-resolution images while meeting resource constraints, we propose High-Resolution Early Dropping (HiRED), a token-dropping scheme that operates within a fixed token budget before the Large Language Model (LLM) stage. HiRED can be integrated with existing high-resolution VLMs in a plug-and-play manner, as it requires no additional training while still maintaining superior accuracy. We strategically use the vision encoder's attention in the initial layers to assess the visual content of each image partition and allocate the token budget accordingly. Then, using the attention in the final layer, we select the most important visual tokens from each partition within the allocated budget, dropping the rest. Empirically, when applied to LLaVA-Next-7B on NVIDIA TESLA P40 GPU, HiRED with a 20% token budget increases token generation throughput by 4.7, reduces first-token generation latency by 15 seconds, and saves 2.3 GB of GPU memory for a single inference.