 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFixing Imbalanced Attention to Mitigate In-Context Hallucination of Large Vision-Language Model
Jan 21, 2025Large Vision Language Models (LVLMs) have demonstrated remarkable capabilities in understanding and describing visual content, achieving state-of-the-art performance across various vision-language tasks. However, these models frequently exhibit hallucination behavior, where they generate descriptions containing objects or details absent in the input image. Our work investigates this phenomenon by analyzing attention patterns across transformer layers and heads, revealing that hallucinations often stem from progressive degradation of visual grounding in deeper layers. We propose a novel attention modification approach that combines selective token emphasis and head-specific modulation to maintain visual grounding throughout the generation process. Our method introduces two key components: (1) a dual-stream token selection mechanism that identifies and prioritizes both locally informative and spatially significant visual tokens, and (2) an attention head-specific modulation strategy that differentially amplifies visual information processing based on measured visual sensitivity of individual attention heads. Through extensive experimentation on the MSCOCO dataset, we demonstrate that our approach reduces hallucination rates by up to 62.3\% compared to baseline models while maintaining comparable task performance. Our analysis reveals that selectively modulating tokens across attention heads with varying levels of visual sensitivity can significantly improve visual grounding without requiring model retraining.
Equitable Skin Disease Prediction Using Transfer Learning and Domain Adaptation
Sep 01, 2024In the realm of dermatology, the complexity of diagnosing skin conditions manually necessitates the expertise of dermatologists. Accurate identification of various skin ailments, ranging from cancer to inflammatory diseases, is paramount. However, existing artificial intelligence (AI) models in dermatology face challenges, particularly in accurately diagnosing diseases across diverse skin tones, with a notable performance gap in darker skin. Additionally, the scarcity of publicly available, unbiased datasets hampers the development of inclusive AI diagnostic tools. To tackle the challenges in accurately predicting skin conditions across diverse skin tones, we employ a transfer-learning approach that capitalizes on the rich, transferable knowledge from various image domains. Our method integrates multiple pre-trained models from a wide range of sources, including general and specific medical images, to improve the robustness and inclusiveness of the skin condition predictions. We rigorously evaluated the effectiveness of these models using the Diverse Dermatology Images (DDI) dataset, which uniquely encompasses both underrepresented and common skin tones, making it an ideal benchmark for assessing our approach. Among all methods, Med-ViT emerged as the top performer due to its comprehensive feature representation learned from diverse image sources. To further enhance performance, we conducted domain adaptation using additional skin image datasets such as HAM10000. This adaptation significantly improved model performance across all models.
HiRED: Attention-Guided Token Dropping for Efficient Inference of High-Resolution Vision-Language Models in Resource-Constrained Environments
Aug 20, 2024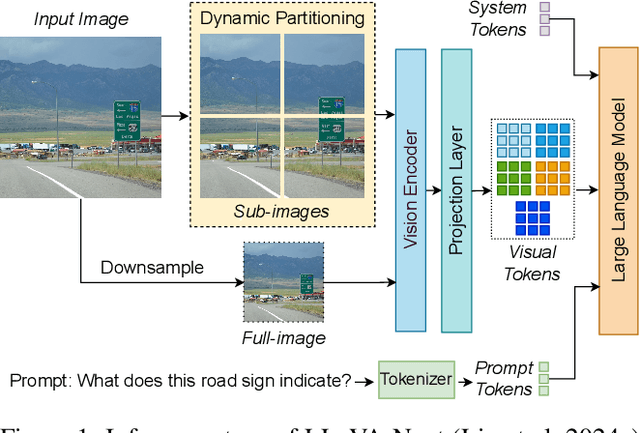

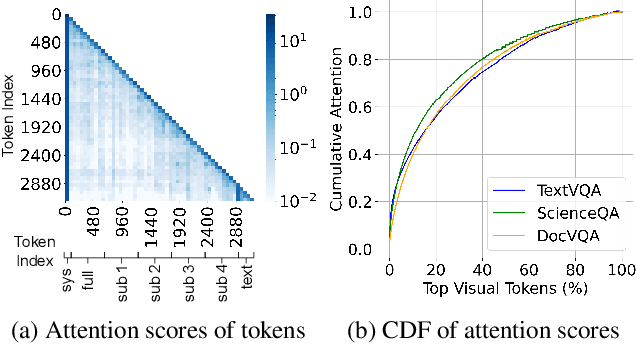

High-resolution Vision-Language Models (VLMs) have been widely used in multimodal tasks to enhance accuracy by preserving detailed image information. However, these models often generate excessive visual tokens due to encoding multiple partitions of the input image. Processing these excessive visual tokens is computationally challenging, especially in resource-constrained environments with commodity GPUs. To support high-resolution images while meeting resource constraints, we propose High-Resolution Early Dropping (HiRED), a token-dropping scheme that operates within a fixed token budget before the Large Language Model (LLM) stage. HiRED can be integrated with existing high-resolution VLMs in a plug-and-play manner, as it requires no additional training while still maintaining superior accuracy. We strategically use the vision encoder's attention in the initial layers to assess the visual content of each image partition and allocate the token budget accordingly. Then, using the attention in the final layer, we select the most important visual tokens from each partition within the allocated budget, dropping the rest. Empirically, when applied to LLaVA-Next-7B on NVIDIA TESLA P40 GPU, HiRED with a 20% token budget increases token generation throughput by 4.7, reduces first-token generation latency by 15 seconds, and saves 2.3 GB of GPU memory for a single inference.