 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFixing Imbalanced Attention to Mitigate In-Context Hallucination of Large Vision-Language Model
Jan 21, 2025Large Vision Language Models (LVLMs) have demonstrated remarkable capabilities in understanding and describing visual content, achieving state-of-the-art performance across various vision-language tasks. However, these models frequently exhibit hallucination behavior, where they generate descriptions containing objects or details absent in the input image. Our work investigates this phenomenon by analyzing attention patterns across transformer layers and heads, revealing that hallucinations often stem from progressive degradation of visual grounding in deeper layers. We propose a novel attention modification approach that combines selective token emphasis and head-specific modulation to maintain visual grounding throughout the generation process. Our method introduces two key components: (1) a dual-stream token selection mechanism that identifies and prioritizes both locally informative and spatially significant visual tokens, and (2) an attention head-specific modulation strategy that differentially amplifies visual information processing based on measured visual sensitivity of individual attention heads. Through extensive experimentation on the MSCOCO dataset, we demonstrate that our approach reduces hallucination rates by up to 62.3\% compared to baseline models while maintaining comparable task performance. Our analysis reveals that selectively modulating tokens across attention heads with varying levels of visual sensitivity can significantly improve visual grounding without requiring model retraining.
Diff-DTI: Fast Diffusion Tensor Imaging Using A Feature-Enhanced Joint Diffusion Model
May 24, 2024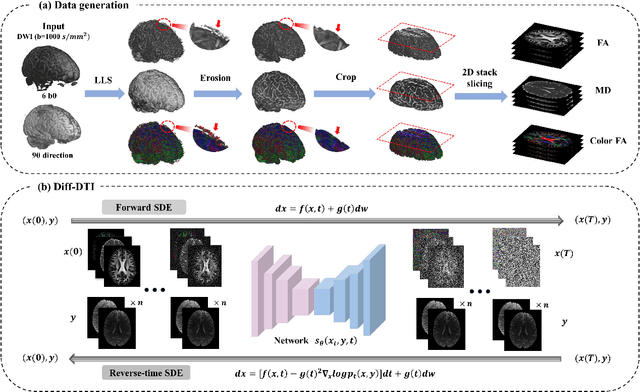
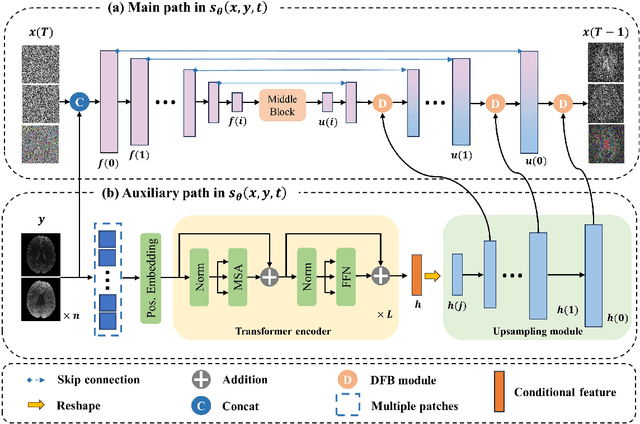
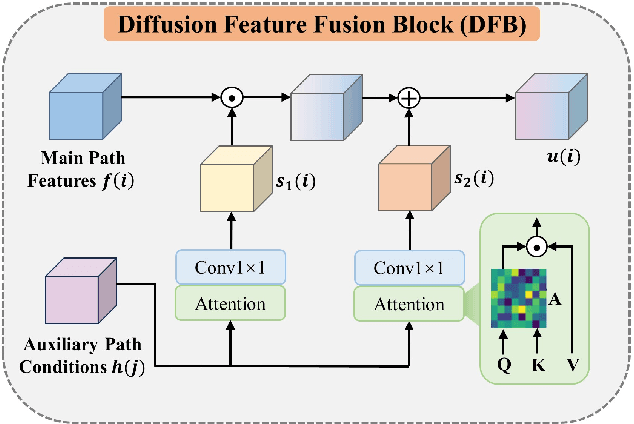
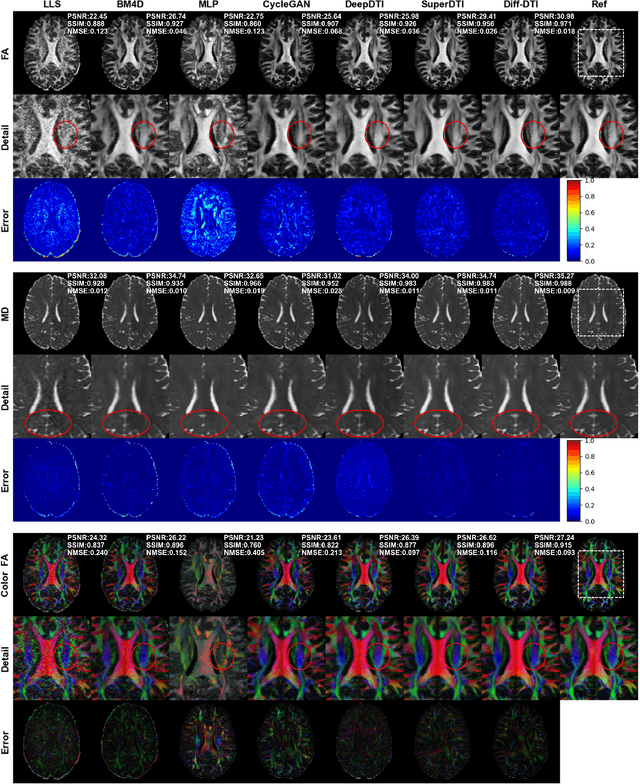
Magnetic resonance diffusion tensor imaging (DTI) is a critical tool for neural disease diagnosis. However, long scan time greatly hinders the widespread clinical use of DTI. To accelerate image acquisition, a feature-enhanced joint diffusion model (Diff-DTI) is proposed to obtain accurate DTI parameter maps from a limited number of diffusion-weighted images (DWIs). Diff-DTI introduces a joint diffusion model that directly learns the joint probability distribution of DWIs with DTI parametric maps for conditional generation. Additionally, a feature enhancement fusion mechanism (FEFM) is designed and incorporated into the generative process of Diff-DTI to preserve fine structures in the generated DTI maps. A comprehensive evaluation of the performance of Diff-DTI was conducted on the Human Connectome Project dataset. The results demonstrate that Diff-DTI outperforms existing state-of-the-art fast DTI imaging methods in terms of visual quality and quantitative metrics. Furthermore, Diff-DTI has shown the ability to produce high-fidelity DTI maps with only three DWIs, thus overcoming the requirement of a minimum of six DWIs for DTI.