 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM4Cell: A Survey of Large Language and Agentic Models for Single-Cell Biology
Oct 09, 2025Large language models (LLMs) and emerging agentic frameworks are beginning to transform single-cell biology by enabling natural-language reasoning, generative annotation, and multimodal data integration. However, progress remains fragmented across data modalities, architectures, and evaluation standards. LLM4Cell presents the first unified survey of 58 foundation and agentic models developed for single-cell research, spanning RNA, ATAC, multi-omic, and spatial modalities. We categorize these methods into five families-foundation, text-bridge, spatial, multimodal, epigenomic, and agentic-and map them to eight key analytical tasks including annotation, trajectory and perturbation modeling, and drug-response prediction. Drawing on over 40 public datasets, we analyze benchmark suitability, data diversity, and ethical or scalability constraints, and evaluate models across 10 domain dimensions covering biological grounding, multi-omics alignment, fairness, privacy, and explainability. By linking datasets, models, and evaluation domains, LLM4Cell provides the first integrated view of language-driven single-cell intelligence and outlines open challenges in interpretability, standardization, and trustworthy model development.
MoXGATE: Modality-aware cross-attention for multi-omic gastrointestinal cancer sub-type classification
Jun 08, 2025Cancer subtype classification is crucial for personalized treatment and prognostic assessment. However, effectively integrating multi-omic data remains challenging due to the heterogeneous nature of genomic, epigenomic, and transcriptomic features. In this work, we propose Modality-Aware Cross-Attention MoXGATE, a novel deep-learning framework that leverages cross-attention and learnable modality weights to enhance feature fusion across multiple omics sources. Our approach effectively captures inter-modality dependencies, ensuring robust and interpretable integration. Through experiments on Gastrointestinal Adenocarcinoma (GIAC) and Breast Cancer (BRCA) datasets from TCGA, we demonstrate that MoXGATE outperforms existing methods, achieving 95\% classification accuracy. Ablation studies validate the effectiveness of cross-attention over simple concatenation and highlight the importance of different omics modalities. Moreover, our model generalizes well to unseen cancer types e.g., breast cancer, underscoring its adaptability. Key contributions include (1) a cross-attention-based multi-omic integration framework, (2) modality-weighted fusion for enhanced interpretability, (3) application of focal loss to mitigate data imbalance, and (4) validation across multiple cancer subtypes. Our results indicate that MoXGATE is a promising approach for multi-omic cancer subtype classification, offering improved performance and biological generalizability.
Fixing Imbalanced Attention to Mitigate In-Context Hallucination of Large Vision-Language Model
Jan 21, 2025Large Vision Language Models (LVLMs) have demonstrated remarkable capabilities in understanding and describing visual content, achieving state-of-the-art performance across various vision-language tasks. However, these models frequently exhibit hallucination behavior, where they generate descriptions containing objects or details absent in the input image. Our work investigates this phenomenon by analyzing attention patterns across transformer layers and heads, revealing that hallucinations often stem from progressive degradation of visual grounding in deeper layers. We propose a novel attention modification approach that combines selective token emphasis and head-specific modulation to maintain visual grounding throughout the generation process. Our method introduces two key components: (1) a dual-stream token selection mechanism that identifies and prioritizes both locally informative and spatially significant visual tokens, and (2) an attention head-specific modulation strategy that differentially amplifies visual information processing based on measured visual sensitivity of individual attention heads. Through extensive experimentation on the MSCOCO dataset, we demonstrate that our approach reduces hallucination rates by up to 62.3\% compared to baseline models while maintaining comparable task performance. Our analysis reveals that selectively modulating tokens across attention heads with varying levels of visual sensitivity can significantly improve visual grounding without requiring model retraining.
Equitable Skin Disease Prediction Using Transfer Learning and Domain Adaptation
Sep 01, 2024In the realm of dermatology, the complexity of diagnosing skin conditions manually necessitates the expertise of dermatologists. Accurate identification of various skin ailments, ranging from cancer to inflammatory diseases, is paramount. However, existing artificial intelligence (AI) models in dermatology face challenges, particularly in accurately diagnosing diseases across diverse skin tones, with a notable performance gap in darker skin. Additionally, the scarcity of publicly available, unbiased datasets hampers the development of inclusive AI diagnostic tools. To tackle the challenges in accurately predicting skin conditions across diverse skin tones, we employ a transfer-learning approach that capitalizes on the rich, transferable knowledge from various image domains. Our method integrates multiple pre-trained models from a wide range of sources, including general and specific medical images, to improve the robustness and inclusiveness of the skin condition predictions. We rigorously evaluated the effectiveness of these models using the Diverse Dermatology Images (DDI) dataset, which uniquely encompasses both underrepresented and common skin tones, making it an ideal benchmark for assessing our approach. Among all methods, Med-ViT emerged as the top performer due to its comprehensive feature representation learned from diverse image sources. To further enhance performance, we conducted domain adaptation using additional skin image datasets such as HAM10000. This adaptation significantly improved model performance across all models.
PathoLM: Identifying pathogenicity from the DNA sequence through the Genome Foundation Model
Jun 19, 2024Pathogen identification is pivotal in diagnosing, treating, and preventing diseases, crucial for controlling infections and safeguarding public health. Traditional alignment-based methods, though widely used, are computationally intense and reliant on extensive reference databases, often failing to detect novel pathogens due to their low sensitivity and specificity. Similarly, conventional machine learning techniques, while promising, require large annotated datasets and extensive feature engineering and are prone to overfitting. Addressing these challenges, we introduce PathoLM, a cutting-edge pathogen language model optimized for the identification of pathogenicity in bacterial and viral sequences. Leveraging the strengths of pre-trained DNA models such as the Nucleotide Transformer, PathoLM requires minimal data for fine-tuning, thereby enhancing pathogen detection capabilities. It effectively captures a broader genomic context, significantly improving the identification of novel and divergent pathogens. We developed a comprehensive data set comprising approximately 30 species of viruses and bacteria, including ESKAPEE pathogens, seven notably virulent bacterial strains resistant to antibiotics. Additionally, we curated a species classification dataset centered specifically on the ESKAPEE group. In comparative assessments, PathoLM dramatically outperforms existing models like DciPatho, demonstrating robust zero-shot and few-shot capabilities. Furthermore, we expanded PathoLM-Sp for ESKAPEE species classification, where it showed superior performance compared to other advanced deep learning methods, despite the complexities of the task.
AI for Biomedicine in the Era of Large Language Models
Mar 23, 2024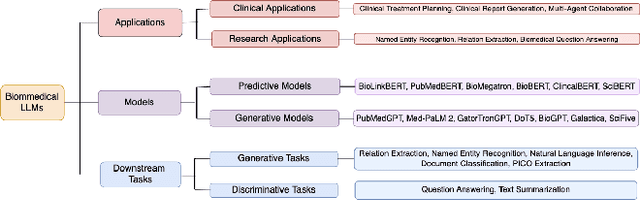
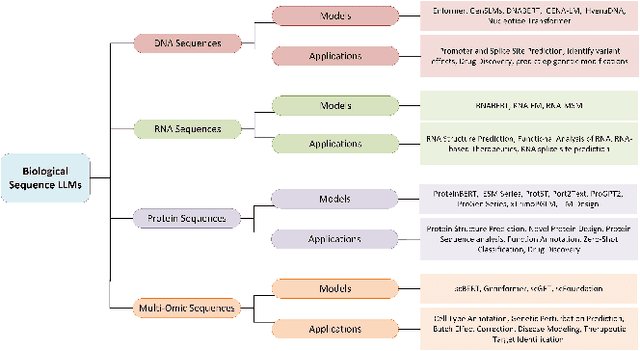
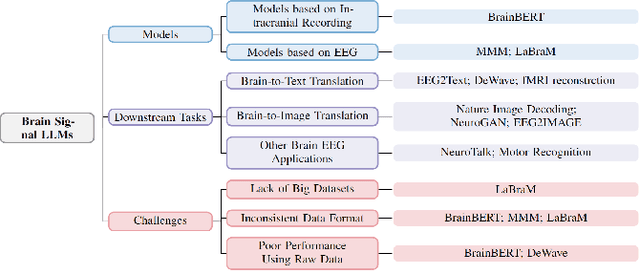
The capabilities of AI for biomedicine span a wide spectrum, from the atomic level, where it solves partial differential equations for quantum systems, to the molecular level, predicting chemical or protein structures, and further extending to societal predictions like infectious disease outbreaks. Recent advancements in large language models, exemplified by models like ChatGPT, have showcased significant prowess in natural language tasks, such as translating languages, constructing chatbots, and answering questions. When we consider biomedical data, we observe a resemblance to natural language in terms of sequences: biomedical literature and health records presented as text, biological sequences or sequencing data arranged in sequences, or sensor data like brain signals as time series. The question arises: Can we harness the potential of recent large language models to drive biomedical knowledge discoveries? In this survey, we will explore the application of large language models to three crucial categories of biomedical data: 1) textual data, 2) biological sequences, and 3) brain signals. Furthermore, we will delve into large language model challenges in biomedical research, including ensuring trustworthiness, achieving personalization, and adapting to multi-modal data representation