 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTOC-TOT: Stochastic Tree-of-Thought with Constrained Decoding for Complex Reasoning in Multi-Hop Question Answering
Jul 04, 2024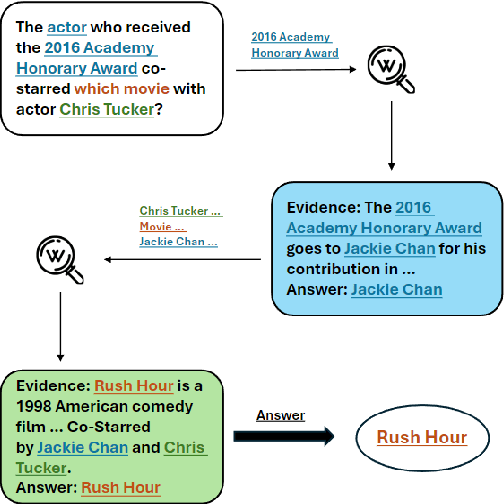
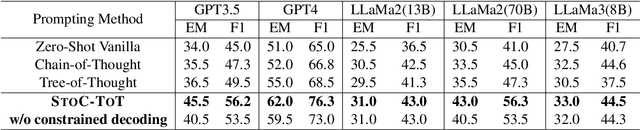
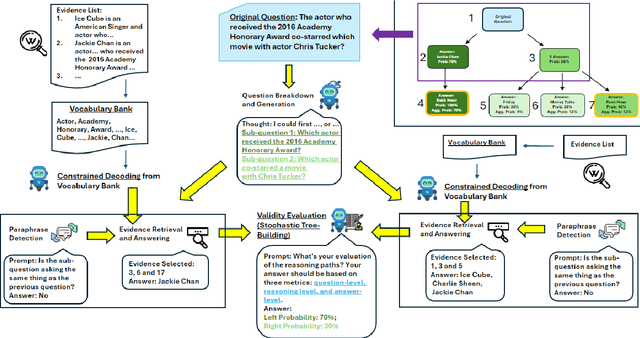
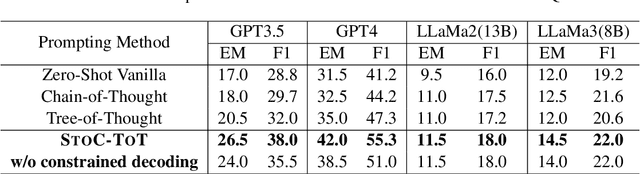
Multi-hop question answering (MHQA) requires a model to retrieve and integrate information from multiple passages to answer a complex question. Recent systems leverage the power of large language models and integrate evidence retrieval with reasoning prompts (e.g., chain-of-thought reasoning) for the MHQA task. However, the complexities in the question types (bridge v.s. comparison questions) and the reasoning types (sequential v.s. parallel reasonings) require more novel and fine-grained prompting methods to enhance the performance of MHQA under the zero-shot setting. In this paper, we propose STOC-TOT, a stochastic tree-of-thought reasoning prompting method with constrained decoding for MHQA and conduct a detailed comparison with other reasoning prompts on different question types and reasoning types. Specifically, we construct a tree-like reasoning structure by prompting the model to break down the original question into smaller sub-questions to form different reasoning paths. In addition, we prompt the model to provide a probability estimation for each reasoning path at each reasoning step. At answer time, we conduct constrained decoding on the model to generate more grounded answers and reduce hallucination. Experiments comparing STOC-TOT with two MHQA datasets and five large language models showed that our framework outperforms other reasoning prompts by a significant margin.
EEG2TEXT: Open Vocabulary EEG-to-Text Decoding with EEG Pre-Training and Multi-View Transformer
May 03, 2024



Deciphering the intricacies of the human brain has captivated curiosity for centuries. Recent strides in Brain-Computer Interface (BCI) technology, particularly using motor imagery, have restored motor functions such as reaching, grasping, and walking in paralyzed individuals. However, unraveling natural language from brain signals remains a formidable challenge. Electroencephalography (EEG) is a non-invasive technique used to record electrical activity in the brain by placing electrodes on the scalp. Previous studies of EEG-to-text decoding have achieved high accuracy on small closed vocabularies, but still fall short of high accuracy when dealing with large open vocabularies. We propose a novel method, EEG2TEXT, to improve the accuracy of open vocabulary EEG-to-text decoding. Specifically, EEG2TEXT leverages EEG pre-training to enhance the learning of semantics from EEG signals and proposes a multi-view transformer to model the EEG signal processing by different spatial regions of the brain. Experiments show that EEG2TEXT has superior performance, outperforming the state-of-the-art baseline methods by a large margin of up to 5% in absolute BLEU and ROUGE scores. EEG2TEXT shows great potential for a high-performance open-vocabulary brain-to-text system to facilitate communication.
AI for Biomedicine in the Era of Large Language Models
Mar 23, 2024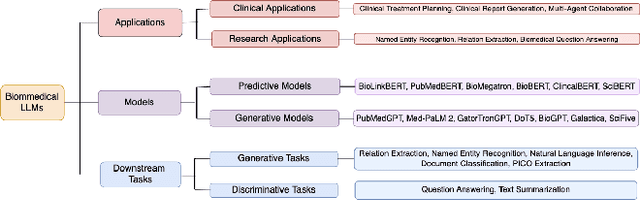
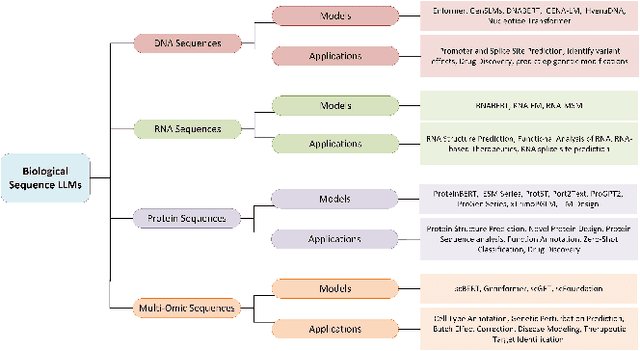
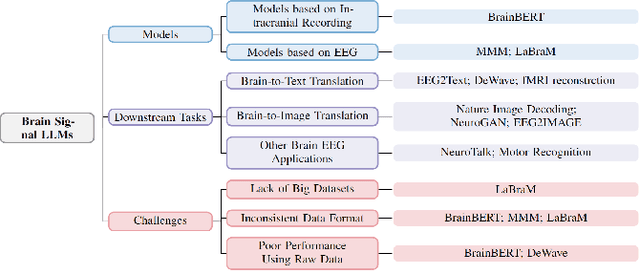
The capabilities of AI for biomedicine span a wide spectrum, from the atomic level, where it solves partial differential equations for quantum systems, to the molecular level, predicting chemical or protein structures, and further extending to societal predictions like infectious disease outbreaks. Recent advancements in large language models, exemplified by models like ChatGPT, have showcased significant prowess in natural language tasks, such as translating languages, constructing chatbots, and answering questions. When we consider biomedical data, we observe a resemblance to natural language in terms of sequences: biomedical literature and health records presented as text, biological sequences or sequencing data arranged in sequences, or sensor data like brain signals as time series. The question arises: Can we harness the potential of recent large language models to drive biomedical knowledge discoveries? In this survey, we will explore the application of large language models to three crucial categories of biomedical data: 1) textual data, 2) biological sequences, and 3) brain signals. Furthermore, we will delve into large language model challenges in biomedical research, including ensuring trustworthiness, achieving personalization, and adapting to multi-modal data representation
XAI-CLASS: Explanation-Enhanced Text Classification with Extremely Weak Supervision
Oct 31, 2023Text classification aims to effectively categorize documents into pre-defined categories. Traditional methods for text classification often rely on large amounts of manually annotated training data, making the process time-consuming and labor-intensive. To address this issue, recent studies have focused on weakly-supervised and extremely weakly-supervised settings, which require minimal or no human annotation, respectively. In previous methods of weakly supervised text classification, pseudo-training data is generated by assigning pseudo-labels to documents based on their alignment (e.g., keyword matching) with specific classes. However, these methods ignore the importance of incorporating the explanations of the generated pseudo-labels, or saliency of individual words, as additional guidance during the text classification training process. To address this limitation, we propose XAI-CLASS, a novel explanation-enhanced extremely weakly-supervised text classification method that incorporates word saliency prediction as an auxiliary task. XAI-CLASS begins by employing a multi-round question-answering process to generate pseudo-training data that promotes the mutual enhancement of class labels and corresponding explanation word generation. This pseudo-training data is then used to train a multi-task framework that simultaneously learns both text classification and word saliency prediction. Extensive experiments on several weakly-supervised text classification datasets show that XAI-CLASS outperforms other weakly-supervised text classification methods significantly. Moreover, experiments demonstrate that XAI-CLASS enhances both model performance and explainability.