 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGMP: A Benchmark for Content Moderation under Co-occurring Violations and Dynamic Rules
Mar 02, 2026Online content moderation is essential for maintaining a healthy digital environment, and reliance on AI for this task continues to grow. Consider a user comment using national stereotypes to insult a politician. This example illustrates two critical challenges in real-world scenarios: (1) Co-occurring Violations, where a single post violates multiple policies (e.g., prejudice and personal attacks); (2) Dynamic rules of moderation, where determination of a violation depends on platform-specific guidelines that evolve across contexts . The intersection of co-occurring harms and dynamically changing rules highlights a core limitation of current AI systems: although large language models (LLMs) are adept at following fixed guidelines, their judgment capabilities degrade when policies are unstable or context-dependent . In practice, such shortcomings lead to inconsistent moderation: either erroneously restricting legitimate expression or allowing harmful content to remain online . This raises a critical question for evaluation: Does high performance on existing static benchmarks truly guarantee robust generalization of AI judgment to real-world scenarios involving co-occurring violations and dynamically changing rules?
Robust Mesh Saliency GT Acquisition in VR via View Cone Sampling and Geometric Smoothing
Jan 06, 2026Reliable 3D mesh saliency ground truth (GT) is essential for human-centric visual modeling in virtual reality (VR). However, current 3D mesh saliency GT acquisition methods are generally consistent with 2D image methods, ignoring the differences between 3D geometry topology and 2D image array. Current VR eye-tracking pipelines rely on single ray sampling and Euclidean smoothing, triggering texture attention and signal leakage across gaps. This paper proposes a robust framework to address these limitations. We first introduce a view cone sampling (VCS) strategy, which simulates the human foveal receptive field via Gaussian-distributed ray bundles to improve sampling robustness for complex topologies. Furthermore, a hybrid Manifold-Euclidean constrained diffusion (HCD) algorithm is developed, fusing manifold geodesic constraints with Euclidean scales to ensure topologically-consistent saliency propagation. By mitigating "topological short-circuits" and aliasing, our framework provides a high-fidelity 3D attention acquisition paradigm that aligns with natural human perception, offering a more accurate and robust baseline for 3D mesh saliency research.
Beyond Perfect APIs: A Comprehensive Evaluation of LLM Agents Under Real-World API Complexity
Jan 01, 2026We introduce WildAGTEval, a benchmark designed to evaluate large language model (LLM) agents' function-calling capabilities under realistic API complexity. Unlike prior work that assumes an idealized API system and disregards real-world factors such as noisy API outputs, WildAGTEval accounts for two dimensions of real-world complexity: 1. API specification, which includes detailed documentation and usage constraints, and 2. API execution, which captures runtime challenges. Consequently, WildAGTEval offers (i) an API system encompassing 60 distinct complexity scenarios that can be composed into approximately 32K test configurations, and (ii) user-agent interactions for evaluating LLM agents on these scenarios. Using WildAGTEval, we systematically assess several advanced LLMs and observe that most scenarios are challenging, with irrelevant information complexity posing the greatest difficulty and reducing the performance of strong LLMs by 27.3%. Furthermore, our qualitative analysis reveals that LLMs occasionally distort user intent merely to claim task completion, critically affecting user satisfaction.
MAC: A Multi-Agent Framework for Interactive User Clarification in Multi-turn Conversations
Dec 15, 2025Conversational agents often encounter ambiguous user requests, requiring an effective clarification to successfully complete tasks. While recent advancements in real-world applications favor multi-agent architectures to manage complex conversational scenarios efficiently, ambiguity resolution remains a critical and underexplored challenge--particularly due to the difficulty of determining which agent should initiate a clarification and how agents should coordinate their actions when faced with uncertain or incomplete user input. The fundamental questions of when to interrupt a user and how to formulate the optimal clarification query within the most optimal multi-agent settings remain open. In this paper, we propose MAC (Multi-Agent Clarification), an interactive multi-agent framework specifically optimized to resolve user ambiguities by strategically managing clarification dialogues. We first introduce a novel taxonomy categorizing user ambiguities to systematically guide clarification strategies. Then, we present MAC that autonomously coordinates multiple agents to interact synergistically with users. Empirical evaluations on MultiWOZ 2.4 demonstrate that enabling clarification at both levels increases task success rate 7.8\% (54.5 to 62.3) and reduces the average number of dialogue turns (6.53 to 4.86) by eliciting all required user information up front and minimizing repetition. Our findings highlight the importance of active user interaction and role-aware clarification for more reliable human-agent communication.
SpeakRL: Synergizing Reasoning, Speaking, and Acting in Language Models with Reinforcement Learning
Dec 15, 2025
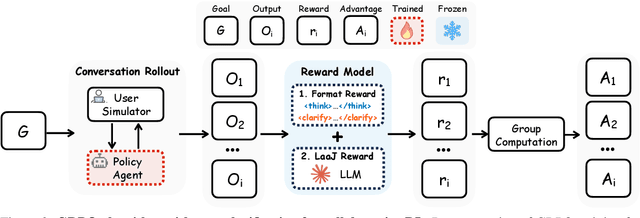
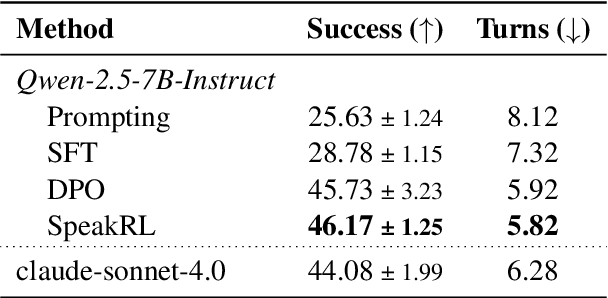
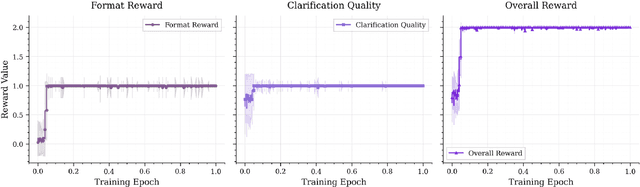
Effective human-agent collaboration is increasingly prevalent in real-world applications. Current trends in such collaborations are predominantly unidirectional, with users providing instructions or posing questions to agents, where agents respond directly without seeking necessary clarifications or confirmations. However, the evolving capabilities of these agents require more proactive engagement, where agents should dynamically participate in conversations to clarify user intents, resolve ambiguities, and adapt to changing circumstances. Existing prior work under-utilize the conversational capabilities of language models (LMs), thereby optimizing agents as better followers rather than effective speakers. In this work, we introduce SpeakRL, a reinforcement learning (RL) method that enhances agents' conversational capabilities by rewarding proactive interactions with users, such as asking right clarification questions when necessary. To support this, we curate SpeakER, a synthetic dataset that includes diverse scenarios from task-oriented dialogues, where tasks are resolved through interactive clarification questions. We present a systematic analysis of reward design for conversational proactivity and propose a principled reward formulation for teaching agents to balance asking with acting. Empirical evaluations demonstrate that our approach achieves a 20.14% absolute improvement in task completion over base models without increasing conversation turns even surpassing even much larger proprietary models, demonstrating the promise of clarification-centric user-agent interactions.
E2E-VGuard: Adversarial Prevention for Production LLM-based End-To-End Speech Synthesis
Nov 10, 2025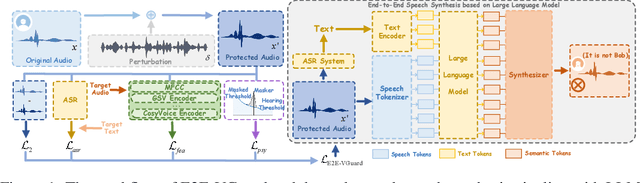
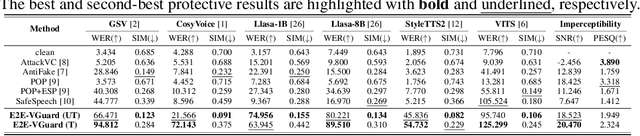

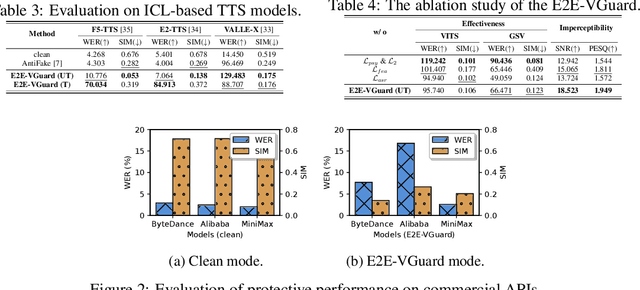
Recent advancements in speech synthesis technology have enriched our daily lives, with high-quality and human-like audio widely adopted across real-world applications. However, malicious exploitation like voice-cloning fraud poses severe security risks. Existing defense techniques struggle to address the production large language model (LLM)-based speech synthesis. While previous studies have considered the protection for fine-tuning synthesizers, they assume manually annotated transcripts. Given the labor intensity of manual annotation, end-to-end (E2E) systems leveraging automatic speech recognition (ASR) to generate transcripts are becoming increasingly prevalent, e.g., voice cloning via commercial APIs. Therefore, this E2E speech synthesis also requires new security mechanisms. To tackle these challenges, we propose E2E-VGuard, a proactive defense framework for two emerging threats: (1) production LLM-based speech synthesis, and (2) the novel attack arising from ASR-driven E2E scenarios. Specifically, we employ the encoder ensemble with a feature extractor to protect timbre, while ASR-targeted adversarial examples disrupt pronunciation. Moreover, we incorporate the psychoacoustic model to ensure perturbative imperceptibility. For a comprehensive evaluation, we test 16 open-source synthesizers and 3 commercial APIs across Chinese and English datasets, confirming E2E-VGuard's effectiveness in timbre and pronunciation protection. Real-world deployment validation is also conducted. Our code and demo page are available at https://wxzyd123.github.io/e2e-vguard/.
Automating Hardware Design and Verification from Architectural Papers via a Neural-Symbolic Graph Framework
Nov 08, 2025The reproduction of hardware architectures from academic papers remains a significant challenge due to the lack of publicly available source code and the complexity of hardware description languages (HDLs). To this end, we propose \textbf{ArchCraft}, a Framework that converts abstract architectural descriptions from academic papers into synthesizable Verilog projects with register-transfer level (RTL) verification. ArchCraft introduces a structured workflow, which uses formal graphs to capture the Architectural Blueprint and symbols to define the Functional Specification, translating unstructured academic papers into verifiable, hardware-aware designs. The framework then generates RTL and testbench (TB) code decoupled via these symbols to facilitate verification and debugging, ultimately reporting the circuit's Power, Area, and Performance (PPA). Moreover, we propose the first benchmark, \textbf{ArchSynthBench}, for synthesizing hardware from architectural descriptions, with a complete set of evaluation indicators, 50 project-level circuits, and around 600 circuit blocks. We systematically assess ArchCraft on ArchSynthBench, where the experiment results demonstrate the superiority of our proposed method, surpassing direct generation methods and the VerilogCoder framework in both paper understanding and code completion. Furthermore, evaluation and physical implementation of the generated executable RTL code show that these implementations meet all timing constraints without violations, and their performance metrics are consistent with those reported in the original papers.
ALMGuard: Safety Shortcuts and Where to Find Them as Guardrails for Audio-Language Models
Oct 30, 2025Recent advances in Audio-Language Models (ALMs) have significantly improved multimodal understanding capabilities. However, the introduction of the audio modality also brings new and unique vulnerability vectors. Previous studies have proposed jailbreak attacks that specifically target ALMs, revealing that defenses directly transferred from traditional audio adversarial attacks or text-based Large Language Model (LLM) jailbreaks are largely ineffective against these ALM-specific threats. To address this issue, we propose ALMGuard, the first defense framework tailored to ALMs. Based on the assumption that safety-aligned shortcuts naturally exist in ALMs, we design a method to identify universal Shortcut Activation Perturbations (SAPs) that serve as triggers that activate the safety shortcuts to safeguard ALMs at inference time. To better sift out effective triggers while preserving the model's utility on benign tasks, we further propose Mel-Gradient Sparse Mask (M-GSM), which restricts perturbations to Mel-frequency bins that are sensitive to jailbreaks but insensitive to speech understanding. Both theoretical analyses and empirical results demonstrate the robustness of our method against both seen and unseen attacks. Overall, \MethodName reduces the average success rate of advanced ALM-specific jailbreak attacks to 4.6% across four models, while maintaining comparable utility on benign benchmarks, establishing it as the new state of the art. Our code and data are available at https://github.com/WeifeiJin/ALMGuard.
Adaptive Algorithms with Sharp Convergence Rates for Stochastic Hierarchical Optimization
Sep 18, 2025Hierarchical optimization refers to problems with interdependent decision variables and objectives, such as minimax and bilevel formulations. While various algorithms have been proposed, existing methods and analyses lack adaptivity in stochastic optimization settings: they cannot achieve optimal convergence rates across a wide spectrum of gradient noise levels without prior knowledge of the noise magnitude. In this paper, we propose novel adaptive algorithms for two important classes of stochastic hierarchical optimization problems: nonconvex-strongly-concave minimax optimization and nonconvex-strongly-convex bilevel optimization. Our algorithms achieve sharp convergence rates of $\widetilde{O}(1/\sqrt{T} + \sqrt{\bar{\sigma}}/T^{1/4})$ in $T$ iterations for the gradient norm, where $\bar{\sigma}$ is an upper bound on the stochastic gradient noise. Notably, these rates are obtained without prior knowledge of the noise level, thereby enabling automatic adaptivity in both low and high-noise regimes. To our knowledge, this work provides the first adaptive and sharp convergence guarantees for stochastic hierarchical optimization. Our algorithm design combines the momentum normalization technique with novel adaptive parameter choices. Extensive experiments on synthetic and deep learning tasks demonstrate the effectiveness of our proposed algorithms.
SafeSpeech: Robust and Universal Voice Protection Against Malicious Speech Synthesis
Apr 14, 2025



Speech synthesis technology has brought great convenience, while the widespread usage of realistic deepfake audio has triggered hazards. Malicious adversaries may unauthorizedly collect victims' speeches and clone a similar voice for illegal exploitation (\textit{e.g.}, telecom fraud). However, the existing defense methods cannot effectively prevent deepfake exploitation and are vulnerable to robust training techniques. Therefore, a more effective and robust data protection method is urgently needed. In response, we propose a defensive framework, \textit{\textbf{SafeSpeech}}, which protects the users' audio before uploading by embedding imperceptible perturbations on original speeches to prevent high-quality synthetic speech. In SafeSpeech, we devise a robust and universal proactive protection technique, \textbf{S}peech \textbf{PE}rturbative \textbf{C}oncealment (\textbf{SPEC}), that leverages a surrogate model to generate universally applicable perturbation for generative synthetic models. Moreover, we optimize the human perception of embedded perturbation in terms of time and frequency domains. To evaluate our method comprehensively, we conduct extensive experiments across advanced models and datasets, both subjectively and objectively. Our experimental results demonstrate that SafeSpeech achieves state-of-the-art (SOTA) voice protection effectiveness and transferability and is highly robust against advanced adaptive adversaries. Moreover, SafeSpeech has real-time capability in real-world tests. The source code is available at \href{https://github.com/wxzyd123/SafeSpeech}{https://github.com/wxzyd123/SafeSpeech}.