 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniSRCodec: Unified and Low-Bitrate Single Codebook Codec with Sub-Band Reconstruction
Jan 06, 2026Neural Audio Codecs (NACs) can reduce transmission overhead by performing compact compression and reconstruction, which also aim to bridge the gap between continuous and discrete signals. Existing NACs can be divided into two categories: multi-codebook and single-codebook codecs. Multi-codebook codecs face challenges such as structural complexity and difficulty in adapting to downstream tasks, while single-codebook codecs, though structurally simpler, suffer from low-fidelity, ineffective modeling of unified audio, and an inability to support modeling of high-frequency audio. We propose the UniSRCodec, a single-codebook codec capable of supporting high sampling rate, low-bandwidth, high fidelity, and unified. We analyze the inefficiency of waveform-based compression and introduce the time and frequency compression method using the Mel-spectrogram, and cooperate with a Vocoder to recover the phase information of the original audio. Moreover, we propose a sub-band reconstruction technique to achieve high-quality compression across both low and high frequency bands. Subjective and objective experimental results demonstrate that UniSRCodec achieves state-of-the-art (SOTA) performance among cross-domain single-codebook codecs with only a token rate of 40, and its reconstruction quality is comparable to that of certain multi-codebook methods. Our demo page is available at https://wxzyd123.github.io/unisrcodec.
E2E-VGuard: Adversarial Prevention for Production LLM-based End-To-End Speech Synthesis
Nov 10, 2025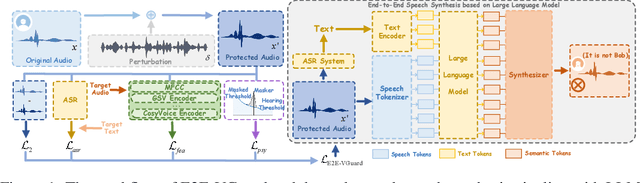
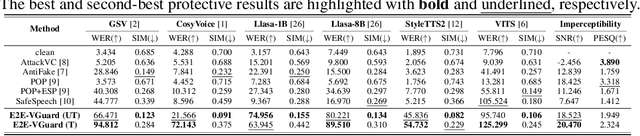

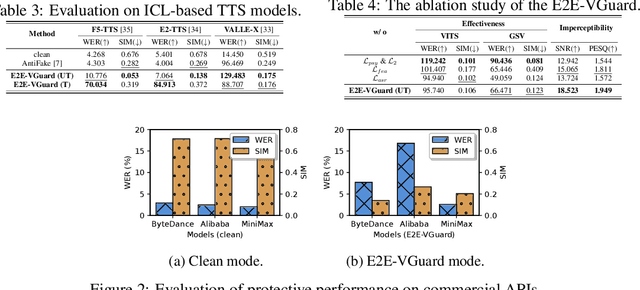
Recent advancements in speech synthesis technology have enriched our daily lives, with high-quality and human-like audio widely adopted across real-world applications. However, malicious exploitation like voice-cloning fraud poses severe security risks. Existing defense techniques struggle to address the production large language model (LLM)-based speech synthesis. While previous studies have considered the protection for fine-tuning synthesizers, they assume manually annotated transcripts. Given the labor intensity of manual annotation, end-to-end (E2E) systems leveraging automatic speech recognition (ASR) to generate transcripts are becoming increasingly prevalent, e.g., voice cloning via commercial APIs. Therefore, this E2E speech synthesis also requires new security mechanisms. To tackle these challenges, we propose E2E-VGuard, a proactive defense framework for two emerging threats: (1) production LLM-based speech synthesis, and (2) the novel attack arising from ASR-driven E2E scenarios. Specifically, we employ the encoder ensemble with a feature extractor to protect timbre, while ASR-targeted adversarial examples disrupt pronunciation. Moreover, we incorporate the psychoacoustic model to ensure perturbative imperceptibility. For a comprehensive evaluation, we test 16 open-source synthesizers and 3 commercial APIs across Chinese and English datasets, confirming E2E-VGuard's effectiveness in timbre and pronunciation protection. Real-world deployment validation is also conducted. Our code and demo page are available at https://wxzyd123.github.io/e2e-vguard/.
A Survey of Scientific Large Language Models: From Data Foundations to Agent Frontiers
Aug 28, 2025



Scientific Large Language Models (Sci-LLMs) are transforming how knowledge is represented, integrated, and applied in scientific research, yet their progress is shaped by the complex nature of scientific data. This survey presents a comprehensive, data-centric synthesis that reframes the development of Sci-LLMs as a co-evolution between models and their underlying data substrate. We formulate a unified taxonomy of scientific data and a hierarchical model of scientific knowledge, emphasizing the multimodal, cross-scale, and domain-specific challenges that differentiate scientific corpora from general natural language processing datasets. We systematically review recent Sci-LLMs, from general-purpose foundations to specialized models across diverse scientific disciplines, alongside an extensive analysis of over 270 pre-/post-training datasets, showing why Sci-LLMs pose distinct demands -- heterogeneous, multi-scale, uncertainty-laden corpora that require representations preserving domain invariance and enabling cross-modal reasoning. On evaluation, we examine over 190 benchmark datasets and trace a shift from static exams toward process- and discovery-oriented assessments with advanced evaluation protocols. These data-centric analyses highlight persistent issues in scientific data development and discuss emerging solutions involving semi-automated annotation pipelines and expert validation. Finally, we outline a paradigm shift toward closed-loop systems where autonomous agents based on Sci-LLMs actively experiment, validate, and contribute to a living, evolving knowledge base. Collectively, this work provides a roadmap for building trustworthy, continually evolving artificial intelligence (AI) systems that function as a true partner in accelerating scientific discovery.
Self-Supervised Enhancement of Forward-Looking Sonar Images: Bridging Cross-Modal Degradation Gaps through Feature Space Transformation and Multi-Frame Fusion
Apr 16, 2025Enhancing forward-looking sonar images is critical for accurate underwater target detection. Current deep learning methods mainly rely on supervised training with simulated data, but the difficulty in obtaining high-quality real-world paired data limits their practical use and generalization. Although self-supervised approaches from remote sensing partially alleviate data shortages, they neglect the cross-modal degradation gap between sonar and remote sensing images. Directly transferring pretrained weights often leads to overly smooth sonar images, detail loss, and insufficient brightness. To address this, we propose a feature-space transformation that maps sonar images from the pixel domain to a robust feature domain, effectively bridging the degradation gap. Additionally, our self-supervised multi-frame fusion strategy leverages complementary inter-frame information to naturally remove speckle noise and enhance target-region brightness. Experiments on three self-collected real-world forward-looking sonar datasets show that our method significantly outperforms existing approaches, effectively suppressing noise, preserving detailed edges, and substantially improving brightness, demonstrating strong potential for underwater target detection applications.
SafeSpeech: Robust and Universal Voice Protection Against Malicious Speech Synthesis
Apr 14, 2025



Speech synthesis technology has brought great convenience, while the widespread usage of realistic deepfake audio has triggered hazards. Malicious adversaries may unauthorizedly collect victims' speeches and clone a similar voice for illegal exploitation (\textit{e.g.}, telecom fraud). However, the existing defense methods cannot effectively prevent deepfake exploitation and are vulnerable to robust training techniques. Therefore, a more effective and robust data protection method is urgently needed. In response, we propose a defensive framework, \textit{\textbf{SafeSpeech}}, which protects the users' audio before uploading by embedding imperceptible perturbations on original speeches to prevent high-quality synthetic speech. In SafeSpeech, we devise a robust and universal proactive protection technique, \textbf{S}peech \textbf{PE}rturbative \textbf{C}oncealment (\textbf{SPEC}), that leverages a surrogate model to generate universally applicable perturbation for generative synthetic models. Moreover, we optimize the human perception of embedded perturbation in terms of time and frequency domains. To evaluate our method comprehensively, we conduct extensive experiments across advanced models and datasets, both subjectively and objectively. Our experimental results demonstrate that SafeSpeech achieves state-of-the-art (SOTA) voice protection effectiveness and transferability and is highly robust against advanced adaptive adversaries. Moreover, SafeSpeech has real-time capability in real-world tests. The source code is available at \href{https://github.com/wxzyd123/SafeSpeech}{https://github.com/wxzyd123/SafeSpeech}.
Mitigating Unauthorized Speech Synthesis for Voice Protection
Oct 28, 2024

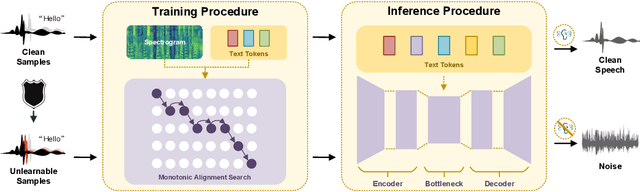

With just a few speech samples, it is possible to perfectly replicate a speaker's voice in recent years, while malicious voice exploitation (e.g., telecom fraud for illegal financial gain) has brought huge hazards in our daily lives. Therefore, it is crucial to protect publicly accessible speech data that contains sensitive information, such as personal voiceprints. Most previous defense methods have focused on spoofing speaker verification systems in timbre similarity but the synthesized deepfake speech is still of high quality. In response to the rising hazards, we devise an effective, transferable, and robust proactive protection technology named Pivotal Objective Perturbation (POP) that applies imperceptible error-minimizing noises on original speech samples to prevent them from being effectively learned for text-to-speech (TTS) synthesis models so that high-quality deepfake speeches cannot be generated. We conduct extensive experiments on state-of-the-art (SOTA) TTS models utilizing objective and subjective metrics to comprehensively evaluate our proposed method. The experimental results demonstrate outstanding effectiveness and transferability across various models. Compared to the speech unclarity score of 21.94% from voice synthesizers trained on samples without protection, POP-protected samples significantly increase it to 127.31%. Moreover, our method shows robustness against noise reduction and data augmentation techniques, thereby greatly reducing potential hazards.
HiddenSpeaker: Generate Imperceptible Unlearnable Audios for Speaker Verification System
May 27, 2024In recent years, the remarkable advancements in deep neural networks have brought tremendous convenience. However, the training process of a highly effective model necessitates a substantial quantity of samples, which brings huge potential threats, like unauthorized exploitation with privacy leakage. In response, we propose a framework named HiddenSpeaker, embedding imperceptible perturbations within the training speech samples and rendering them unlearnable for deep-learning-based speaker verification systems that employ large-scale speakers for efficient training. The HiddenSpeaker utilizes a simplified error-minimizing method named Single-Level Error-Minimizing (SLEM) to generate specific and effective perturbations. Additionally, a hybrid objective function is employed for human perceptual optimization, ensuring the perturbation is indistinguishable from human listeners. We conduct extensive experiments on multiple state-of-the-art (SOTA) models in the speaker verification domain to evaluate HiddenSpeaker. Our results demonstrate that HiddenSpeaker not only deceives the model with unlearnable samples but also enhances the imperceptibility of the perturbations, showcasing strong transferability across different models.
DGraph: A Large-Scale Financial Dataset for Graph Anomaly Detection
Jul 12, 2022


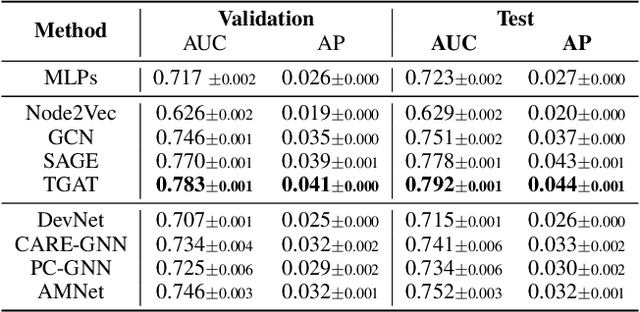
Graph Anomaly Detection (GAD) has recently become a hot research spot due to its practicability and theoretical value. Since GAD emphasizes the application and the rarity of anomalous samples, enriching the varieties of its datasets is a fundamental work. Thus, this paper present DGraph, a real-world dynamic graph in the finance domain. DGraph overcomes many limitations of current GAD datasets. It contains about 3M nodes, 4M dynamic edges, and 1M ground-truth nodes. We provide a comprehensive observation of DGraph, revealing that anomalous nodes and normal nodes generally have different structures, neighbor distribution, and temporal dynamics. Moreover, it suggests that those unlabeled nodes are also essential for detecting fraudsters. Furthermore, we conduct extensive experiments on DGraph. Observation and experiments demonstrate that DGraph is propulsive to advance GAD research and enable in-depth exploration of anomalous nodes.
Deep Multi-view Image Fusion for Soybean Yield Estimation in Breeding Applications Deep Multi-view Image Fusion for Soybean Yield Estimation in Breeding Applications
Nov 13, 2020
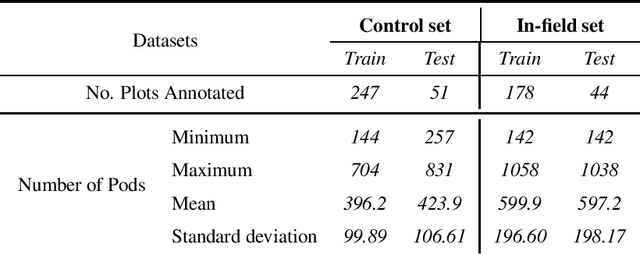
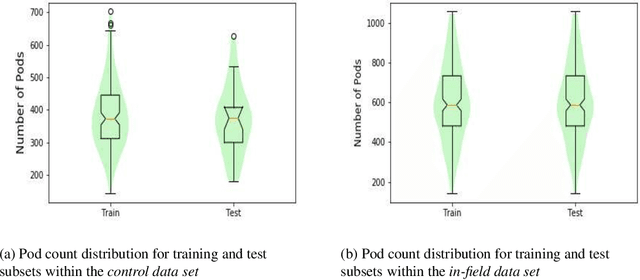
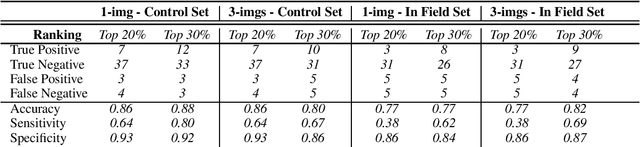
Reliable seed yield estimation is an indispensable step in plant breeding programs geared towards cultivar development in major row crops. The objective of this study is to develop a machine learning (ML) approach adept at soybean [\textit{Glycine max} L. (Merr.)] pod counting to enable genotype seed yield rank prediction from in-field video data collected by a ground robot. To meet this goal, we developed a multi-view image-based yield estimation framework utilizing deep learning architectures. Plant images captured from different angles were fused to estimate the yield and subsequently to rank soybean genotypes for application in breeding decisions. We used data from controlled imaging environment in field, as well as from plant breeding test plots in field to demonstrate the efficacy of our framework via comparing performance with manual pod counting and yield estimation. Our results demonstrate the promise of ML models in making breeding decisions with significant reduction of time and human effort, and opening new breeding methods avenues to develop cultivars.