 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Reinforcement Learning for Radiology Report Generation with Evidence-aware Rewards and Self-correcting Preference Learning
Apr 15, 2026Recent reinforcement learning (RL) approaches have advanced radiology report generation (RRG), yet two core limitations persist: (1) report-level rewards offer limited evidence-grounded guidance for clinical faithfulness; and (2) current methods lack an explicit self-improving mechanism to align with clinical preference. We introduce clinically aligned Evidence-aware Self-Correcting Reinforcement Learning (ESC-RL), comprising two key components. First, a Group-wise Evidence-aware Alignment Reward (GEAR) delivers group-wise, evidence-aware feedback. GEAR reinforces consistent grounding for true positives, recovers missed findings for false negatives, and suppresses unsupported content for false positives. Second, a Self-correcting Preference Learning (SPL) strategy automatically constructs a reliable, disease-aware preference dataset from multiple noisy observations and leverages an LLM to synthesize refined reports without human supervision. ESC-RL promotes clinically faithful, disease-aligned reward and supports continual self-improvement during training. Extensive experiments on two public chest X-ray datasets demonstrate consistent gains and state-of-the-art performance.
SafeSpeech: Robust and Universal Voice Protection Against Malicious Speech Synthesis
Apr 14, 2025



Speech synthesis technology has brought great convenience, while the widespread usage of realistic deepfake audio has triggered hazards. Malicious adversaries may unauthorizedly collect victims' speeches and clone a similar voice for illegal exploitation (\textit{e.g.}, telecom fraud). However, the existing defense methods cannot effectively prevent deepfake exploitation and are vulnerable to robust training techniques. Therefore, a more effective and robust data protection method is urgently needed. In response, we propose a defensive framework, \textit{\textbf{SafeSpeech}}, which protects the users' audio before uploading by embedding imperceptible perturbations on original speeches to prevent high-quality synthetic speech. In SafeSpeech, we devise a robust and universal proactive protection technique, \textbf{S}peech \textbf{PE}rturbative \textbf{C}oncealment (\textbf{SPEC}), that leverages a surrogate model to generate universally applicable perturbation for generative synthetic models. Moreover, we optimize the human perception of embedded perturbation in terms of time and frequency domains. To evaluate our method comprehensively, we conduct extensive experiments across advanced models and datasets, both subjectively and objectively. Our experimental results demonstrate that SafeSpeech achieves state-of-the-art (SOTA) voice protection effectiveness and transferability and is highly robust against advanced adaptive adversaries. Moreover, SafeSpeech has real-time capability in real-world tests. The source code is available at \href{https://github.com/wxzyd123/SafeSpeech}{https://github.com/wxzyd123/SafeSpeech}.
Mitigating Unauthorized Speech Synthesis for Voice Protection
Oct 28, 2024

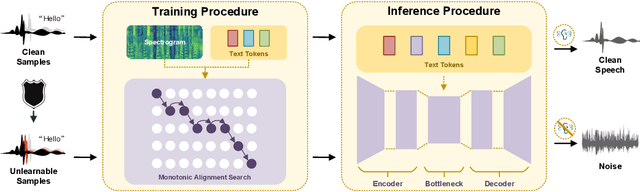

With just a few speech samples, it is possible to perfectly replicate a speaker's voice in recent years, while malicious voice exploitation (e.g., telecom fraud for illegal financial gain) has brought huge hazards in our daily lives. Therefore, it is crucial to protect publicly accessible speech data that contains sensitive information, such as personal voiceprints. Most previous defense methods have focused on spoofing speaker verification systems in timbre similarity but the synthesized deepfake speech is still of high quality. In response to the rising hazards, we devise an effective, transferable, and robust proactive protection technology named Pivotal Objective Perturbation (POP) that applies imperceptible error-minimizing noises on original speech samples to prevent them from being effectively learned for text-to-speech (TTS) synthesis models so that high-quality deepfake speeches cannot be generated. We conduct extensive experiments on state-of-the-art (SOTA) TTS models utilizing objective and subjective metrics to comprehensively evaluate our proposed method. The experimental results demonstrate outstanding effectiveness and transferability across various models. Compared to the speech unclarity score of 21.94% from voice synthesizers trained on samples without protection, POP-protected samples significantly increase it to 127.31%. Moreover, our method shows robustness against noise reduction and data augmentation techniques, thereby greatly reducing potential hazards.
Self-Localization of Parking Robots Using Square-Like Landmarks
Dec 23, 2018
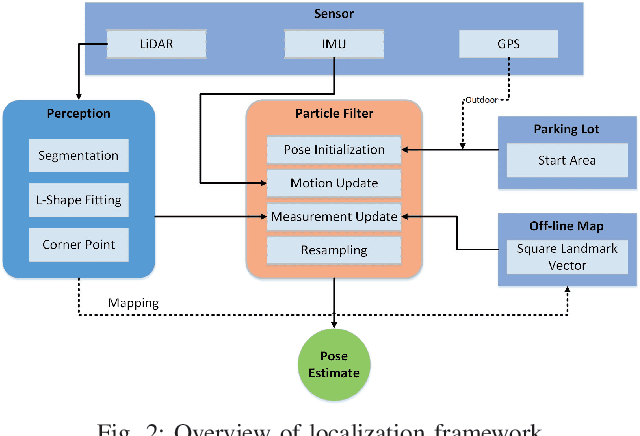
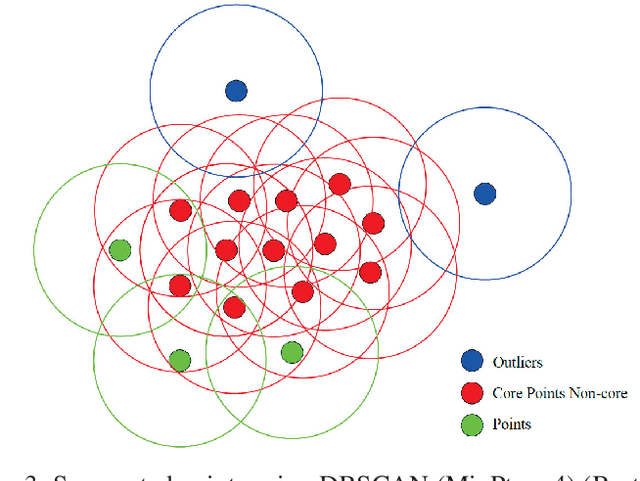
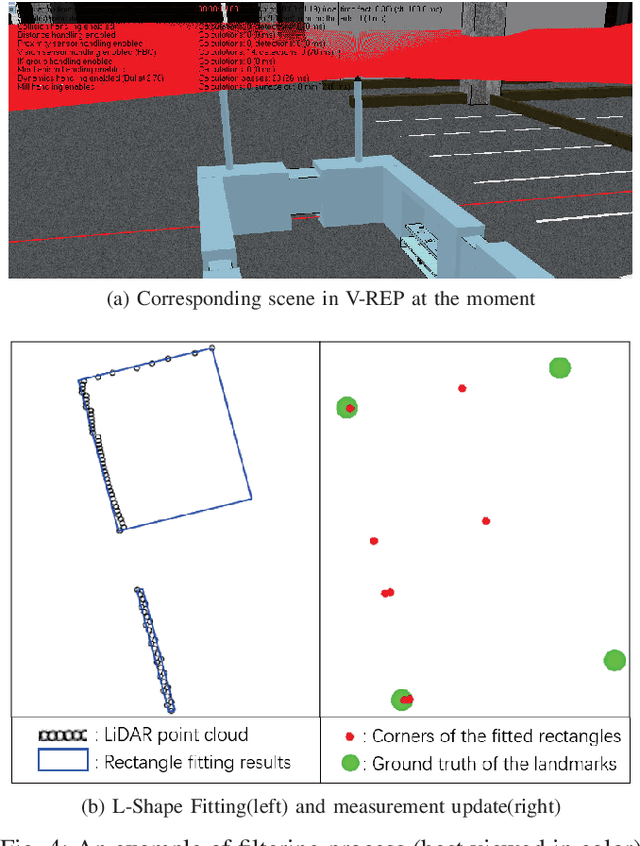
In this paper, we present a framework for self-localization of parking robots in a parking lot innovatively using square-like landmarks, aiming to provide a positioning solution with low cost but high accuracy. It utilizes square structures common in parking lots such as pillars, corners or charging piles as robust landmarks and deduces the global pose of the robot in conjunction with an off-line map. The localization is performed in real-time via Particle Filter using a single line scanning LiDAR as main sensor, an odometry as secondary information sources. The system has been tested in a simulation environment built in V-REP, the result of which demonstrates its positioning accuracy below 0.20 m and a corresponding heading error below 1{\deg}.