 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Unauthorized Speech Synthesis for Voice Protection
Paper and Code


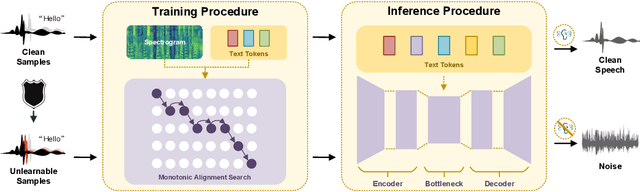

With just a few speech samples, it is possible to perfectly replicate a speaker's voice in recent years, while malicious voice exploitation (e.g., telecom fraud for illegal financial gain) has brought huge hazards in our daily lives. Therefore, it is crucial to protect publicly accessible speech data that contains sensitive information, such as personal voiceprints. Most previous defense methods have focused on spoofing speaker verification systems in timbre similarity but the synthesized deepfake speech is still of high quality. In response to the rising hazards, we devise an effective, transferable, and robust proactive protection technology named Pivotal Objective Perturbation (POP) that applies imperceptible error-minimizing noises on original speech samples to prevent them from being effectively learned for text-to-speech (TTS) synthesis models so that high-quality deepfake speeches cannot be generated. We conduct extensive experiments on state-of-the-art (SOTA) TTS models utilizing objective and subjective metrics to comprehensively evaluate our proposed method. The experimental results demonstrate outstanding effectiveness and transferability across various models. Compared to the speech unclarity score of 21.94% from voice synthesizers trained on samples without protection, POP-protected samples significantly increase it to 127.31%. Moreover, our method shows robustness against noise reduction and data augmentation techniques, thereby greatly reducing potential hazards.