 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Multi-view Image Fusion for Soybean Yield Estimation in Breeding Applications Deep Multi-view Image Fusion for Soybean Yield Estimation in Breeding Applications
Nov 13, 2020
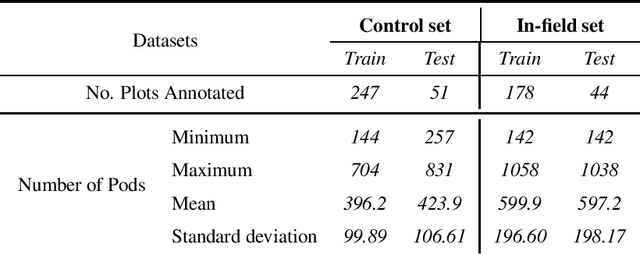
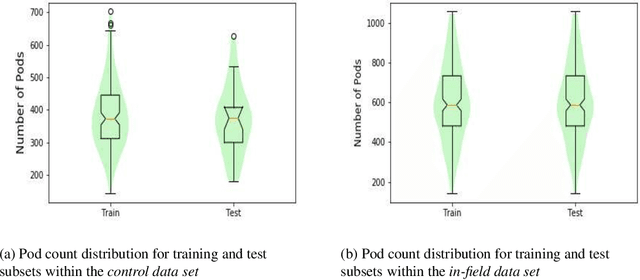
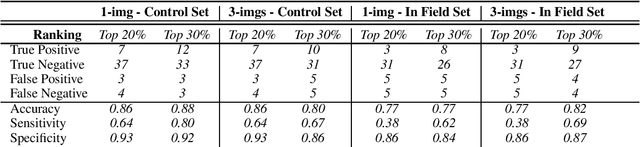
Reliable seed yield estimation is an indispensable step in plant breeding programs geared towards cultivar development in major row crops. The objective of this study is to develop a machine learning (ML) approach adept at soybean [\textit{Glycine max} L. (Merr.)] pod counting to enable genotype seed yield rank prediction from in-field video data collected by a ground robot. To meet this goal, we developed a multi-view image-based yield estimation framework utilizing deep learning architectures. Plant images captured from different angles were fused to estimate the yield and subsequently to rank soybean genotypes for application in breeding decisions. We used data from controlled imaging environment in field, as well as from plant breeding test plots in field to demonstrate the efficacy of our framework via comparing performance with manual pod counting and yield estimation. Our results demonstrate the promise of ML models in making breeding decisions with significant reduction of time and human effort, and opening new breeding methods avenues to develop cultivars.
Planning for Aerial Robot Teams for Wide-Area Biometric and Phenotypic Data Collection
Nov 03, 2020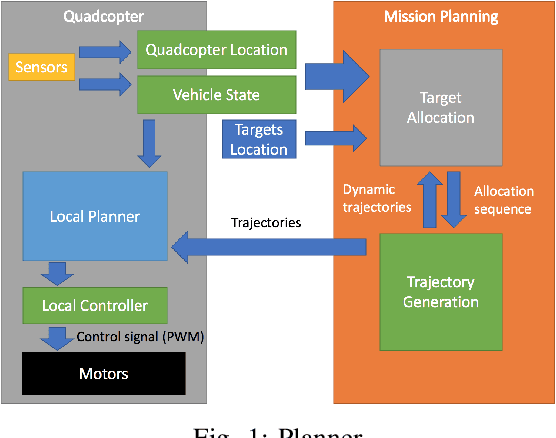
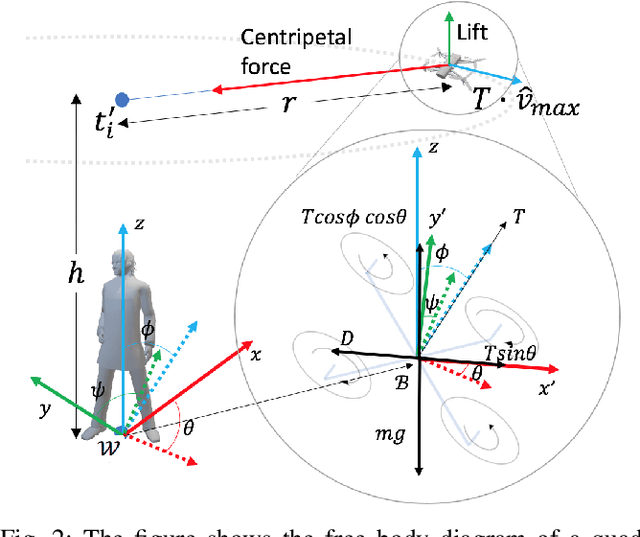


This work presents an efficient and implementable solution to the problem of joint task allocation and path planning in a multi-UAV platform deployed for biometric data collection in-the-wild. The sensing requirement associated with the task gives rise to an uncanny variant of the traditional vehicle routing problem with coverage/sensing constraints. As is the case in several multi-robot path-planning problems, our problem reduces to an $m$TSP problem. In order to tame the computational challenges associated with the problem, we propose a hierarchical solution that decouples the vehicle routing problem from the target allocation problem. As a tangible solution to the allocation problem, we use a clustering-based technique that incorporates temporal uncertainty in the cardinality and position of the robots. Finally, we implement the proposed techniques on our multi-quadcopter platforms.
Partitioning Strategies and Task Allocation for Target-tracking with Multiple Guards in Polygonal Environments
Nov 15, 2016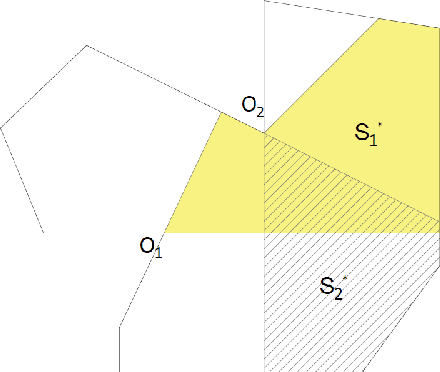
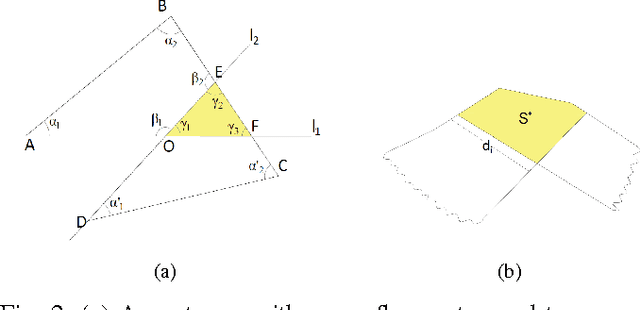
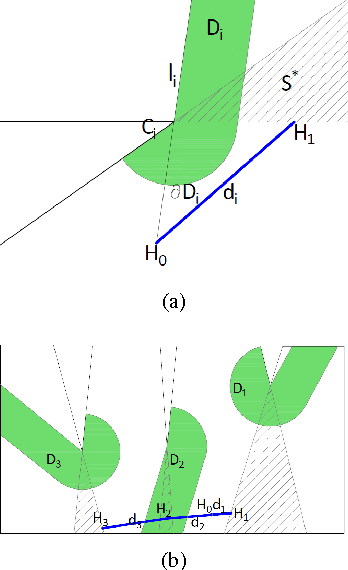
This paper presents an algorithm to deploy a team of {\it free} guards equipped with omni-directional cameras for tracking a bounded speed intruder inside a simply-connected polygonal environment. The proposed algorithm partitions the environment into smaller polygons, and assigns a guard to each partition so that the intruder is visible to at least one guard at all times. Based on the concept of {\it dynamic zones} introduced in this paper, we propose event-triggered strategies for the guards to track the intruder. We show that the number of guards deployed by the algorithm for tracking is strictly less than $\lfloor {\frac{n}{3}} \rfloor$ which is sufficient and sometimes necessary for coverage. We derive an upper bound on the speed of the mobile guard required for successful tracking which depends on the intruder's speed, the road map of the mobile guards, and geometry of the environment. Finally, we extend the aforementioned analysis to orthogonal polygons, and show that the upper bound on the number of guards deployed for tracking is strictly less than $\lfloor {\frac{n}{4}} \rfloor$ which is sufficient and sometimes necessary for the coverage problem.
Towards a Framework for Tracking Multiple Targets: Hybrid Systems meets Computational Geometry
Nov 15, 2016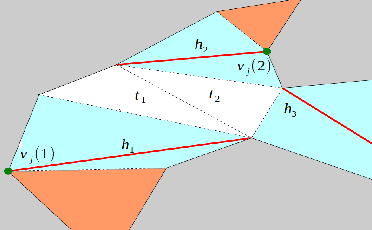


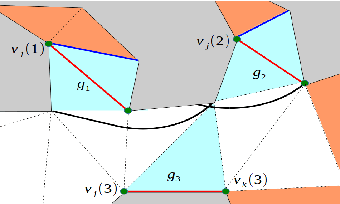
We investigate a variation of the art gallery problem in which a team of mobile guards tries to track an unpredictable intruder in a simply-connected polygonal environment. In this work, we use the deployment strategy for diagonal guards originally proposed in [1]. The guards are confined to move along the diagonals of a polygon and the intruder can move freely within the environment. We define critical regions to generate event-triggered strategies for the guards. We design a hybrid automaton based on the critical regions to model the tracking problem. Based on reachability analysis, we provide necessary and sufficient conditions for tracking in terms of the maximal controlled invariant set of the hybrid system. We express these conditions in terms of the critical curves to find sufficient conditions for n/4 guards to track the mobile intruder using the reachability analysis.
Adaptive-Rate Compressive Sensing Using Side Information
Jan 03, 2014



We provide two novel adaptive-rate compressive sensing (CS) strategies for sparse, time-varying signals using side information. Our first method utilizes extra cross-validation measurements, and the second one exploits extra low-resolution measurements. Unlike the majority of current CS techniques, we do not assume that we know an upper bound on the number of significant coefficients that comprise the images in the video sequence. Instead, we use the side information to predict the number of significant coefficients in the signal at the next time instant. For each image in the video sequence, our techniques specify a fixed number of spatially-multiplexed CS measurements to acquire, and adjust this quantity from image to image. Our strategies are developed in the specific context of background subtraction for surveillance video, and we experimentally validate the proposed methods on real video sequences.