 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSciEvalKit: An Open-source Evaluation Toolkit for Scientific General Intelligence
Dec 30, 2025We introduce SciEvalKit, a unified benchmarking toolkit designed to evaluate AI models for science across a broad range of scientific disciplines and task capabilities. Unlike general-purpose evaluation platforms, SciEvalKit focuses on the core competencies of scientific intelligence, including Scientific Multimodal Perception, Scientific Multimodal Reasoning, Scientific Multimodal Understanding, Scientific Symbolic Reasoning, Scientific Code Generation, Science Hypothesis Generation and Scientific Knowledge Understanding. It supports six major scientific domains, spanning from physics and chemistry to astronomy and materials science. SciEvalKit builds a foundation of expert-grade scientific benchmarks, curated from real-world, domain-specific datasets, ensuring that tasks reflect authentic scientific challenges. The toolkit features a flexible, extensible evaluation pipeline that enables batch evaluation across models and datasets, supports custom model and dataset integration, and provides transparent, reproducible, and comparable results. By bridging capability-based evaluation and disciplinary diversity, SciEvalKit offers a standardized yet customizable infrastructure to benchmark the next generation of scientific foundation models and intelligent agents. The toolkit is open-sourced and actively maintained to foster community-driven development and progress in AI4Science.
Probing Scientific General Intelligence of LLMs with Scientist-Aligned Workflows
Dec 18, 2025Despite advances in scientific AI, a coherent framework for Scientific General Intelligence (SGI)-the ability to autonomously conceive, investigate, and reason across scientific domains-remains lacking. We present an operational SGI definition grounded in the Practical Inquiry Model (PIM: Deliberation, Conception, Action, Perception) and operationalize it via four scientist-aligned tasks: deep research, idea generation, dry/wet experiments, and experimental reasoning. SGI-Bench comprises over 1,000 expert-curated, cross-disciplinary samples inspired by Science's 125 Big Questions, enabling systematic evaluation of state-of-the-art LLMs. Results reveal gaps: low exact match (10--20%) in deep research despite step-level alignment; ideas lacking feasibility and detail; high code executability but low execution result accuracy in dry experiments; low sequence fidelity in wet protocols; and persistent multimodal comparative-reasoning challenges. We further introduce Test-Time Reinforcement Learning (TTRL), which optimizes retrieval-augmented novelty rewards at inference, enhancing hypothesis novelty without reference answer. Together, our PIM-grounded definition, workflow-centric benchmark, and empirical insights establish a foundation for AI systems that genuinely participate in scientific discovery.
A Survey of Scientific Large Language Models: From Data Foundations to Agent Frontiers
Aug 28, 2025



Scientific Large Language Models (Sci-LLMs) are transforming how knowledge is represented, integrated, and applied in scientific research, yet their progress is shaped by the complex nature of scientific data. This survey presents a comprehensive, data-centric synthesis that reframes the development of Sci-LLMs as a co-evolution between models and their underlying data substrate. We formulate a unified taxonomy of scientific data and a hierarchical model of scientific knowledge, emphasizing the multimodal, cross-scale, and domain-specific challenges that differentiate scientific corpora from general natural language processing datasets. We systematically review recent Sci-LLMs, from general-purpose foundations to specialized models across diverse scientific disciplines, alongside an extensive analysis of over 270 pre-/post-training datasets, showing why Sci-LLMs pose distinct demands -- heterogeneous, multi-scale, uncertainty-laden corpora that require representations preserving domain invariance and enabling cross-modal reasoning. On evaluation, we examine over 190 benchmark datasets and trace a shift from static exams toward process- and discovery-oriented assessments with advanced evaluation protocols. These data-centric analyses highlight persistent issues in scientific data development and discuss emerging solutions involving semi-automated annotation pipelines and expert validation. Finally, we outline a paradigm shift toward closed-loop systems where autonomous agents based on Sci-LLMs actively experiment, validate, and contribute to a living, evolving knowledge base. Collectively, this work provides a roadmap for building trustworthy, continually evolving artificial intelligence (AI) systems that function as a true partner in accelerating scientific discovery.
EMind: A Foundation Model for Multi-task Electromagnetic Signals Understanding
Aug 26, 2025Deep understanding of electromagnetic signals is fundamental to dynamic spectrum management, intelligent transportation, autonomous driving and unmanned vehicle perception. The field faces challenges because electromagnetic signals differ greatly from text and images, showing high heterogeneity, strong background noise and complex joint time frequency structure, which prevents existing general models from direct use. Electromagnetic communication and sensing tasks are diverse, current methods lack cross task generalization and transfer efficiency, and the scarcity of large high quality datasets blocks the creation of a truly general multitask learning framework. To overcome these issue, we introduce EMind, an electromagnetic signals foundation model that bridges large scale pretraining and the unique nature of this modality. We build the first unified and largest standardized electromagnetic signal dataset covering multiple signal types and tasks. By exploiting the physical properties of electromagnetic signals, we devise a length adaptive multi-signal packing method and a hardware-aware training strategy that enable efficient use and representation learning from heterogeneous multi-source signals. Experiments show that EMind achieves strong performance and broad generalization across many downstream tasks, moving decisively from task specific models to a unified framework for electromagnetic intelligence. The code is available at: https://github.com/GabrielleTse/EMind.
OmniEarth-Bench: Towards Holistic Evaluation of Earth's Six Spheres and Cross-Spheres Interactions with Multimodal Observational Earth Data
May 29, 2025Existing benchmarks for Earth science multimodal learning exhibit critical limitations in systematic coverage of geosystem components and cross-sphere interactions, often constrained to isolated subsystems (only in Human-activities sphere or atmosphere) with limited evaluation dimensions (less than 16 tasks). To address these gaps, we introduce OmniEarth-Bench, the first comprehensive multimodal benchmark spanning all six Earth science spheres (atmosphere, lithosphere, Oceansphere, cryosphere, biosphere and Human-activities sphere) and cross-spheres with one hundred expert-curated evaluation dimensions. Leveraging observational data from satellite sensors and in-situ measurements, OmniEarth-Bench integrates 29,779 annotations across four tiers: perception, general reasoning, scientific knowledge reasoning and chain-of-thought (CoT) reasoning. This involves the efforts of 2-5 experts per sphere to establish authoritative evaluation dimensions and curate relevant observational datasets, 40 crowd-sourcing annotators to assist experts for annotations, and finally, OmniEarth-Bench is validated via hybrid expert-crowd workflows to reduce label ambiguity. Experiments on 9 state-of-the-art MLLMs reveal that even the most advanced models struggle with our benchmarks, where none of them reach 35\% accuracy. Especially, in some cross-spheres tasks, the performance of leading models like GPT-4o drops to 0.0\%. OmniEarth-Bench sets a new standard for geosystem-aware AI, advancing both scientific discovery and practical applications in environmental monitoring and disaster prediction. The dataset, source code, and trained models were released.
GeoLLaVA-8K: Scaling Remote-Sensing Multimodal Large Language Models to 8K Resolution
May 27, 2025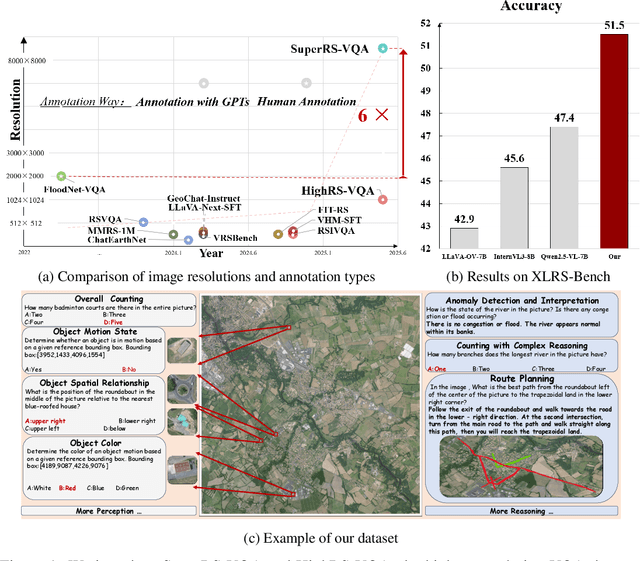
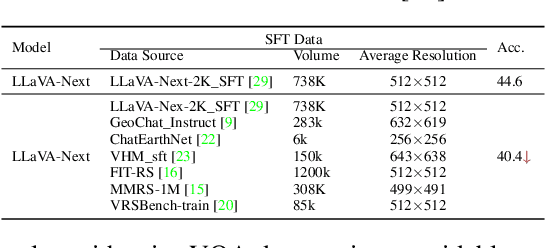
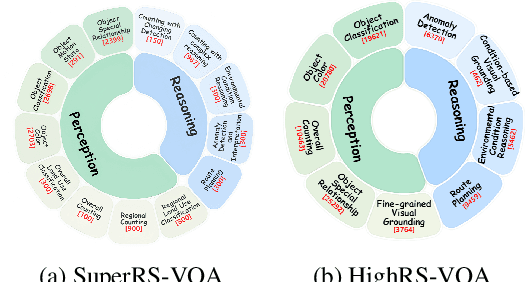
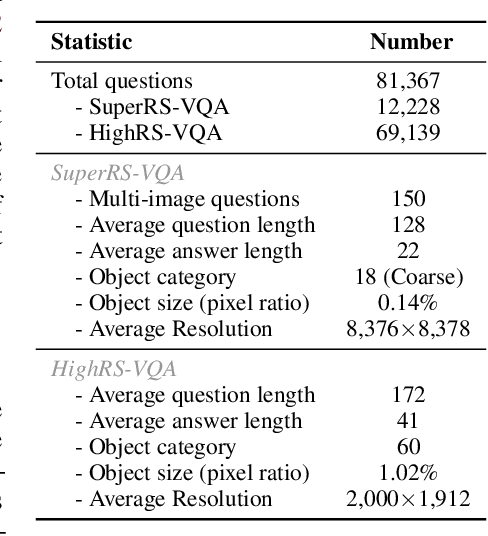
Ultra-high-resolution (UHR) remote sensing (RS) imagery offers valuable data for Earth observation but pose challenges for existing multimodal foundation models due to two key bottlenecks: (1) limited availability of UHR training data, and (2) token explosion caused by the large image size. To address data scarcity, we introduce SuperRS-VQA (avg. 8,376$\times$8,376) and HighRS-VQA (avg. 2,000$\times$1,912), the highest-resolution vision-language datasets in RS to date, covering 22 real-world dialogue tasks. To mitigate token explosion, our pilot studies reveal significant redundancy in RS images: crucial information is concentrated in a small subset of object-centric tokens, while pruning background tokens (e.g., ocean or forest) can even improve performance. Motivated by these findings, we propose two strategies: Background Token Pruning and Anchored Token Selection, to reduce the memory footprint while preserving key semantics.Integrating these techniques, we introduce GeoLLaVA-8K, the first RS-focused multimodal large language model capable of handling inputs up to 8K$\times$8K resolution, built on the LLaVA framework. Trained on SuperRS-VQA and HighRS-VQA, GeoLLaVA-8K sets a new state-of-the-art on the XLRS-Bench.
TiMo: Spatiotemporal Foundation Model for Satellite Image Time Series
May 13, 2025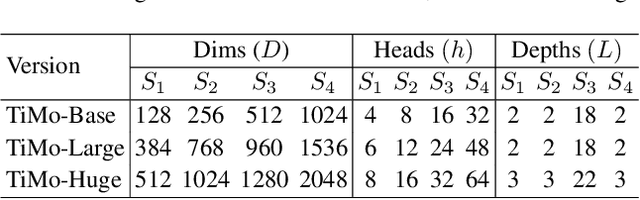
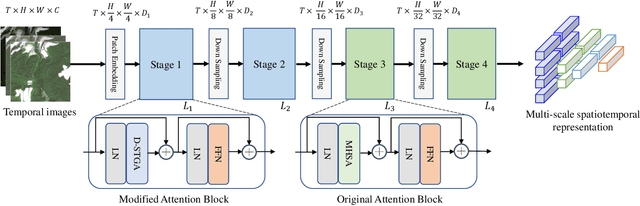
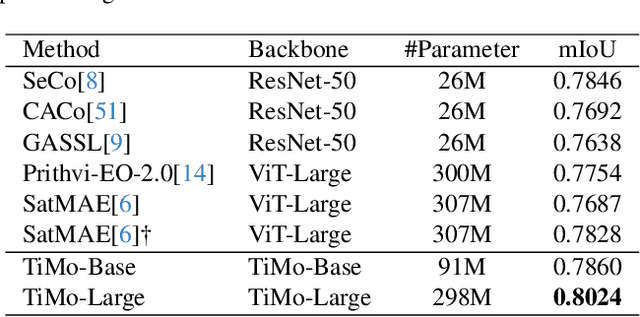
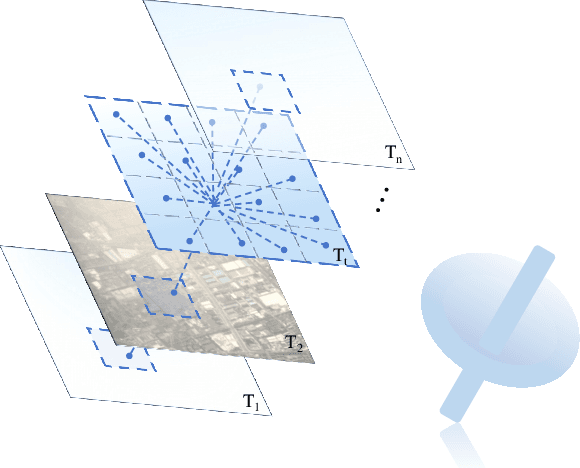
Satellite image time series (SITS) provide continuous observations of the Earth's surface, making them essential for applications such as environmental management and disaster assessment. However, existing spatiotemporal foundation models rely on plain vision transformers, which encode entire temporal sequences without explicitly capturing multiscale spatiotemporal relationships between land objects. This limitation hinders their effectiveness in downstream tasks. To overcome this challenge, we propose TiMo, a novel hierarchical vision transformer foundation model tailored for SITS analysis. At its core, we introduce a spatiotemporal gyroscope attention mechanism that dynamically captures evolving multiscale patterns across both time and space. For pre-training, we curate MillionST, a large-scale dataset of one million images from 100,000 geographic locations, each captured across 10 temporal phases over five years, encompassing diverse geospatial changes and seasonal variations. Leveraging this dataset, we adapt masked image modeling to pre-train TiMo, enabling it to effectively learn and encode generalizable spatiotemporal representations.Extensive experiments across multiple spatiotemporal tasks-including deforestation monitoring, land cover segmentation, crop type classification, and flood detection-demonstrate TiMo's superiority over state-of-the-art methods. Code, model, and dataset will be released at https://github.com/MiliLab/TiMo.
Self-Supervised Enhancement of Forward-Looking Sonar Images: Bridging Cross-Modal Degradation Gaps through Feature Space Transformation and Multi-Frame Fusion
Apr 16, 2025Enhancing forward-looking sonar images is critical for accurate underwater target detection. Current deep learning methods mainly rely on supervised training with simulated data, but the difficulty in obtaining high-quality real-world paired data limits their practical use and generalization. Although self-supervised approaches from remote sensing partially alleviate data shortages, they neglect the cross-modal degradation gap between sonar and remote sensing images. Directly transferring pretrained weights often leads to overly smooth sonar images, detail loss, and insufficient brightness. To address this, we propose a feature-space transformation that maps sonar images from the pixel domain to a robust feature domain, effectively bridging the degradation gap. Additionally, our self-supervised multi-frame fusion strategy leverages complementary inter-frame information to naturally remove speckle noise and enhance target-region brightness. Experiments on three self-collected real-world forward-looking sonar datasets show that our method significantly outperforms existing approaches, effectively suppressing noise, preserving detailed edges, and substantially improving brightness, demonstrating strong potential for underwater target detection applications.
XLRS-Bench: Could Your Multimodal LLMs Understand Extremely Large Ultra-High-Resolution Remote Sensing Imagery?
Mar 31, 2025The astonishing breakthrough of multimodal large language models (MLLMs) has necessitated new benchmarks to quantitatively assess their capabilities, reveal their limitations, and indicate future research directions. However, this is challenging in the context of remote sensing (RS), since the imagery features ultra-high resolution that incorporates extremely complex semantic relationships. Existing benchmarks usually adopt notably smaller image sizes than real-world RS scenarios, suffer from limited annotation quality, and consider insufficient dimensions of evaluation. To address these issues, we present XLRS-Bench: a comprehensive benchmark for evaluating the perception and reasoning capabilities of MLLMs in ultra-high-resolution RS scenarios. XLRS-Bench boasts the largest average image size (8500$\times$8500) observed thus far, with all evaluation samples meticulously annotated manually, assisted by a novel semi-automatic captioner on ultra-high-resolution RS images. On top of the XLRS-Bench, 16 sub-tasks are defined to evaluate MLLMs' 10 kinds of perceptual capabilities and 6 kinds of reasoning capabilities, with a primary emphasis on advanced cognitive processes that facilitate real-world decision-making and the capture of spatiotemporal changes. The results of both general and RS-focused MLLMs on XLRS-Bench indicate that further efforts are needed for real-world RS applications. We have open-sourced XLRS-Bench to support further research in developing more powerful MLLMs for remote sensing.
RoMA: Scaling up Mamba-based Foundation Models for Remote Sensing
Mar 13, 2025Recent advances in self-supervised learning for Vision Transformers (ViTs) have fueled breakthroughs in remote sensing (RS) foundation models. However, the quadratic complexity of self-attention poses a significant barrier to scalability, particularly for large models and high-resolution images. While the linear-complexity Mamba architecture offers a promising alternative, existing RS applications of Mamba remain limited to supervised tasks on small, domain-specific datasets. To address these challenges, we propose RoMA, a framework that enables scalable self-supervised pretraining of Mamba-based RS foundation models using large-scale, diverse, unlabeled data. RoMA enhances scalability for high-resolution images through a tailored auto-regressive learning strategy, incorporating two key innovations: 1) a rotation-aware pretraining mechanism combining adaptive cropping with angular embeddings to handle sparsely distributed objects with arbitrary orientations, and 2) multi-scale token prediction objectives that address the extreme variations in object scales inherent to RS imagery. Systematic empirical studies validate that Mamba adheres to RS data and parameter scaling laws, with performance scaling reliably as model and data size increase. Furthermore, experiments across scene classification, object detection, and semantic segmentation tasks demonstrate that RoMA-pretrained Mamba models consistently outperform ViT-based counterparts in both accuracy and computational efficiency. The source code and pretrained models will be released at https://github.com/MiliLab/RoMA.