 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSL: Sweet Spot Learning for Differentiated Guidance in Agentic Optimization
Jan 30, 2026Reinforcement learning with verifiable rewards has emerged as a powerful paradigm for training intelligent agents. However, existing methods typically employ binary rewards that fail to capture quality differences among trajectories achieving identical outcomes, thereby overlooking potential diversity within the solution space. Inspired by the ``sweet spot'' concept in tennis-the racket's core region that produces optimal hitting effects, we introduce \textbf{S}weet \textbf{S}pot \textbf{L}earning (\textbf{SSL}), a novel framework that provides differentiated guidance for agent optimization. SSL follows a simple yet effective principle: progressively amplified, tiered rewards guide policies toward the sweet-spot region of the solution space. This principle naturally adapts across diverse tasks: visual perception tasks leverage distance-tiered modeling to reward proximity, while complex reasoning tasks reward incremental progress toward promising solutions. We theoretically demonstrate that SSL preserves optimal solution ordering and enhances the gradient signal-to-noise ratio, thereby fostering more directed optimization. Extensive experiments across GUI perception, short/long-term planning, and complex reasoning tasks show consistent improvements over strong baselines on 12 benchmarks, achieving up to 2.5X sample efficiency gains and effective cross-task transferability. Our work establishes SSL as a general principle for training capable and robust agents.
HyperVL: An Efficient and Dynamic Multimodal Large Language Model for Edge Devices
Dec 16, 2025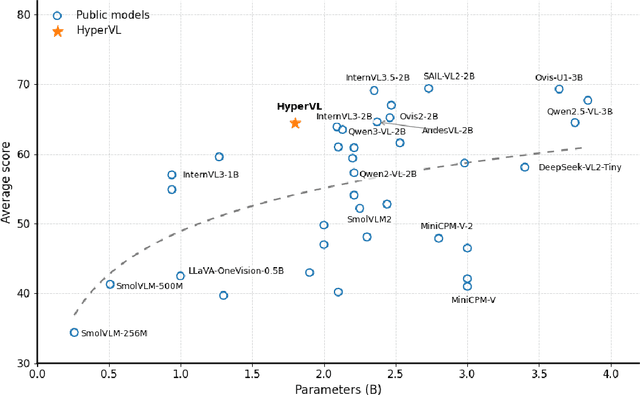

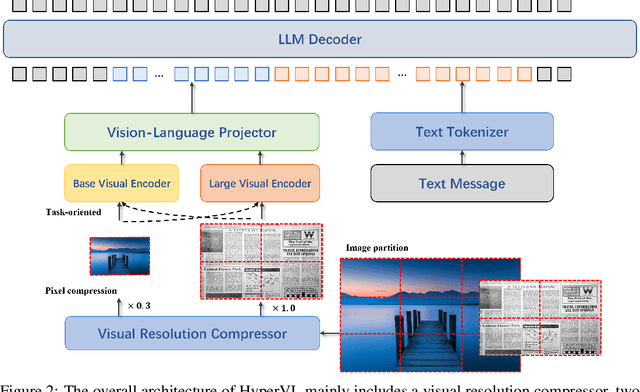

Current multimodal large lanauge models possess strong perceptual and reasoning capabilities, however high computational and memory requirements make them difficult to deploy directly on on-device environments. While small-parameter models are progressively endowed with strong general capabilities, standard Vision Transformer (ViT) encoders remain a critical bottleneck, suffering from excessive latency and memory consumption when processing high-resolution inputs.To address these challenges, we introduce HyperVL, an efficient multimodal large language model tailored for on-device inference. HyperVL adopts an image-tiling strategy to cap peak memory usage and incorporates two novel techniques: (1) a Visual Resolution Compressor (VRC) that adaptively predicts optimal encoding resolutions to eliminate redundant computation, and (2) Dual Consistency Learning (DCL), which aligns multi-scale ViT encoders within a unified framework, enabling dynamic switching between visual branches under a shared LLM. Extensive experiments demonstrate that HyperVL achieves state-of-the-art performance among models of comparable size across multiple benchmarks. Furthermore, it significantly significantly reduces latency and power consumption on real mobile devices, demonstrating its practicality for on-device multimodal inference.
GeoLLaVA-8K: Scaling Remote-Sensing Multimodal Large Language Models to 8K Resolution
May 27, 2025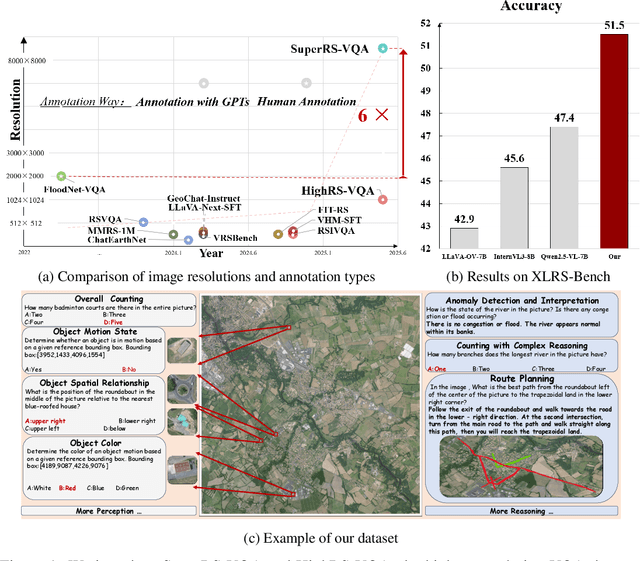
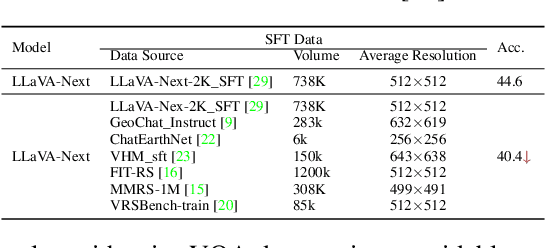
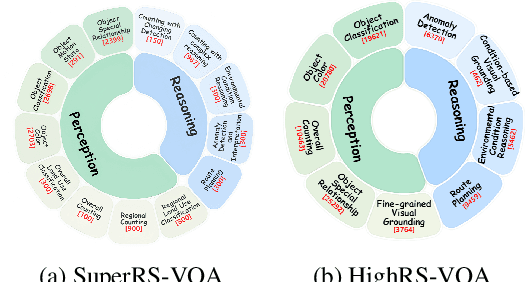
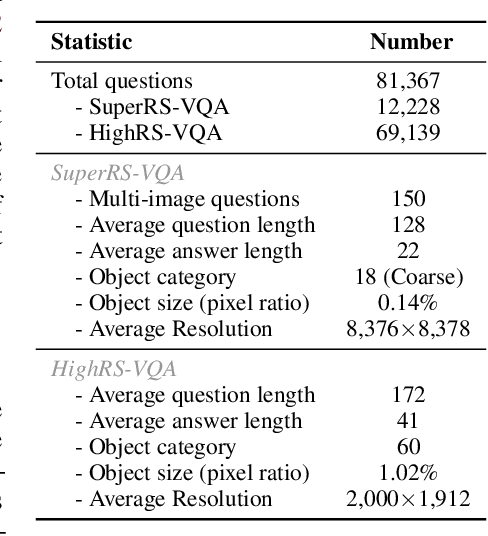
Ultra-high-resolution (UHR) remote sensing (RS) imagery offers valuable data for Earth observation but pose challenges for existing multimodal foundation models due to two key bottlenecks: (1) limited availability of UHR training data, and (2) token explosion caused by the large image size. To address data scarcity, we introduce SuperRS-VQA (avg. 8,376$\times$8,376) and HighRS-VQA (avg. 2,000$\times$1,912), the highest-resolution vision-language datasets in RS to date, covering 22 real-world dialogue tasks. To mitigate token explosion, our pilot studies reveal significant redundancy in RS images: crucial information is concentrated in a small subset of object-centric tokens, while pruning background tokens (e.g., ocean or forest) can even improve performance. Motivated by these findings, we propose two strategies: Background Token Pruning and Anchored Token Selection, to reduce the memory footprint while preserving key semantics.Integrating these techniques, we introduce GeoLLaVA-8K, the first RS-focused multimodal large language model capable of handling inputs up to 8K$\times$8K resolution, built on the LLaVA framework. Trained on SuperRS-VQA and HighRS-VQA, GeoLLaVA-8K sets a new state-of-the-art on the XLRS-Bench.
XLRS-Bench: Could Your Multimodal LLMs Understand Extremely Large Ultra-High-Resolution Remote Sensing Imagery?
Mar 31, 2025The astonishing breakthrough of multimodal large language models (MLLMs) has necessitated new benchmarks to quantitatively assess their capabilities, reveal their limitations, and indicate future research directions. However, this is challenging in the context of remote sensing (RS), since the imagery features ultra-high resolution that incorporates extremely complex semantic relationships. Existing benchmarks usually adopt notably smaller image sizes than real-world RS scenarios, suffer from limited annotation quality, and consider insufficient dimensions of evaluation. To address these issues, we present XLRS-Bench: a comprehensive benchmark for evaluating the perception and reasoning capabilities of MLLMs in ultra-high-resolution RS scenarios. XLRS-Bench boasts the largest average image size (8500$\times$8500) observed thus far, with all evaluation samples meticulously annotated manually, assisted by a novel semi-automatic captioner on ultra-high-resolution RS images. On top of the XLRS-Bench, 16 sub-tasks are defined to evaluate MLLMs' 10 kinds of perceptual capabilities and 6 kinds of reasoning capabilities, with a primary emphasis on advanced cognitive processes that facilitate real-world decision-making and the capture of spatiotemporal changes. The results of both general and RS-focused MLLMs on XLRS-Bench indicate that further efforts are needed for real-world RS applications. We have open-sourced XLRS-Bench to support further research in developing more powerful MLLMs for remote sensing.
RoMA: Scaling up Mamba-based Foundation Models for Remote Sensing
Mar 13, 2025Recent advances in self-supervised learning for Vision Transformers (ViTs) have fueled breakthroughs in remote sensing (RS) foundation models. However, the quadratic complexity of self-attention poses a significant barrier to scalability, particularly for large models and high-resolution images. While the linear-complexity Mamba architecture offers a promising alternative, existing RS applications of Mamba remain limited to supervised tasks on small, domain-specific datasets. To address these challenges, we propose RoMA, a framework that enables scalable self-supervised pretraining of Mamba-based RS foundation models using large-scale, diverse, unlabeled data. RoMA enhances scalability for high-resolution images through a tailored auto-regressive learning strategy, incorporating two key innovations: 1) a rotation-aware pretraining mechanism combining adaptive cropping with angular embeddings to handle sparsely distributed objects with arbitrary orientations, and 2) multi-scale token prediction objectives that address the extreme variations in object scales inherent to RS imagery. Systematic empirical studies validate that Mamba adheres to RS data and parameter scaling laws, with performance scaling reliably as model and data size increase. Furthermore, experiments across scene classification, object detection, and semantic segmentation tasks demonstrate that RoMA-pretrained Mamba models consistently outperform ViT-based counterparts in both accuracy and computational efficiency. The source code and pretrained models will be released at https://github.com/MiliLab/RoMA.
Scaling Efficient Masked Autoencoder Learning on Large Remote Sensing Dataset
Jun 17, 2024Masked Image Modeling (MIM) has emerged as a pivotal approach for developing foundational visual models in the field of remote sensing (RS). However, current RS datasets are limited in volume and diversity, which significantly constrains the capacity of MIM methods to learn generalizable representations. In this study, we introduce \textbf{RS-4M}, a large-scale dataset designed to enable highly efficient MIM training on RS images. RS-4M comprises 4 million optical images encompassing abundant and fine-grained RS visual tasks, including object-level detection and pixel-level segmentation. Compared to natural images, RS images often contain massive redundant background pixels, which limits the training efficiency of the conventional MIM models. To address this, we propose an efficient MIM method, termed \textbf{SelectiveMAE}, which dynamically encodes and reconstructs a subset of patch tokens selected based on their semantic richness. SelectiveMAE roots in a progressive semantic token selection module, which evolves from reconstructing semantically analogical tokens to encoding complementary semantic dependencies. This approach transforms conventional MIM training into a progressive feature learning process, enabling SelectiveMAE to efficiently learn robust representations of RS images. Extensive experiments show that SelectiveMAE significantly boosts training efficiency by 2.2-2.7 times and enhances the classification, detection, and segmentation performance of the baseline MIM model.The dataset, source code, and trained models will be released.
A Multi-oriented Chinese Keyword Spotter Guided by Text Line Detection
Jan 06, 2020
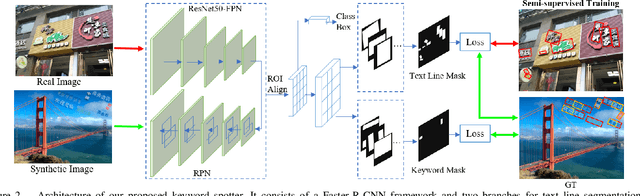

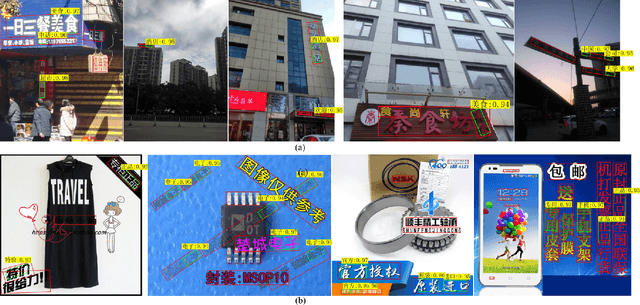
Chinese keyword spotting is a challenging task as there is no visual blank for Chinese words. Different from English words which are split naturally by visual blanks, Chinese words are generally split only by semantic information. In this paper, we propose a new Chinese keyword spotter for natural images, which is inspired by Mask R-CNN. We propose to predict the keyword masks guided by text line detection. Firstly, proposals of text lines are generated by Faster R-CNN;Then, text line masks and keyword masks are predicted by segmentation in the proposals. In this way, the text lines and keywords are predicted in parallel. We create two Chinese keyword datasets based on RCTW-17 and ICPR MTWI2018 to verify the effectiveness of our method.