 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJailbreaking Multimodal Large Language Models via Shuffle Inconsistency
Jan 09, 2025



Multimodal Large Language Models (MLLMs) have achieved impressive performance and have been put into practical use in commercial applications, but they still have potential safety mechanism vulnerabilities. Jailbreak attacks are red teaming methods that aim to bypass safety mechanisms and discover MLLMs' potential risks. Existing MLLMs' jailbreak methods often bypass the model's safety mechanism through complex optimization methods or carefully designed image and text prompts. Despite achieving some progress, they have a low attack success rate on commercial closed-source MLLMs. Unlike previous research, we empirically find that there exists a Shuffle Inconsistency between MLLMs' comprehension ability and safety ability for the shuffled harmful instruction. That is, from the perspective of comprehension ability, MLLMs can understand the shuffled harmful text-image instructions well. However, they can be easily bypassed by the shuffled harmful instructions from the perspective of safety ability, leading to harmful responses. Then we innovatively propose a text-image jailbreak attack named SI-Attack. Specifically, to fully utilize the Shuffle Inconsistency and overcome the shuffle randomness, we apply a query-based black-box optimization method to select the most harmful shuffled inputs based on the feedback of the toxic judge model. A series of experiments show that SI-Attack can improve the attack's performance on three benchmarks. In particular, SI-Attack can obviously improve the attack success rate for commercial MLLMs such as GPT-4o or Claude-3.5-Sonnet.
MRJ-Agent: An Effective Jailbreak Agent for Multi-Round Dialogue
Nov 06, 2024



Large Language Models (LLMs) demonstrate outstanding performance in their reservoir of knowledge and understanding capabilities, but they have also been shown to be prone to illegal or unethical reactions when subjected to jailbreak attacks. To ensure their responsible deployment in critical applications, it is crucial to understand the safety capabilities and vulnerabilities of LLMs. Previous works mainly focus on jailbreak in single-round dialogue, overlooking the potential jailbreak risks in multi-round dialogues, which are a vital way humans interact with and extract information from LLMs. Some studies have increasingly concentrated on the risks associated with jailbreak in multi-round dialogues. These efforts typically involve the use of manually crafted templates or prompt engineering techniques. However, due to the inherent complexity of multi-round dialogues, their jailbreak performance is limited. To solve this problem, we propose a novel multi-round dialogue jailbreaking agent, emphasizing the importance of stealthiness in identifying and mitigating potential threats to human values posed by LLMs. We propose a risk decomposition strategy that distributes risks across multiple rounds of queries and utilizes psychological strategies to enhance attack strength. Extensive experiments show that our proposed method surpasses other attack methods and achieves state-of-the-art attack success rate. We will make the corresponding code and dataset available for future research. The code will be released soon.
Model Inversion Attack via Dynamic Memory Learning
Aug 24, 2023
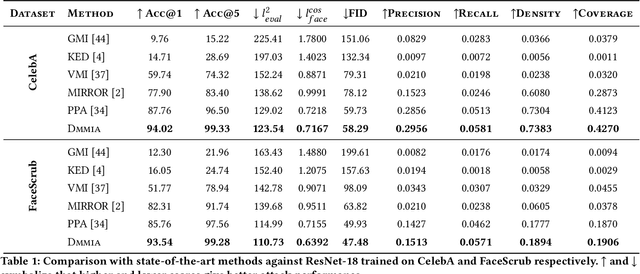
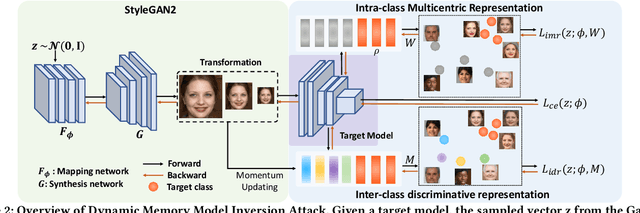
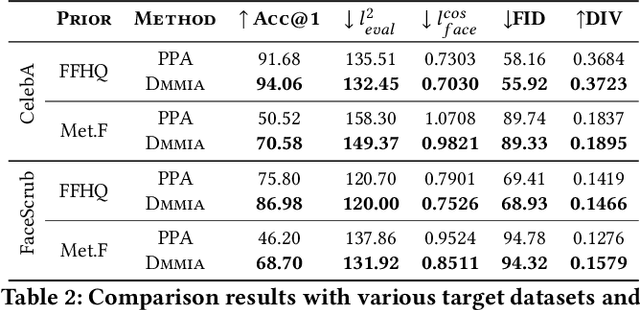
Model Inversion (MI) attacks aim to recover the private training data from the target model, which has raised security concerns about the deployment of DNNs in practice. Recent advances in generative adversarial models have rendered them particularly effective in MI attacks, primarily due to their ability to generate high-fidelity and perceptually realistic images that closely resemble the target data. In this work, we propose a novel Dynamic Memory Model Inversion Attack (DMMIA) to leverage historically learned knowledge, which interacts with samples (during the training) to induce diverse generations. DMMIA constructs two types of prototypes to inject the information about historically learned knowledge: Intra-class Multicentric Representation (IMR) representing target-related concepts by multiple learnable prototypes, and Inter-class Discriminative Representation (IDR) characterizing the memorized samples as learned prototypes to capture more privacy-related information. As a result, our DMMIA has a more informative representation, which brings more diverse and discriminative generated results. Experiments on multiple benchmarks show that DMMIA performs better than state-of-the-art MI attack methods.
Boosting Out-of-distribution Detection with Typical Features
Oct 09, 2022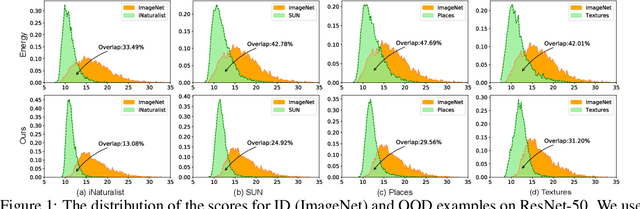
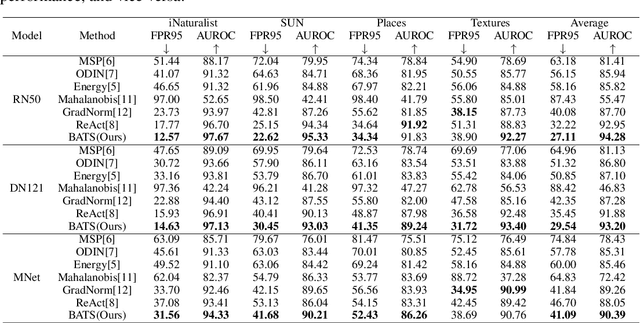

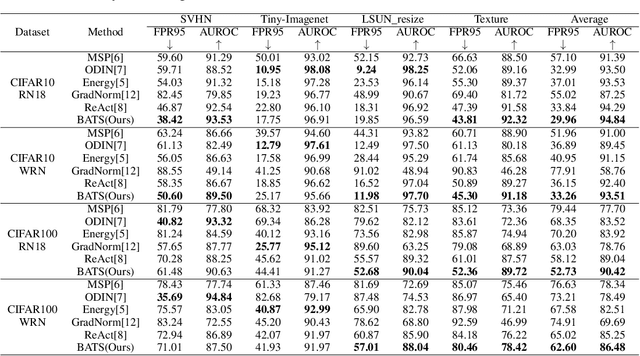
Out-of-distribution (OOD) detection is a critical task for ensuring the reliability and safety of deep neural networks in real-world scenarios. Different from most previous OOD detection methods that focus on designing OOD scores or introducing diverse outlier examples to retrain the model, we delve into the obstacle factors in OOD detection from the perspective of typicality and regard the feature's high-probability region of the deep model as the feature's typical set. We propose to rectify the feature into its typical set and calculate the OOD score with the typical features to achieve reliable uncertainty estimation. The feature rectification can be conducted as a {plug-and-play} module with various OOD scores. We evaluate the superiority of our method on both the commonly used benchmark (CIFAR) and the more challenging high-resolution benchmark with large label space (ImageNet). Notably, our approach outperforms state-of-the-art methods by up to 5.11$\%$ in the average FPR95 on the ImageNet benchmark.