 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComprehensive Evaluation and Analysis for NSFW Concept Erasure in Text-to-Image Diffusion Models
May 21, 2025Text-to-image diffusion models have gained widespread application across various domains, demonstrating remarkable creative potential. However, the strong generalization capabilities of diffusion models can inadvertently lead to the generation of not-safe-for-work (NSFW) content, posing significant risks to their safe deployment. While several concept erasure methods have been proposed to mitigate the issue associated with NSFW content, a comprehensive evaluation of their effectiveness across various scenarios remains absent. To bridge this gap, we introduce a full-pipeline toolkit specifically designed for concept erasure and conduct the first systematic study of NSFW concept erasure methods. By examining the interplay between the underlying mechanisms and empirical observations, we provide in-depth insights and practical guidance for the effective application of concept erasure methods in various real-world scenarios, with the aim of advancing the understanding of content safety in diffusion models and establishing a solid foundation for future research and development in this critical area.
Comprehensive Assessment and Analysis for NSFW Content Erasure in Text-to-Image Diffusion Models
Feb 18, 2025Text-to-image (T2I) diffusion models have gained widespread application across various domains, demonstrating remarkable creative potential. However, the strong generalization capabilities of these models can inadvertently led they to generate NSFW content even with efforts on filtering NSFW content from the training dataset, posing risks to their safe deployment. While several concept erasure methods have been proposed to mitigate this issue, a comprehensive evaluation of their effectiveness remains absent. To bridge this gap, we present the first systematic investigation of concept erasure methods for NSFW content and its sub-themes in text-to-image diffusion models. At the task level, we provide a holistic evaluation of 11 state-of-the-art baseline methods with 14 variants. Specifically, we analyze these methods from six distinct assessment perspectives, including three conventional perspectives, i.e., erasure proportion, image quality, and semantic alignment, and three new perspectives, i.e., excessive erasure, the impact of explicit and implicit unsafe prompts, and robustness. At the tool level, we perform a detailed toxicity analysis of NSFW datasets and compare the performance of different NSFW classifiers, offering deeper insights into their performance alongside a compilation of comprehensive evaluation metrics. Our benchmark not only systematically evaluates concept erasure methods, but also delves into the underlying factors influencing their performance at the insight level. By synthesizing insights from various evaluation perspectives, we provide a deeper understanding of the challenges and opportunities in the field, offering actionable guidance and inspiration for advancing research and practical applications in concept erasure.
Flatness-aware Adversarial Attack
Nov 10, 2023



The transferability of adversarial examples can be exploited to launch black-box attacks. However, adversarial examples often present poor transferability. To alleviate this issue, by observing that the diversity of inputs can boost transferability, input regularization based methods are proposed, which craft adversarial examples by combining several transformed inputs. We reveal that input regularization based methods make resultant adversarial examples biased towards flat extreme regions. Inspired by this, we propose an attack called flatness-aware adversarial attack (FAA) which explicitly adds a flatness-aware regularization term in the optimization target to promote the resultant adversarial examples towards flat extreme regions. The flatness-aware regularization term involves gradients of samples around the resultant adversarial examples but optimizing gradients requires the evaluation of Hessian matrix in high-dimension spaces which generally is intractable. To address the problem, we derive an approximate solution to circumvent the construction of Hessian matrix, thereby making FAA practical and cheap. Extensive experiments show the transferability of adversarial examples crafted by FAA can be considerably boosted compared with state-of-the-art baselines.
Model Inversion Attack via Dynamic Memory Learning
Aug 24, 2023
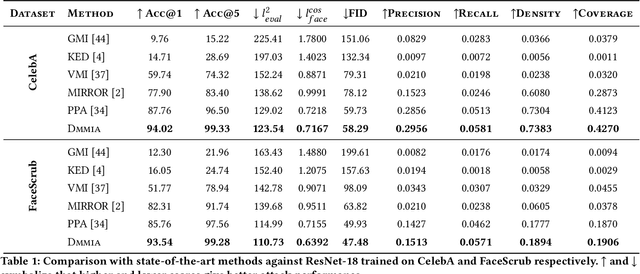
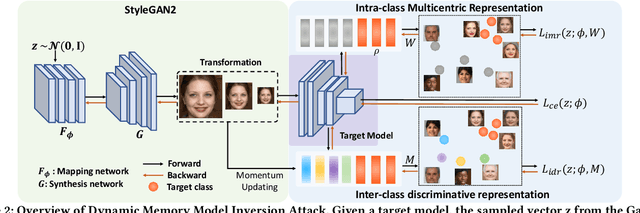
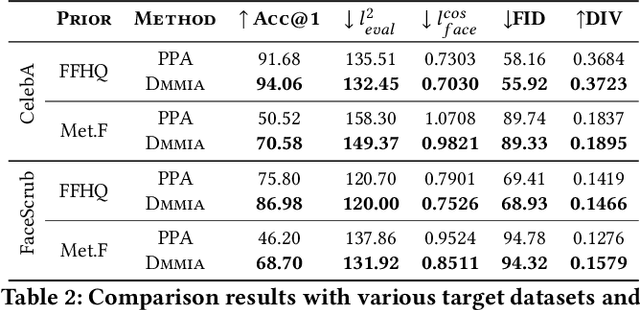
Model Inversion (MI) attacks aim to recover the private training data from the target model, which has raised security concerns about the deployment of DNNs in practice. Recent advances in generative adversarial models have rendered them particularly effective in MI attacks, primarily due to their ability to generate high-fidelity and perceptually realistic images that closely resemble the target data. In this work, we propose a novel Dynamic Memory Model Inversion Attack (DMMIA) to leverage historically learned knowledge, which interacts with samples (during the training) to induce diverse generations. DMMIA constructs two types of prototypes to inject the information about historically learned knowledge: Intra-class Multicentric Representation (IMR) representing target-related concepts by multiple learnable prototypes, and Inter-class Discriminative Representation (IDR) characterizing the memorized samples as learned prototypes to capture more privacy-related information. As a result, our DMMIA has a more informative representation, which brings more diverse and discriminative generated results. Experiments on multiple benchmarks show that DMMIA performs better than state-of-the-art MI attack methods.
ImageNet-E: Benchmarking Neural Network Robustness via Attribute Editing
Mar 30, 2023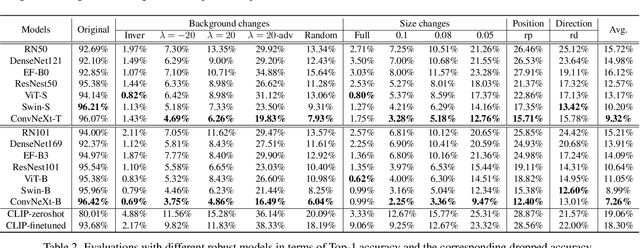
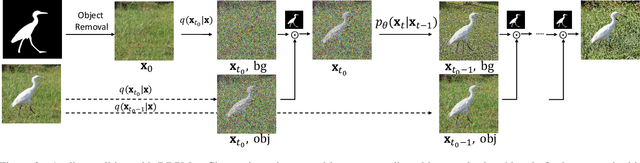

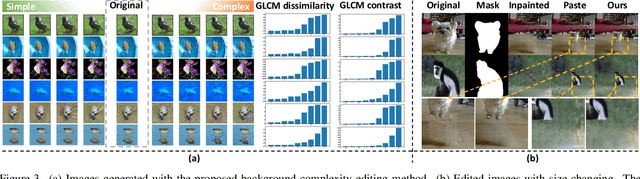
Recent studies have shown that higher accuracy on ImageNet usually leads to better robustness against different corruptions. Therefore, in this paper, instead of following the traditional research paradigm that investigates new out-of-distribution corruptions or perturbations deep models may encounter, we conduct model debugging in in-distribution data to explore which object attributes a model may be sensitive to. To achieve this goal, we create a toolkit for object editing with controls of backgrounds, sizes, positions, and directions, and create a rigorous benchmark named ImageNet-E(diting) for evaluating the image classifier robustness in terms of object attributes. With our ImageNet-E, we evaluate the performance of current deep learning models, including both convolutional neural networks and vision transformers. We find that most models are quite sensitive to attribute changes. A small change in the background can lead to an average of 9.23\% drop on top-1 accuracy. We also evaluate some robust models including both adversarially trained models and other robust trained models and find that some models show worse robustness against attribute changes than vanilla models. Based on these findings, we discover ways to enhance attribute robustness with preprocessing, architecture designs, and training strategies. We hope this work can provide some insights to the community and open up a new avenue for research in robust computer vision. The code and dataset are available at https://github.com/alibaba/easyrobust.
* Accepted by CVPR2023
TransAudio: Towards the Transferable Adversarial Audio Attack via Learning Contextualized Perturbations
Mar 28, 2023
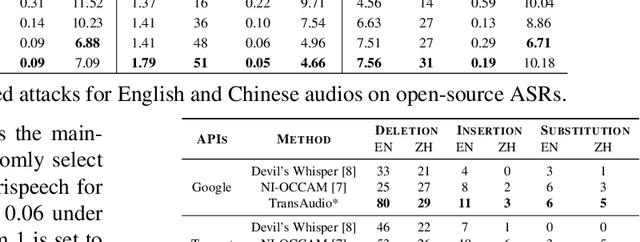

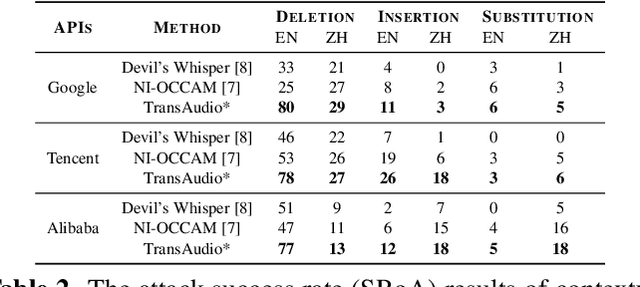
In a transfer-based attack against Automatic Speech Recognition (ASR) systems, attacks are unable to access the architecture and parameters of the target model. Existing attack methods are mostly investigated in voice assistant scenarios with restricted voice commands, prohibiting their applicability to more general ASR related applications. To tackle this challenge, we propose a novel contextualized attack with deletion, insertion, and substitution adversarial behaviors, namely TransAudio, which achieves arbitrary word-level attacks based on the proposed two-stage framework. To strengthen the attack transferability, we further introduce an audio score-matching optimization strategy to regularize the training process, which mitigates adversarial example over-fitting to the surrogate model. Extensive experiments and analysis demonstrate the effectiveness of TransAudio against open-source ASR models and commercial APIs.
Information-containing Adversarial Perturbation for Combating Facial Manipulation Systems
Mar 21, 2023



With the development of deep learning technology, the facial manipulation system has become powerful and easy to use. Such systems can modify the attributes of the given facial images, such as hair color, gender, and age. Malicious applications of such systems pose a serious threat to individuals' privacy and reputation. Existing studies have proposed various approaches to protect images against facial manipulations. Passive defense methods aim to detect whether the face is real or fake, which works for posterior forensics but can not prevent malicious manipulation. Initiative defense methods protect images upfront by injecting adversarial perturbations into images to disrupt facial manipulation systems but can not identify whether the image is fake. To address the limitation of existing methods, we propose a novel two-tier protection method named Information-containing Adversarial Perturbation (IAP), which provides more comprehensive protection for {facial images}. We use an encoder to map a facial image and its identity message to a cross-model adversarial example which can disrupt multiple facial manipulation systems to achieve initiative protection. Recovering the message in adversarial examples with a decoder serves passive protection, contributing to provenance tracking and fake image detection. We introduce a feature-level correlation measurement that is more suitable to measure the difference between the facial images than the commonly used mean squared error. Moreover, we propose a spectral diffusion method to spread messages to different frequency channels, thereby improving the robustness of the message against facial manipulation. Extensive experimental results demonstrate that our proposed IAP can recover the messages from the adversarial examples with high average accuracy and effectively disrupt the facial manipulation systems.
Rethinking Out-of-Distribution Detection From a Human-Centric Perspective
Nov 30, 2022



Out-Of-Distribution (OOD) detection has received broad attention over the years, aiming to ensure the reliability and safety of deep neural networks (DNNs) in real-world scenarios by rejecting incorrect predictions. However, we notice a discrepancy between the conventional evaluation vs. the essential purpose of OOD detection. On the one hand, the conventional evaluation exclusively considers risks caused by label-space distribution shifts while ignoring the risks from input-space distribution shifts. On the other hand, the conventional evaluation reward detection methods for not rejecting the misclassified image in the validation dataset. However, the misclassified image can also cause risks and should be rejected. We appeal to rethink OOD detection from a human-centric perspective, that a proper detection method should reject the case that the deep model's prediction mismatches the human expectations and adopt the case that the deep model's prediction meets the human expectations. We propose a human-centric evaluation and conduct extensive experiments on 45 classifiers and 8 test datasets. We find that the simple baseline OOD detection method can achieve comparable and even better performance than the recently proposed methods, which means that the development in OOD detection in the past years may be overestimated. Additionally, our experiments demonstrate that model selection is non-trivial for OOD detection and should be considered as an integral of the proposed method, which differs from the claim in existing works that proposed methods are universal across different models.
Towards Understanding and Boosting Adversarial Transferability from a Distribution Perspective
Oct 09, 2022
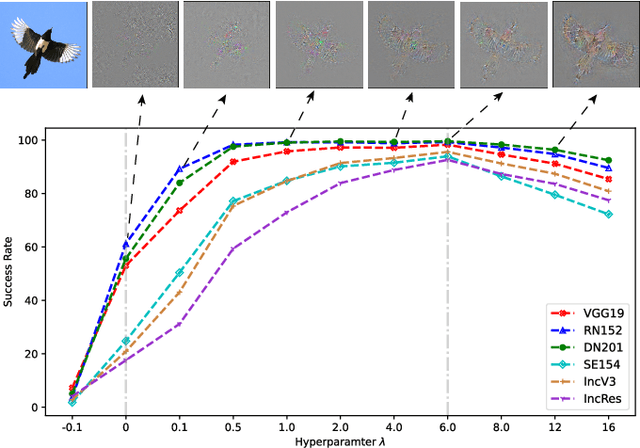
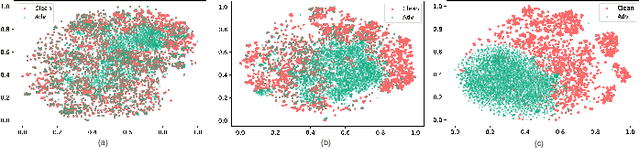
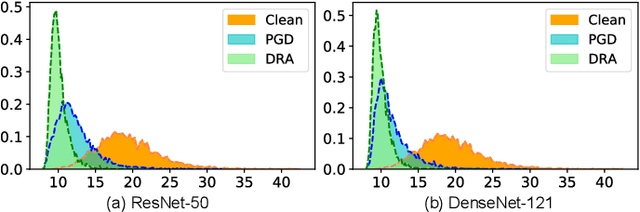
Transferable adversarial attacks against Deep neural networks (DNNs) have received broad attention in recent years. An adversarial example can be crafted by a surrogate model and then attack the unknown target model successfully, which brings a severe threat to DNNs. The exact underlying reasons for the transferability are still not completely understood. Previous work mostly explores the causes from the model perspective, e.g., decision boundary, model architecture, and model capacity. adversarial attacks against Deep neural networks (DNNs) have received broad attention in recent years. An adversarial example can be crafted by a surrogate model and then attack the unknown target model successfully, which brings a severe threat to DNNs. The exact underlying reasons for the transferability are still not completely understood. Previous work mostly explores the causes from the model perspective. Here, we investigate the transferability from the data distribution perspective and hypothesize that pushing the image away from its original distribution can enhance the adversarial transferability. To be specific, moving the image out of its original distribution makes different models hardly classify the image correctly, which benefits the untargeted attack, and dragging the image into the target distribution misleads the models to classify the image as the target class, which benefits the targeted attack. Towards this end, we propose a novel method that crafts adversarial examples by manipulating the distribution of the image. We conduct comprehensive transferable attacks against multiple DNNs to demonstrate the effectiveness of the proposed method. Our method can significantly improve the transferability of the crafted attacks and achieves state-of-the-art performance in both untargeted and targeted scenarios, surpassing the previous best method by up to 40$\%$ in some cases.
Boosting Out-of-distribution Detection with Typical Features
Oct 09, 2022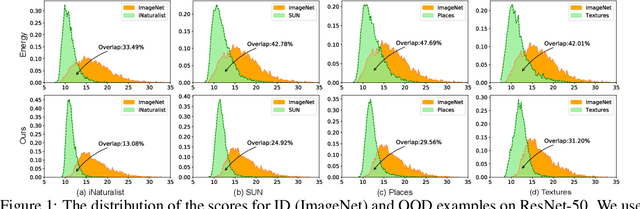
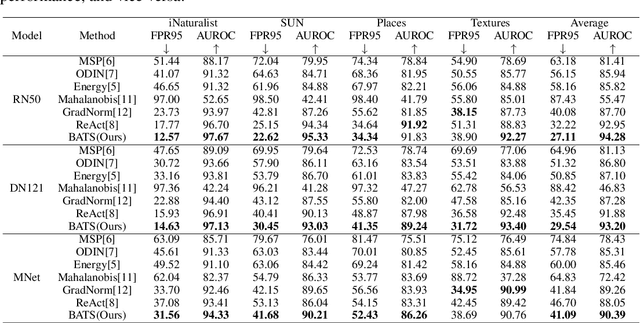

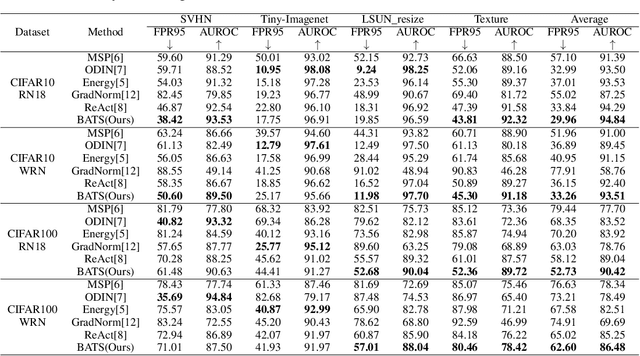
Out-of-distribution (OOD) detection is a critical task for ensuring the reliability and safety of deep neural networks in real-world scenarios. Different from most previous OOD detection methods that focus on designing OOD scores or introducing diverse outlier examples to retrain the model, we delve into the obstacle factors in OOD detection from the perspective of typicality and regard the feature's high-probability region of the deep model as the feature's typical set. We propose to rectify the feature into its typical set and calculate the OOD score with the typical features to achieve reliable uncertainty estimation. The feature rectification can be conducted as a {plug-and-play} module with various OOD scores. We evaluate the superiority of our method on both the commonly used benchmark (CIFAR) and the more challenging high-resolution benchmark with large label space (ImageNet). Notably, our approach outperforms state-of-the-art methods by up to 5.11$\%$ in the average FPR95 on the ImageNet benchmark.