 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransAudio: Towards the Transferable Adversarial Audio Attack via Learning Contextualized Perturbations
Mar 28, 2023
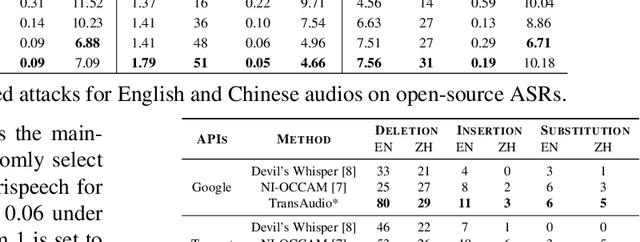

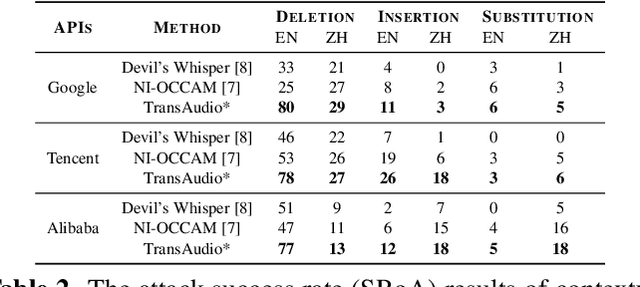
In a transfer-based attack against Automatic Speech Recognition (ASR) systems, attacks are unable to access the architecture and parameters of the target model. Existing attack methods are mostly investigated in voice assistant scenarios with restricted voice commands, prohibiting their applicability to more general ASR related applications. To tackle this challenge, we propose a novel contextualized attack with deletion, insertion, and substitution adversarial behaviors, namely TransAudio, which achieves arbitrary word-level attacks based on the proposed two-stage framework. To strengthen the attack transferability, we further introduce an audio score-matching optimization strategy to regularize the training process, which mitigates adversarial example over-fitting to the surrogate model. Extensive experiments and analysis demonstrate the effectiveness of TransAudio against open-source ASR models and commercial APIs.