 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWXSOD: A Benchmark for Robust Salient Object Detection in Adverse Weather Conditions
Aug 17, 2025Salient object detection (SOD) in complex environments remains a challenging research topic. Most existing methods perform well in natural scenes with negligible noise, and tend to leverage multi-modal information (e.g., depth and infrared) to enhance accuracy. However, few studies are concerned with the damage of weather noise on SOD performance due to the lack of dataset with pixel-wise annotations. To bridge this gap, this paper introduces a novel Weather-eXtended Salient Object Detection (WXSOD) dataset. It consists of 14,945 RGB images with diverse weather noise, along with the corresponding ground truth annotations and weather labels. To verify algorithm generalization, WXSOD contains two test sets, i.e., a synthesized test set and a real test set. The former is generated by adding weather noise to clean images, while the latter contains real-world weather noise. Based on WXSOD, we propose an efficient baseline, termed Weather-aware Feature Aggregation Network (WFANet), which adopts a fully supervised two-branch architecture. Specifically, the weather prediction branch mines weather-related deep features, while the saliency detection branch fuses semantic features extracted from the backbone with weather features for SOD. Comprehensive comparisons against 17 SOD methods shows that our WFANet achieves superior performance on WXSOD. The code and benchmark results will be made publicly available at https://github.com/C-water/WXSOD
Capturing Stable HDR Videos Using a Dual-Camera System
Jul 09, 2025In HDR video reconstruction, exposure fluctuations in reference images from alternating exposure methods often result in flickering. To address this issue, we propose a dual-camera system (DCS) for HDR video acquisition, where one camera is assigned to capture consistent reference sequences, while the other is assigned to capture non-reference sequences for information supplementation. To tackle the challenges posed by video data, we introduce an exposure-adaptive fusion network (EAFNet) to achieve more robust results. EAFNet introduced a pre-alignment subnetwork to explore the influence of exposure, selectively emphasizing the valuable features across different exposure levels. Then, the enhanced features are fused by the asymmetric cross-feature fusion subnetwork, which explores reference-dominated attention maps to improve image fusion by aligning cross-scale features and performing cross-feature fusion. Finally, the reconstruction subnetwork adopts a DWT-based multiscale architecture to reduce ghosting artifacts and refine features at different resolutions. Extensive experimental evaluations demonstrate that the proposed method achieves state-of-the-art performance on different datasets, validating the great potential of the DCS in HDR video reconstruction. The codes and data captured by DCS will be available at https://github.com/zqqqyu/DCS.
Progressive Inertial Poser: Progressive Real-Time Kinematic Chain Estimation for 3D Full-Body Pose from Three IMU Sensors
May 08, 2025The motion capture system that supports full-body virtual representation is of key significance for virtual reality. Compared to vision-based systems, full-body pose estimation from sparse tracking signals is not limited by environmental conditions or recording range. However, previous works either face the challenge of wearing additional sensors on the pelvis and lower-body or rely on external visual sensors to obtain global positions of key joints. To improve the practicality of the technology for virtual reality applications, we estimate full-body poses using only inertial data obtained from three Inertial Measurement Unit (IMU) sensors worn on the head and wrists, thereby reducing the complexity of the hardware system. In this work, we propose a method called Progressive Inertial Poser (ProgIP) for human pose estimation, which combines neural network estimation with a human dynamics model, considers the hierarchical structure of the kinematic chain, and employs a multi-stage progressive network estimation with increased depth to reconstruct full-body motion in real time. The encoder combines Transformer Encoder and bidirectional LSTM (TE-biLSTM) to flexibly capture the temporal dependencies of the inertial sequence, while the decoder based on multi-layer perceptrons (MLPs) transforms high-dimensional features and accurately projects them onto Skinned Multi-Person Linear (SMPL) model parameters. Quantitative and qualitative experimental results on multiple public datasets show that our method outperforms state-of-the-art methods with the same inputs, and is comparable to recent works using six IMU sensors.
Relative Distance Guided Dynamic Partition Learning for Scale-Invariant UAV-View Geo-Localization
Dec 23, 2024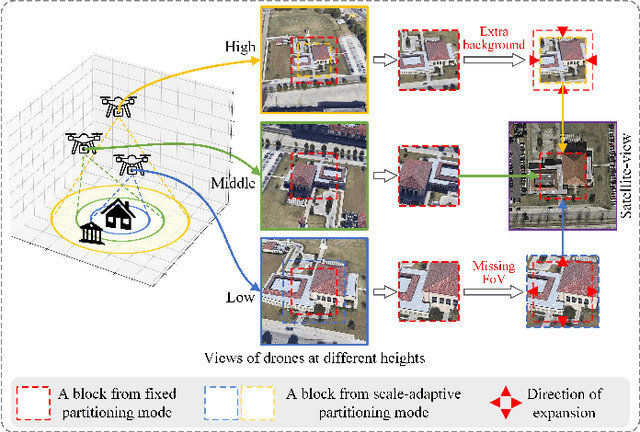
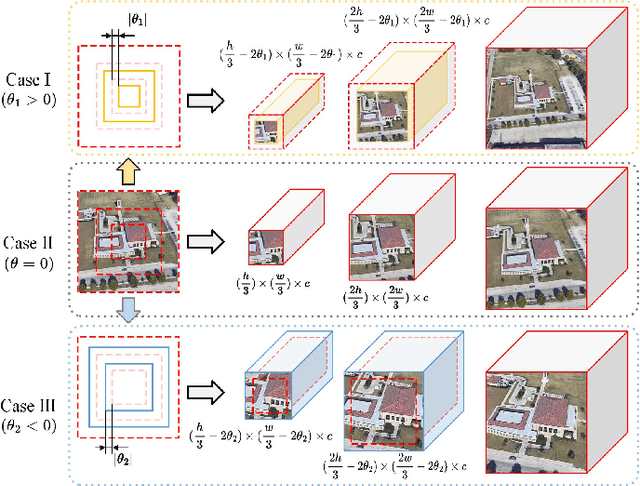
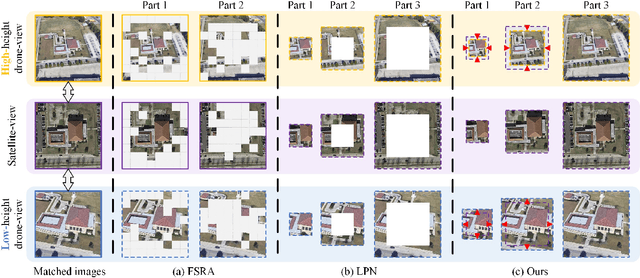
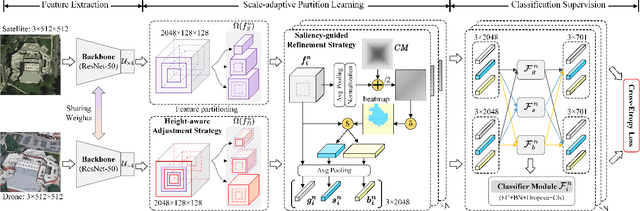
UAV-view Geo-Localization~(UVGL) presents substantial challenges, particularly due to the disparity in visual appearance between drone-captured imagery and satellite perspectives. Existing methods usually assume consistent scaling factor across different views. Therefore, they adopt predefined partition alignment and extract viewpoint-invariant representation by constructing a variety of part-level features. However, the scaling assumption is not always hold in the real-world scenarios that variations of UAV flight state leads to the scale mismatch of cross-views, resulting in serious performance degradation. To overcome this issue, we propose a partition learning framework based on relative distance, which alleviates the dependence on scale consistency while mining fine-grained features. Specifically, we propose a distance guided dynamic partition learning strategy~(DGDPL), consisting of a square partition strategy and a distance-guided adjustment strategy. The former is utilized to extract fine-grained features and global features in a simple manner. The latter calculates the relative distance ratio between drone- and satellite-view to adjust the partition size, thereby explicitly aligning the semantic information between partition pairs. Furthermore, we propose a saliency-guided refinement strategy to refine part-level features, so as to further improve the retrieval accuracy. Extensive experiments show that our approach achieves superior geo-localization accuracy across various scale-inconsistent scenarios, and exhibits remarkable robustness against scale variations. The code will be released.
Near Large Far Small: Relative Distance Based Partition Learning for UAV-view Geo-Localization
Dec 16, 2024UAV-view Geo-Localization (UVGL) presents substantial challenges, primarily due to appearance differences between drone-view and satellite-view. Existing methods develop partition learning strategies aimed at mining more comprehensive information by constructing diverse part-level feature representations, which rely on consistent cross-view scales. However, variations of UAV flight state leads to the scale mismatch of cross-views, resulting in serious performance degradation of partition-based methods. To overcome this issue, we propose a partition learning framework based on relative distance, which alleviates the dependence on scale consistency while mining fine-grained features. Specifically, we propose a distance guided dynamic partition learning strategy (DGDPL), consisting of a square partition strategy and a dynamic-guided adjustment strategy. The former is utilized to extract fine-grained features and global features in a simple manner. The latter calculates the relative distance ratio between drone- and satellite-view to adjust the partition size, thereby aligning the semantic information between partition pairs. Furthermore, we propose a saliency-guided refinement strategy to refine part-level features, so as to further improve the retrieval accuracy. Extensive experiments show that our approach achieves superior geo-localization accuracy across various scale-inconsistent scenarios, and exhibits remarkable robustness against scale variations. The code will be released.
Infrared Small Target Detection with Scale and Location Sensitivity
Mar 28, 2024



Recently, infrared small target detection (IRSTD) has been dominated by deep-learning-based methods. However, these methods mainly focus on the design of complex model structures to extract discriminative features, leaving the loss functions for IRSTD under-explored. For example, the widely used Intersection over Union (IoU) and Dice losses lack sensitivity to the scales and locations of targets, limiting the detection performance of detectors. In this paper, we focus on boosting detection performance with a more effective loss but a simpler model structure. Specifically, we first propose a novel Scale and Location Sensitive (SLS) loss to handle the limitations of existing losses: 1) for scale sensitivity, we compute a weight for the IoU loss based on target scales to help the detector distinguish targets with different scales: 2) for location sensitivity, we introduce a penalty term based on the center points of targets to help the detector localize targets more precisely. Then, we design a simple Multi-Scale Head to the plain U-Net (MSHNet). By applying SLS loss to each scale of the predictions, our MSHNet outperforms existing state-of-the-art methods by a large margin. In addition, the detection performance of existing detectors can be further improved when trained with our SLS loss, demonstrating the effectiveness and generalization of our SLS loss. The code is available at https://github.com/ying-fu/MSHNet.
Hierarchical Frequency-based Upsampling and Refining for Compressed Video Quality Enhancement
Mar 18, 2024



Video compression artifacts arise due to the quantization operation in the frequency domain. The goal of video quality enhancement is to reduce compression artifacts and reconstruct a visually-pleasant result. In this work, we propose a hierarchical frequency-based upsampling and refining neural network (HFUR) for compressed video quality enhancement. HFUR consists of two modules: implicit frequency upsampling module (ImpFreqUp) and hierarchical and iterative refinement module (HIR). ImpFreqUp exploits DCT-domain prior derived through implicit DCT transform, and accurately reconstructs the DCT-domain loss via a coarse-to-fine transfer. Consequently, HIR is introduced to facilitate cross-collaboration and information compensation between the scales, thus further refine the feature maps and promote the visual quality of the final output. We demonstrate the effectiveness of the proposed modules via ablation experiments and visualized results. Extensive experiments on public benchmarks show that HFUR achieves state-of-the-art performance for both constant bit rate and constant QP modes.
SDPL: Shifting-Dense Partition Learning for UAV-View Geo-Localization
Mar 07, 2024



Cross-view geo-localization aims to match images of the same target from different platforms, e.g., drone and satellite. It is a challenging task due to the changing both appearance of targets and environmental content from different views. Existing methods mainly focus on digging more comprehensive information through feature maps segmentation, while inevitably destroy the image structure and are sensitive to the shifting and scale of the target in the query. To address the above issues, we introduce a simple yet effective part-based representation learning, called shifting-dense partition learning (SDPL). Specifically, we propose the dense partition strategy (DPS), which divides the image into multiple parts to explore contextual-information while explicitly maintain the global structure. To handle scenarios with non-centered targets, we further propose the shifting-fusion strategy, which generates multiple sets of parts in parallel based on various segmentation centers and then adaptively fuses all features to select the best partitions. Extensive experiments show that our SDPL is robust to position shifting and scale variations, and achieves competitive performance on two prevailing benchmarks, i.e., University-1652 and SUES-200.
Information-containing Adversarial Perturbation for Combating Facial Manipulation Systems
Mar 21, 2023



With the development of deep learning technology, the facial manipulation system has become powerful and easy to use. Such systems can modify the attributes of the given facial images, such as hair color, gender, and age. Malicious applications of such systems pose a serious threat to individuals' privacy and reputation. Existing studies have proposed various approaches to protect images against facial manipulations. Passive defense methods aim to detect whether the face is real or fake, which works for posterior forensics but can not prevent malicious manipulation. Initiative defense methods protect images upfront by injecting adversarial perturbations into images to disrupt facial manipulation systems but can not identify whether the image is fake. To address the limitation of existing methods, we propose a novel two-tier protection method named Information-containing Adversarial Perturbation (IAP), which provides more comprehensive protection for {facial images}. We use an encoder to map a facial image and its identity message to a cross-model adversarial example which can disrupt multiple facial manipulation systems to achieve initiative protection. Recovering the message in adversarial examples with a decoder serves passive protection, contributing to provenance tracking and fake image detection. We introduce a feature-level correlation measurement that is more suitable to measure the difference between the facial images than the commonly used mean squared error. Moreover, we propose a spectral diffusion method to spread messages to different frequency channels, thereby improving the robustness of the message against facial manipulation. Extensive experimental results demonstrate that our proposed IAP can recover the messages from the adversarial examples with high average accuracy and effectively disrupt the facial manipulation systems.
Rethinking Out-of-Distribution Detection From a Human-Centric Perspective
Nov 30, 2022



Out-Of-Distribution (OOD) detection has received broad attention over the years, aiming to ensure the reliability and safety of deep neural networks (DNNs) in real-world scenarios by rejecting incorrect predictions. However, we notice a discrepancy between the conventional evaluation vs. the essential purpose of OOD detection. On the one hand, the conventional evaluation exclusively considers risks caused by label-space distribution shifts while ignoring the risks from input-space distribution shifts. On the other hand, the conventional evaluation reward detection methods for not rejecting the misclassified image in the validation dataset. However, the misclassified image can also cause risks and should be rejected. We appeal to rethink OOD detection from a human-centric perspective, that a proper detection method should reject the case that the deep model's prediction mismatches the human expectations and adopt the case that the deep model's prediction meets the human expectations. We propose a human-centric evaluation and conduct extensive experiments on 45 classifiers and 8 test datasets. We find that the simple baseline OOD detection method can achieve comparable and even better performance than the recently proposed methods, which means that the development in OOD detection in the past years may be overestimated. Additionally, our experiments demonstrate that model selection is non-trivial for OOD detection and should be considered as an integral of the proposed method, which differs from the claim in existing works that proposed methods are universal across different models.